【泡泡一分钟】学习行人如何导航:一种深度逆强化学习的方法
每天一分钟,带你读遍机器人顶级会议文章
标题:Learning How Pedestrians Navigate: A Deep Inverse Reinforcement Learning Approach
作者:Muhammad Fahad, Zhuo Chen, and Yi Guo
来源:2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
编译:明煜航
审核:颜青松,陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

人类和移动机器人将会更多的生活在同一个环境之中,这种趋势导致了越来越多关于人机交互的研究(HRI)。这其中一个重要的话题就是研究发展在同一个地方社会意义上符合人类导航要求的机器人导航算法。
本文中,作者提出了一种使用最大熵深度逆强化学习(maximum entropy deep inverse reinforcement learning [MEDIRL])来学习人类导航行为的方法。作者使用了一个在不受控的环境下收集的大型公开的行人轨迹数据集来作为专家演示。人类的导航行为由一个通过深度神经网络(DNN)估计的非线性奖励函数来获取。已经开发好的MEDIRL算法用从人类运动轨迹中提取出的包括社会亲和图(social affinity map [SAM])在内的特征作为输入。

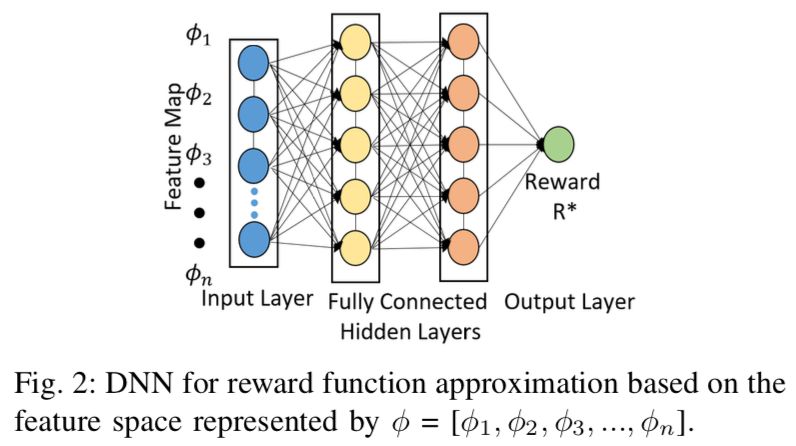
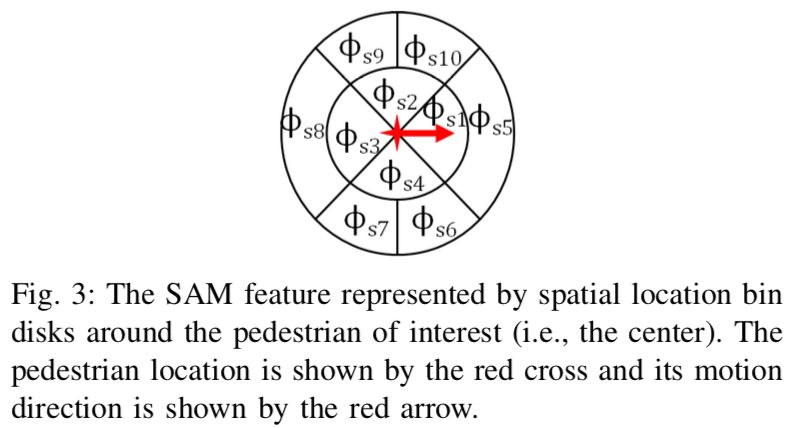
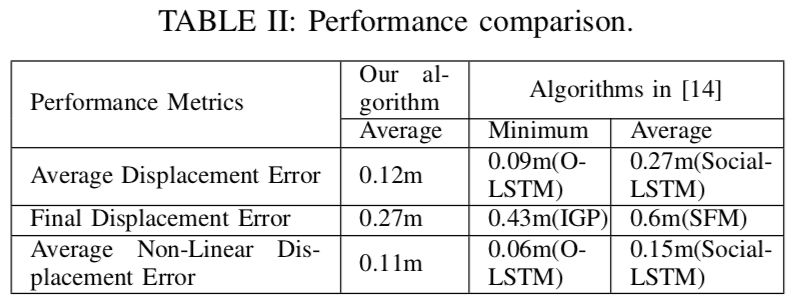
作者使用学习到的奖励函数进行了模拟实验,并通过与数据集中真实测量的行人轨迹对比来评估其性能。评估结果显示作者提出的方法在与其他最先进的方法对比中有着可以接受的预测精度,并且可以生成与人类轨迹相似,有着例如防碰撞、领导与跟随、分来与汇合等自然社会导航行为的行人轨迹。


Abstract
Humans and mobile robots will be increasingly cohabiting in the same environments, which has lead to an increase in studies on human robot interaction (HRI). One important topic in these studies is the development of robot navigation algorithms that are socially compliant to humans navigating in the same space. In this paper, we present a method to learn human navigation behaviors using maximum entropy deep inverse reinforcement learning (MEDIRL). We use a large open dataset of pedestrian trajectories collected in an uncontrolled environment as the expert demonstrations. Human navigation behaviors are captured by a nonlinear reward function through deep neural network (DNN) approximation. The developed MEDIRL algorithm takes feature inputs including social affinity map (SAM) that are extracted from human motion trajectories. We perform simulation experiments using the learned reward function, and the performance is evaluated comparing it with the real measured pedestrian trajectories in the dataset. The evaluation results show that the proposed method has acceptable prediction accuracy compared to other state-of-the-art methods, and it can generate pedestrian trajectories similar to real human trajectories with natural social navigation behaviors such as collision avoidance, leader- follower, and split-and-rejoin.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




