当推荐系统遇上对比学习, 谷歌SSL算法精读
0 导读
深度学习巨头Yoshua Bengio和Yann LeCun都曾说过Self-Supervised Learning(SSL,自监督学习) 是 AI 的未来,对比学习作为自监督学的重要代表,已经火遍了机器学习的多个领域。尤其在CV领域,对比学习可以说是最火的方向之一,先后涌现出了MoCov1、SimCLRv1、MoCov2、SimCLRv2、SWaV、BYOL、SimSiam、MoCov3、DINO等多篇佳作。推荐领域关于对比学习的研究也在逐渐增加,本文着重介绍在推荐领域应用对比学习比较成功且比较出名的paper:《Self-supervised Learning for Large-scale Item Recommendations》,作者均来自谷歌团队。关于什么是对比学习,请参考文章WWW2022@教程 | 基于对比学习的推荐系统。
1 问题
本文的应用场景是什么?本文的应用场景是推荐召回场景,即在给定一个query的情况下,从海量的候选item中找到与query最相关的topN个item,根据query的类型不同,推荐任务也就不同:(1)当query是一个user时,这就是个性化推荐u2i问题;2)当query是一个item时,这就是一个i2i推荐;(3)当query是一个文本时,这就是一个搜索问题。一般解决query2item的问题会使用很受欢迎的双塔DNN模型结构[1],如下图Figure1所示,这种结构会通过有监督学习,将item编码成embedding并进行离线存储,线上服务时,query实时计算得到,query和离线存储的item的embedding进行相似度计算从而找到top-N的item。本文的模型结构基于双塔DNN,给出了解决query2item的一个普适性方案。
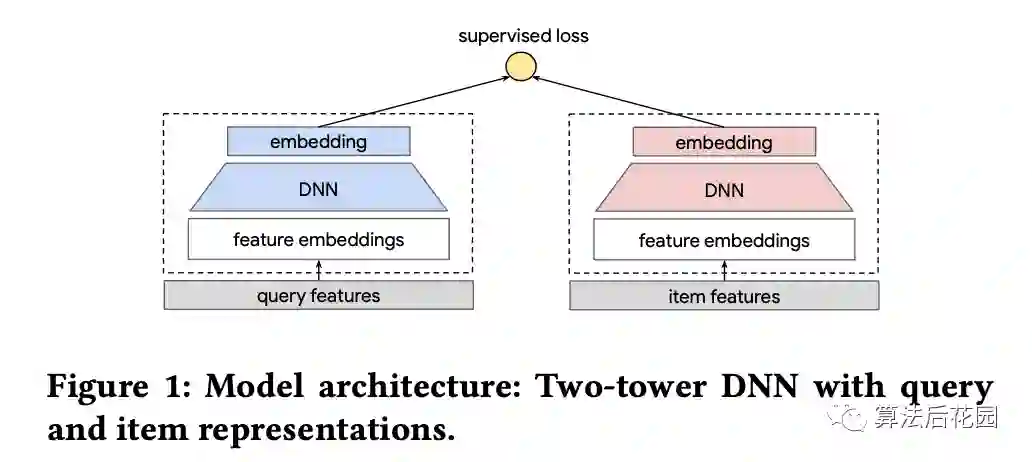
本文解决的是推荐里的什么问题?本文解决的是推荐系统中常见的长尾item问题。在大规模推荐系统中,用户行为的数据量非常大,为构建深度模型提供了大量的训练数据。但即便这样,由于两方面原因,数据仍然很稀疏:(1)高度倾斜的数据分布。query和item之间的交互数据分布通常是高度倾斜的,一小部分高热度的item会贡献大多数的交互数据,这将使得长尾item的训练数据非常稀疏。(2)缺少明确的用户反馈。用户经常明确地提供很多正向的反馈例如点击和点赞,然而,他们不太可能提供如评分、用户满意度反馈和相关性得分这样的反馈(这里指的是基于喜欢和不喜欢之间的程度的反馈)。
2 方法
针对上述的长尾分布和稀疏数据问题,本文使用多任务训练策略,其中主任务是有监督任务,SSL任务(即自监督学习任务)是辅助任务,SSL任务是本文的核心亮点,主任务和辅助任务联合优化。
主任务与SSL辅助任务的样本如何构建?假设当query是一个user时,这就是一个u2i问题,主任务的样本构建参考传统双塔的u2i样本构造方法。辅助任务的样本构建是本文的亮点,主要是通过对item进行数据增强来构建样本,详情在2.1SSL框架和2.2两阶段数据增强方法中介绍。
主任务与SSL辅助任务的损失函数分别是什么?主任务的损失函数采用的是batch softmax loss,详情见2.3。辅助任务的损失函数也称对比损失或SSL损失,采用的是infoNCE loss,详情见2.1。
下面先通过2.1介绍辅助任务的SSL框架(即自监督学习框架),再通过2.2介绍SSL框架中提到的数据增强方法,最后通过2.3来交代主任务和辅助任务的联合训练。
2.1 SSL框架
本文提出了使用基于自监督学习(Self-supervised Learning,简称SSL)的辅助任务来提升item的表征。与CV和NLU不同,推荐模型的输入空间是非常稀疏的,常常有量级很大的类别型特征,例如item id。针对这样的情况,本文提出了一个新的SSL框架,其核心思想是:(1)通过masking输入信息来增强数据;(2)使用双塔DNN模型对增强的正样本对进行编码;(3)使用对比学习loss来对增强的数据进行表征学习。对比学习的目标是使得从同一个样本增强出的样本对与其它样本区别开。值得注意的是,用于辅助任务的对比学习双塔DNN和用于编码query和item的主任务双塔DNN是共享一部分模型参数的。
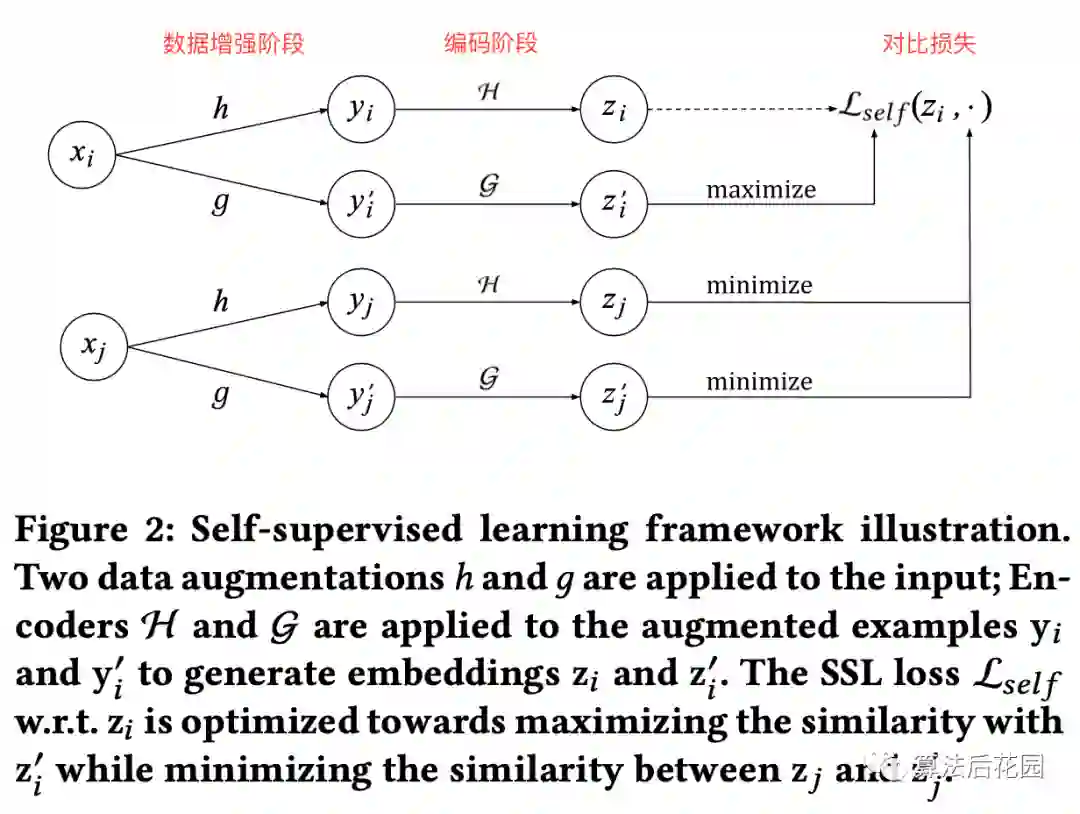
上图是SSL框架图,该框架主要还是借鉴了CV领域的SimCLR框架[2],看懂了上面这张图,也就真正掌握了SSL框架的精髓。上述框架主要包含三部分:(1)数据增强阶段;(2)编码阶段;(3)对比损失。 代表 个item样本, 是数据增强函数, 分别对 增强得到 , 是编码器,也就是双塔模型中的全连接, 与 分别通过全连接层 得到 与 。我们将 看做是正样本对, 看做是负样本对, 。SSL损失定义如下:
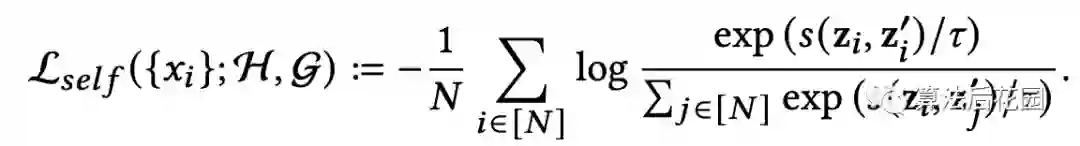
其中, 是cosin距离, 代表的是一个batch里的样本个数, 是温度系数,是一个超参数。上述损失函数可以学习到一个鲁棒的embedding空间,给定同样的item输入样本 ,我们想去学习增强后的 和 的不同表征,以此确保模型仍然可以识别出 和 代表同一个输入 ,换句话说,对比loss是用来最小化 与 的不同,最大化 和 的相似性。同时,对于不同的样本 与 ,数据增强后得到 和 的表征,对比loss要最大化 与 表征的不同(也要最大化 与 表征的不同),最小化 和 的相似性(也要最小化 和 的相似性)。
以上就是SSL框架的总体介绍,下面再交代一个细节。
Encoder的结构( 的结构)。对于具有类别型特征的输入样本, 结构是由输入层和MLP构成的,输入层将归一化后的dense特征和多个类别型特征的embedding进行拼接,其中,embedding是类别型特征学习到的表征,存储在embedding词表中。为了使SSL可以促进有监督学习的任务, 和 的类别型特征对应的embedding是共享的。根据数据增强方法 的不同, 和 的MLP也可以是完全共享或部分共享。
2.2 两阶段数据增强方法
这部分重点说明一下2.1框架中的数据增强方法 。数据增强的核心思想是:在给定item特征集合的情况下,通过mask掉部分信息来产生两个增强样本。在深入说明masking细节之前,本文首先提出了两阶段增强算法。说明一下,在没有使用数据增强的时候,输入层(input layer)的操作是将所有类别型的embedding进行拼接。两阶段数据增强方法包括:
-
Masking 在item特征集合上使用masking方法,在输入层(input layer)使用默认的embedding来代表mask掉的特征。 -
Dropout 对于具有多个值的类别型特征,我们对每个值以一定概率进行丢弃操作,这就进一步减少了输入信息从而增加了SSL任务的难度。
上述的masking操作可以认为是dropout的一种特殊情况,即当以100%概率进行dropout操作的时候就是masking了。mask的思路来源于Bert里的mask思想,与语言模型里有顺序的token不同,一般推荐模型里很多特征是没有顺序的,这使得在推荐里,mask的模式是一个悬而未决的问题,本文尝试探索特征的相关性来构建mask模式,提出CFM(Correlated Feature Masking),专门针对类别型特征。
为什么使用特征相关性来构建mask模式?如何定义特征相关性?本文的数据增强思想框架下有一种最简单的策略可以作为baseline,这种策略是互补的masking模式,即将某个样本的整个特征集合随机切分成两个独立的不相交的特征集合,这两个特征集合对应的样本就是数据增强后的两个样本。但是这种方法有很大的问题,当整个特征集合有 个特征的话, 的候选集合一共有 个不同的masking模式。不同的masking模式自然会对SSL任务产生不同的影响。举例来说,SSL对比学习任务可能会利用两个增强样本之间高度相关的特征的捷径,从而使得SSL任务变得过于简单。为了解决这种问题,本文提出通过互信息来计算特征相关性,从而根据特征相关性对特征集合进行切分。两个类别型特征的互信息定义如下:
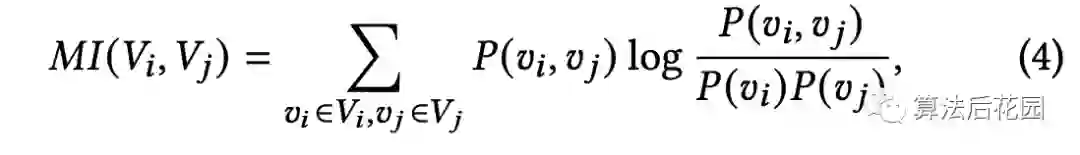
其中, 分别代表特征 和特征 所包含的值的集合,所有特征对的互信息都可以被提前计算出来。
CFM(Correlated Feature Masking)。有了提前计算好的互信息,本文提出了CFM,对于一组被mask掉的特征 ,我们试图将与其高度相关的特征也一起mask掉。具体来说,我们首先从所有可选的特征 中均匀采样得到种子特征 ,然后通过互信息找到与种子特征 最相关的top-n个特征 ,最终的 是种子特征和相关特征集合的并集,也就是。我们选取 ,那么被mask掉的特征和被保留的特征数量会大致相同。我们可以在每个batch中更换种子特征,从而SSL任务可以在不同的making模式下学习。
2.3 多任务训练
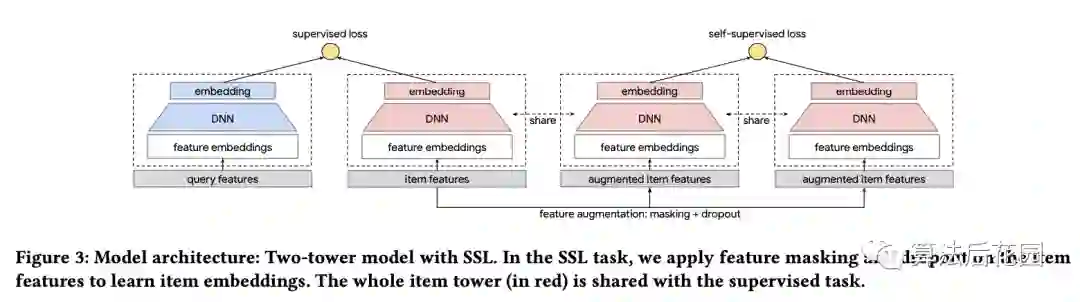
本文使用多任务训练策略,其中主任务是有监督任务,SSL任务是辅助任务,主任务和辅助任务联合优化。
上图中supervised loss对应的双塔是主任务塔,self-supervised loss对应的双塔是辅助任务塔(即SSL任务塔),虚线框的部分就是上文中提到的 和 , 结构是由输入层和MLP构成的,从上图中可以看到,主任务和辅助任务对应的item特征的embedding是共享的, 和 中与item相关的MLP参数也是共享的。上图中,SSL任务塔的数据增强先后经过了masking和dropout两个阶段。
我们定义
是从训练样本数据中采样得到的query-item样本对的batch集合,定义
代表从item数据中采样得到的batch集合,则联合loss定义如下:
其中 是主任务的损失函数,用来捕捉query和item之间的交互, 代表正则强度, 是辅助任务的损失函数。
主任务的损失函数。根据目标的不同,主任务的loss有很多选择,本文采用在推荐和NLP中优化top-k准确率问题常用的batch softmax loss。具体来说,我们定义 , 代表经过两个神经网络编码之后的query和item样本 的embedding,则对于一个batch的query和item对 和温度系数 ,batch softmax 交叉熵损失定义如下:
3 总结
本文介绍了推荐系统中应用对比学习比较成功的SSL方法,应用场景是推荐系统的召回阶段,解决了长尾item的问题。整个方法分为三大部分,即SSL框架、两阶段数据增强方法和多任务训练。
最后,想引出几个问题供大家思考:
(1)主任务损失和SSL任务损失中都有温度系数 ,其作用是什么?温度系数的设置对效果如何产生影响?
(2)本文中的SSL损失是InfoNCE loss,InfoNCE loss和cross entropy loss是否有联系?
以上问题,后期会介绍。
参考
[1] Deep Neural Networks for YouTube Recommendation.
[2] A Simple Framework for Contrastive Learning of Visual Representations.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


