当推荐系统遇上多模态Embedding
嘿,记得给“机器学习与推荐算法”添加星标
作者:九羽
转自:炼丹笔记
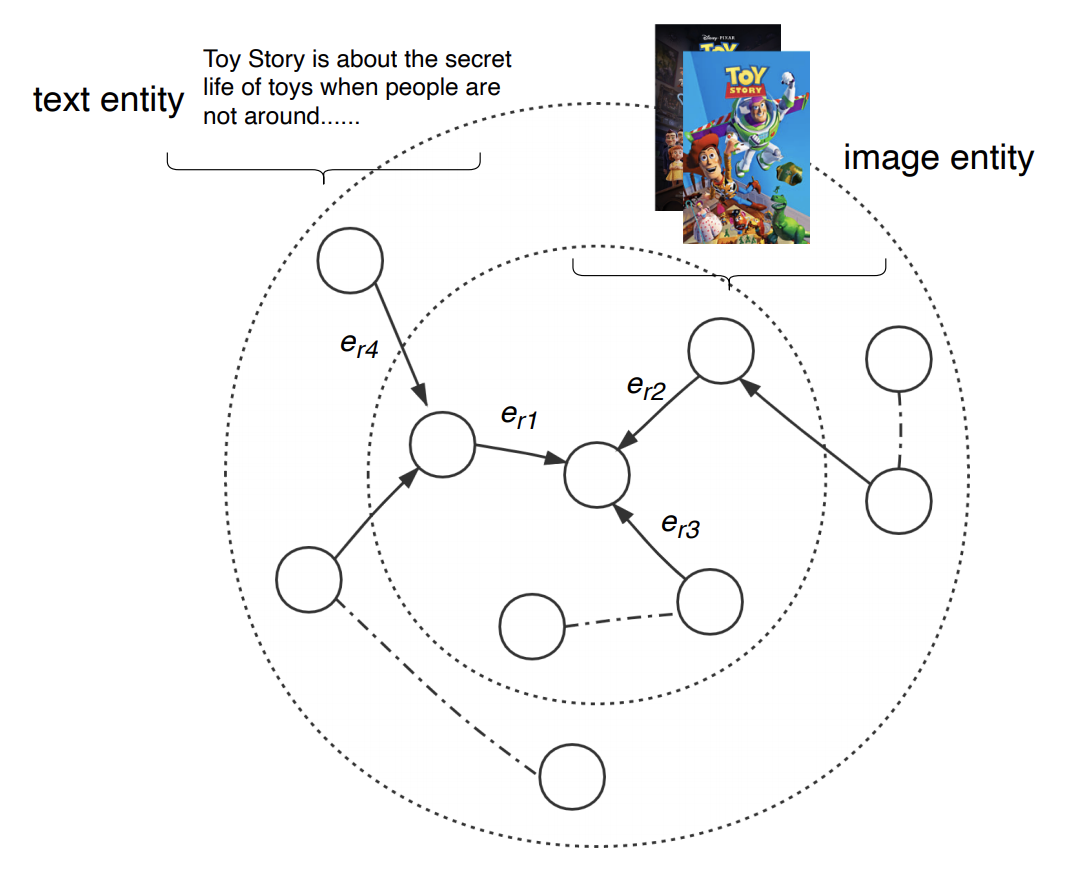
可见,多模态Embedding在推荐系统后续发展中的重要性。
MKGAT
先看下整体模型架构:
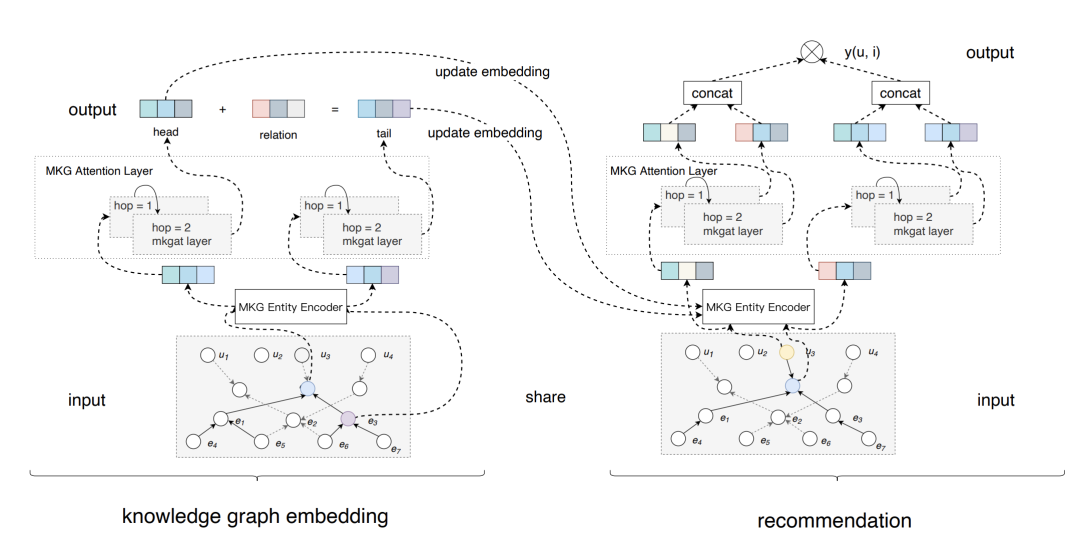
多模态图谱实体编码器:给不同类型实体编码。
多模态图谱注意力层:用注意力机制,融合所有邻居节点的信息,学习新实体的embedding。
多模态embeding把联合知识图谱作为输入,充分利用上面提到的两个小模块,去学习各个entity的表达。再用各个实体embeding的表达,去学习图谱之间的关系。推荐模块充分利用知识图谱学到的embedding ,和联合知识图谱去丰富用户和items的表达,从而提升推荐效果。
Reviews4Rec
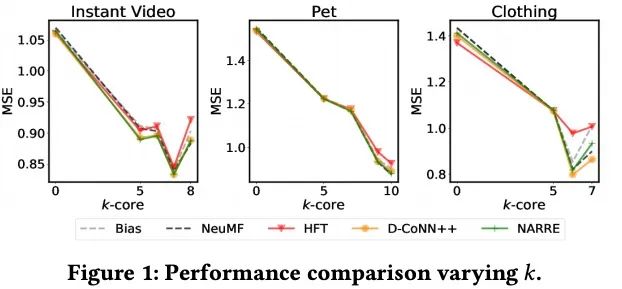
评论可能是非常重要的,但是最近的建模技术是很值得商榷的;
评论被作为一个正则而不是数据加入模型看起来更加有效;
该炉温更加关注一致的经验评估,尤其是数据集的选择和预处理策略;
多模态推荐竞赛实战
KDD Cup 2020 Challenges for Modern E-Commerce Platform: Multimodalities Recall 多模态召回赛题由阿里巴巴达摩院智能计算实验室发起并组织,关注电商行业中的多模信息学习问题。

1)搜索短句(Query)相关,为原始数据;
2)商品图片相关,考虑到知识产权等,提供的是使用Faster RCNN在图片上提取出的特征向量,两部分数据被组织为基于Query的图片召回问题,即有关文本模态和图片模态的召回问题。
美团季军方案
美团的季军方案主体部分包含两方面的内容:
1)通过联合多样化的负采样策略和蒸馏学习以桥接训练数据和测试集的分布,处理分布不一致问题;
2)采取细粒度的文本-图片匹配网络,进行多模信息融合,处理复杂多模信息匹配问题。
3)最后,通过两阶段训练和多模融合,进一步提升了模型表现。
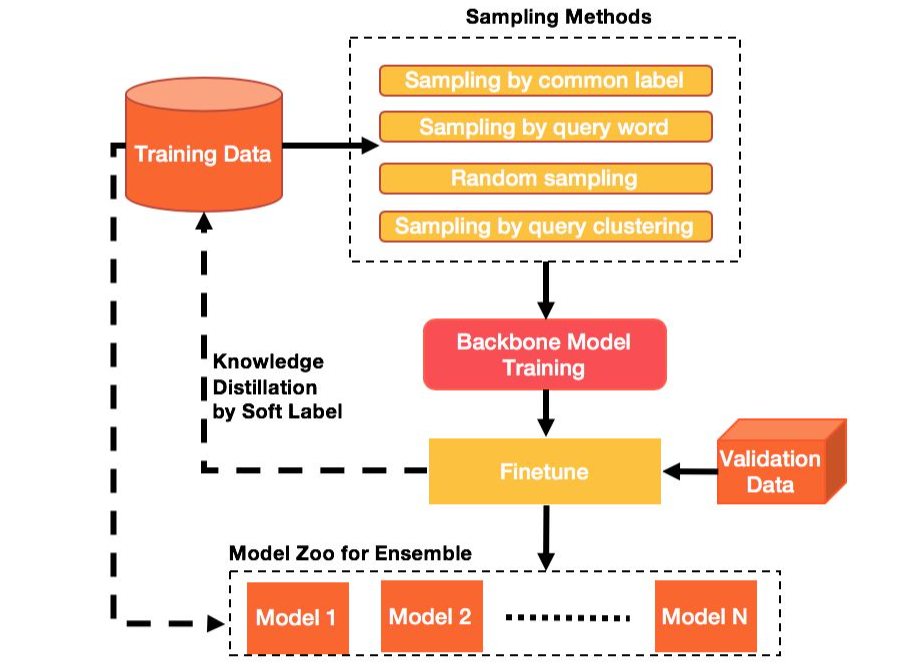
美团亚军方案
亚军方案从单流模型和双流模型中各选择了相应SOTA的算法ImageBERT和LXMERT。具体而言,针对比赛任务,两种算法分别进行了如下改进:
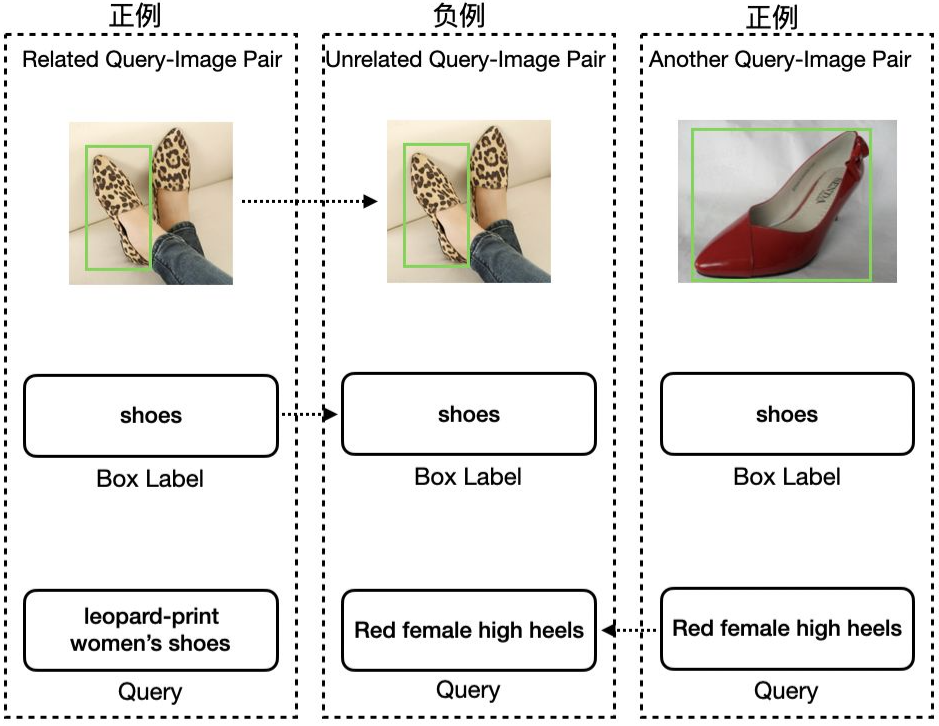
ImageBERT-A:将Segment Embedding统一编码为0,不对图片特征和Query文本单独进行编码,在[CLS]位输出Query与Image的匹配关系,通过Cross Entropy Loss计算损失。
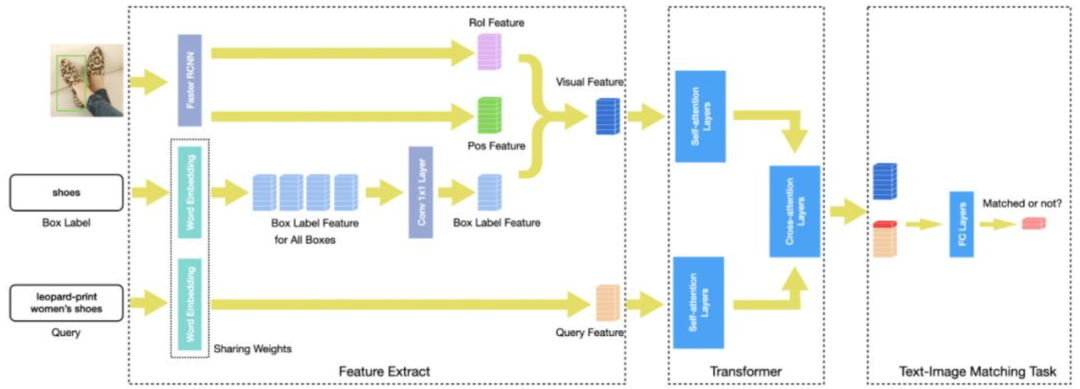
图片特征部分融入了目标框类别标签所对应的文本特征。
Text-Image Matching Task中使用两层全连接网络进行图片和文本融合特征的二分类,其中第一个全连接层之后使用GeLU进行激活,然后通过LayerNorm进行归一化处理。
在第二个全连接层之后采用Cross Entropy Loss训练网络。
改进后的模型结构见原文章所示。

https://dl.acm.org/doi/pdf/10.1145/3397271.3401281
Multi-Modal Knowledge Graphs for Recommender Systems
http://staff.ustc.edu.cn/~hexn/papers/mm19-MMGCN.pdf
https://zhuanlan.zhihu.com/p/258948165
https://zhuanlan.zhihu.com/p/258949239
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。




