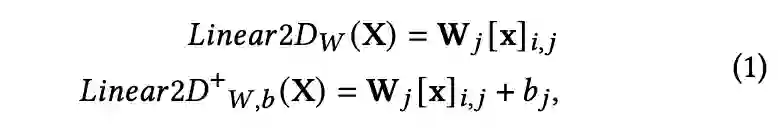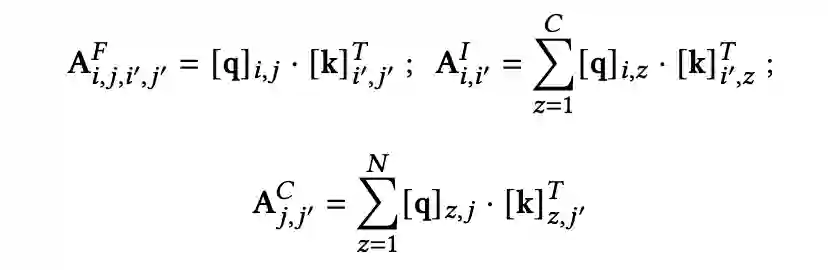作者:猫的薛定谔
链接:zhuanlan.zhihu.com/p/480216815
最近看了 22 年几篇顶会的序列建模的文章,模型无不复杂高深,但细细看后,发现这些文章本质上均是输入的变化,模型只为了配合输入。看看最近的顶会是怎么玩的吧。
背景
序列建模的目的是从用户的历史行为中挖掘用户的兴趣,进而给用户推荐感兴趣的物品。
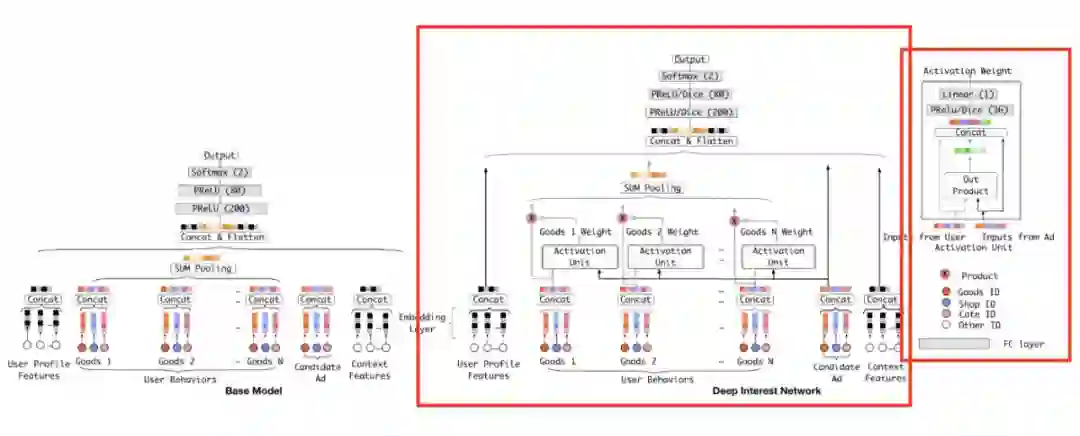
第一篇是我认为的开山之作——阿里的 DIN,模型结构如下图所示。该论文认为在选择 target item 时,user behaviors 中的 item 应该具有不同的权重,并采用了 target-attention 的方式计算权重。DIN 的 user behavior 是一个一维的 item 序列,emb 之后多一个 emb 维度,希望大家能记住这种输入格式,后面的算法就是在丰富这种格式。
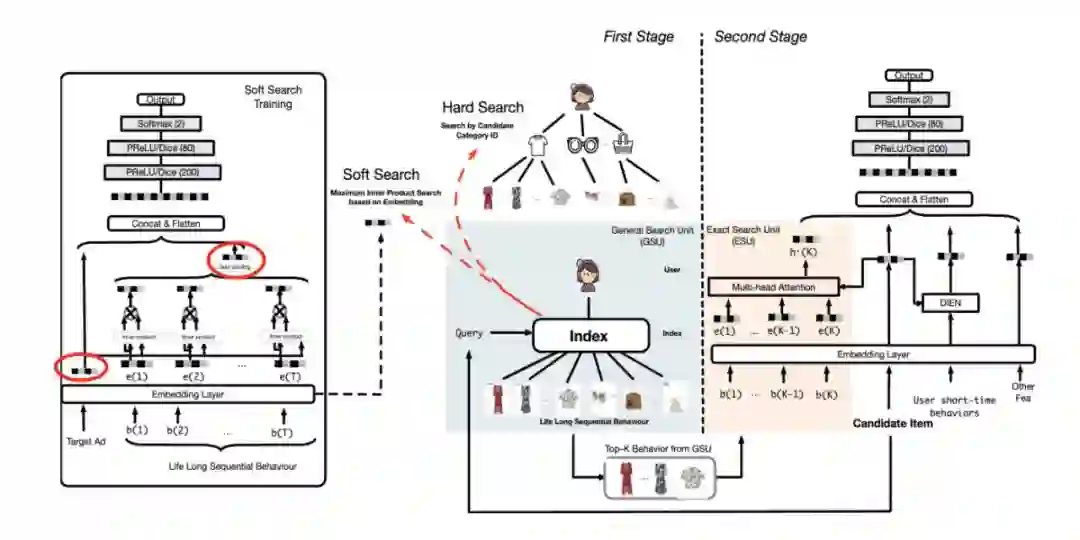
第二篇是长序列的经典文章——阿里的 SIM,模型结构如下图所示。在 DIN 的基础上,将用户行为序列变长 ,如果计算资源允许,无脑采用 DIN 的方式也未尝不可。回到 SIM,论文是这么做的:依旧保留短期行为序列,采用 DIEN(DIN 的一种变体)的方式提取用户短期兴趣;长序列则采用两阶段方法,召回得到 topk 个 item 后,再计算 target-attention。
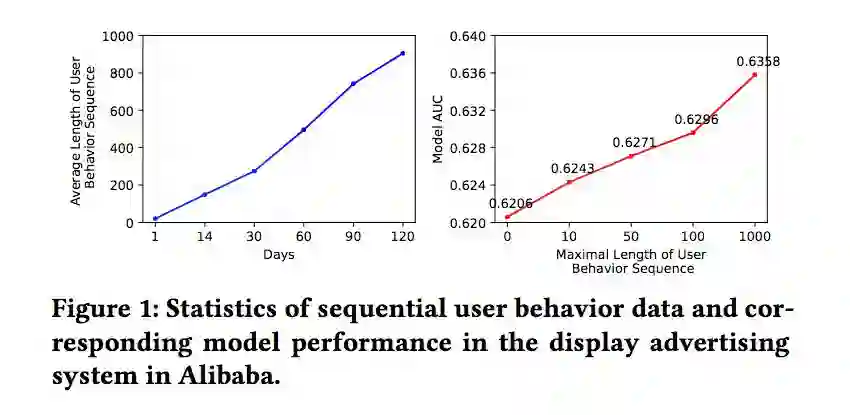
插句题外话,阿里的 MIMN 已经证明,序列越长,auc 越高。
玩法一:序列加side info
这是 eBay 在 WSDM 2022 上的文章。
论文标题:
Sequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
https://arxiv.org/pdf/2110.11072.pdf
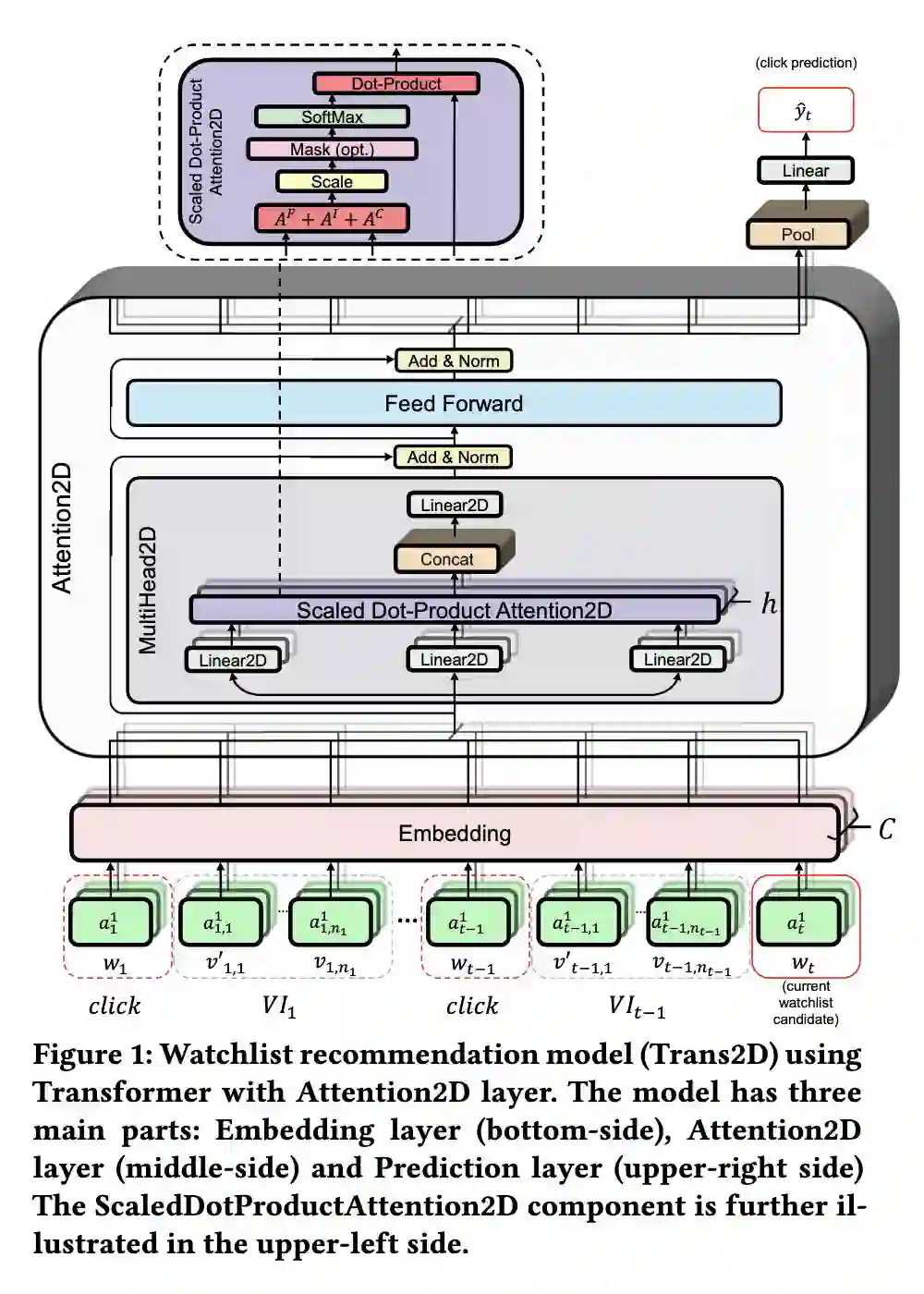
之前的序列都只是 item 的序列,eBay 额外加了 item 的属性,比如价格;这个属性是变化的,例如当价格变动时,用户可能会感兴趣。
因此
输入由一维序列变成了 2 维矩阵 ,对应的计算 attention 的方式也变成了 2D 的——attention2D,模型结构如下图。
具体的计算过程:
1. Embedding Layer——输入加了属性信息,是个 2D 的矩阵;embedding 之后多了 emb 维,shape 为
,N 为序列长度,C 为属性个数;
2. 多了个属性维度后,emb 如何转变为 QKV 呢?本文对每种属性(也叫 channel) 进行相同的线性变换,即:
▲ Linear2D,i代表item,j代表属性
3. 那 2D 的 QK 如何计算 attention score 呢?本文介绍了 3 种粒度的计算方式:
是 4 维数据,代表了第 i 个 item 的第 j 个属性与第
个 item 的第
个属性的交互,是最细粒度的交互;
是 2 维数组,对 item 的所有 channel 求和,表示的是 item 维度的交互;
是 2 维数组,对 channel 的所有 item 求和,表示的是 channel 维度的交互。将这三种 score 加权求和就是最后的 score 了(加权系数也是学出来的)。
▲ 2D的attention score
4. 到目前为止,计算了 attention之后,输出仍有 2 维,属性维和 emb 维。降维处理是在 prediction layer 之前,对属性维进行 pooling,将仅剩的 emb 维松儒 mlp。
玩法二:序列加宽
Triangle Graph Interest Network for Click-throughRate Prediction
论文链接:
https://arxiv.org/pdf/2202.02698.pdf
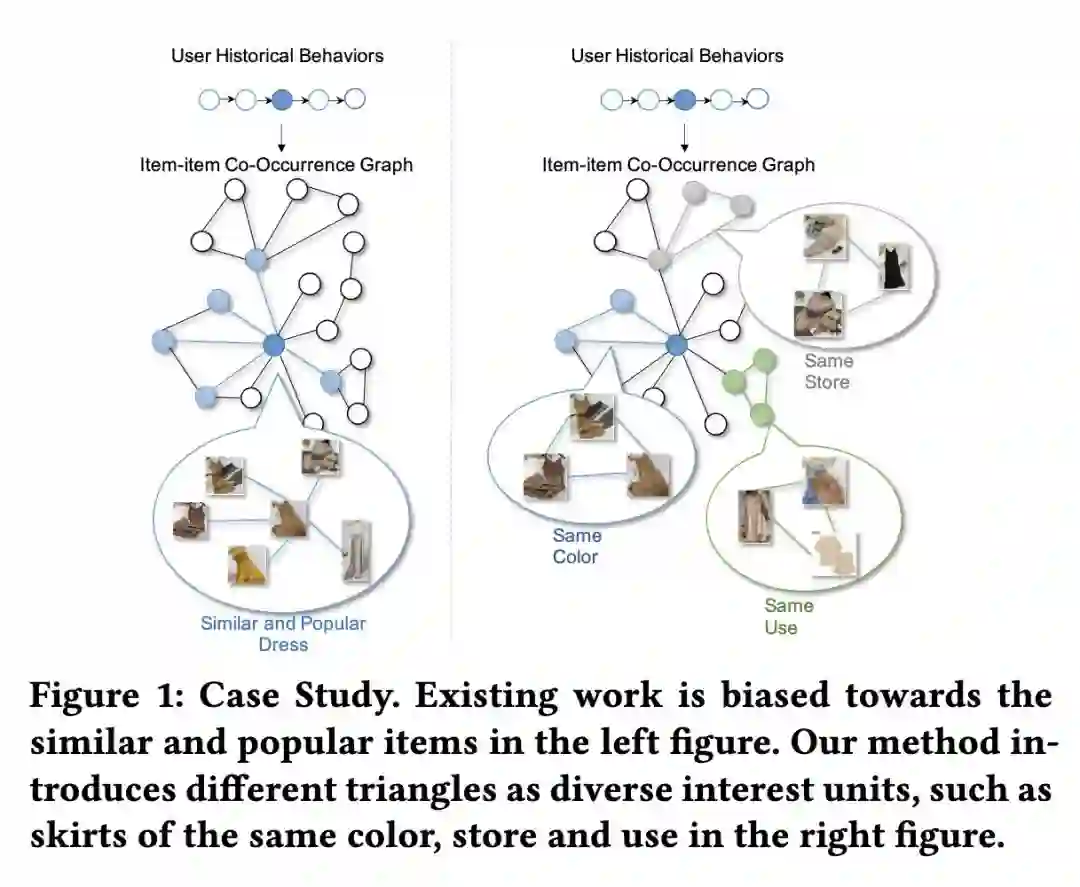
序列再长也只是这一个用户的序列,这篇论文直接从别的用户的行为中寻找 item。用所有用户的行为序列构建一个 item 图,图上的每个节点都是一个 item,item 有边代表有用户依次点击过这两个 item。
本文首先定义了一个图上的 triangle,triangle 的定义不是重点,可以把
triangle 简单的理解为图上的邻居 。
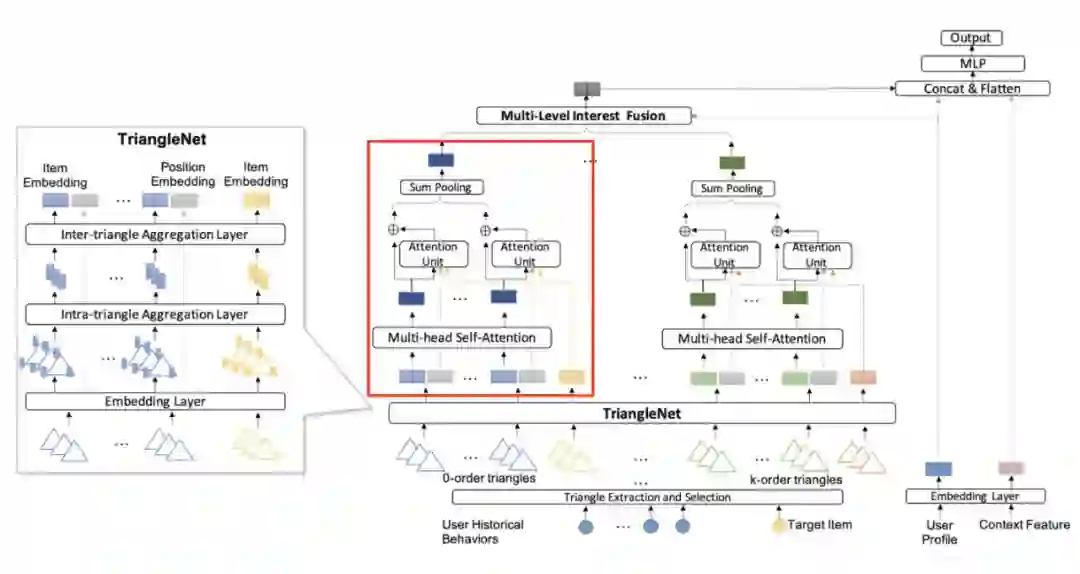
TGIN 的模型结构如下图,看着复杂,其实很简单。下图中的红框部分就是一个类似于 DIN 的计算 attention 的网络,左边是处理 triangle 的,有边是计算多阶 triangle(理解为图上的多阶邻居)attention 的网络。
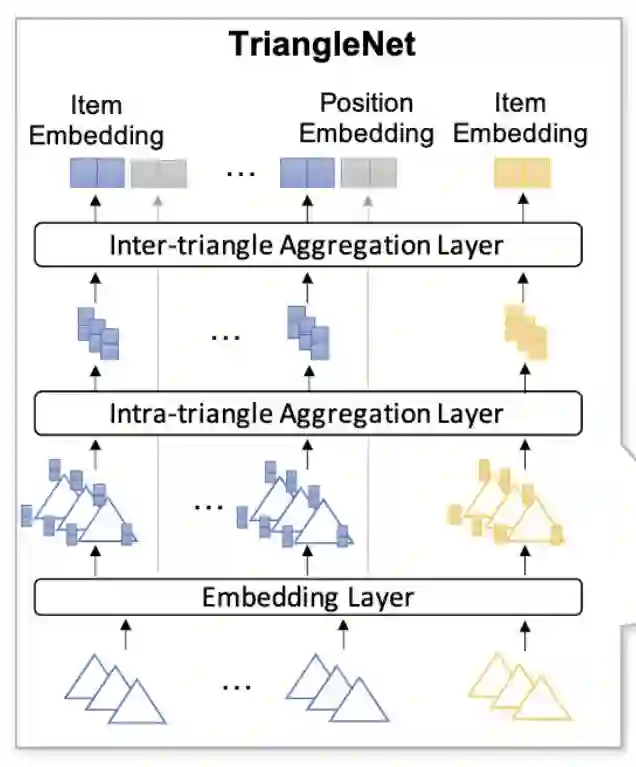
▲ TGIN
某阶的 TriangleNet:每一阶会有多个 triangle,每个 triangle 会有 3 个 item,所以就先内部聚合(intra),简单的 avg pooling;再外部聚合(inter),multi-head self-attention。
▲ TriangleNet
玩法三:序列分段并加标签
Modeling Users’ Contextualized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search
论文链接 :
https://guyulongcs.github.io/files/WSDM2022_RACP.pdf
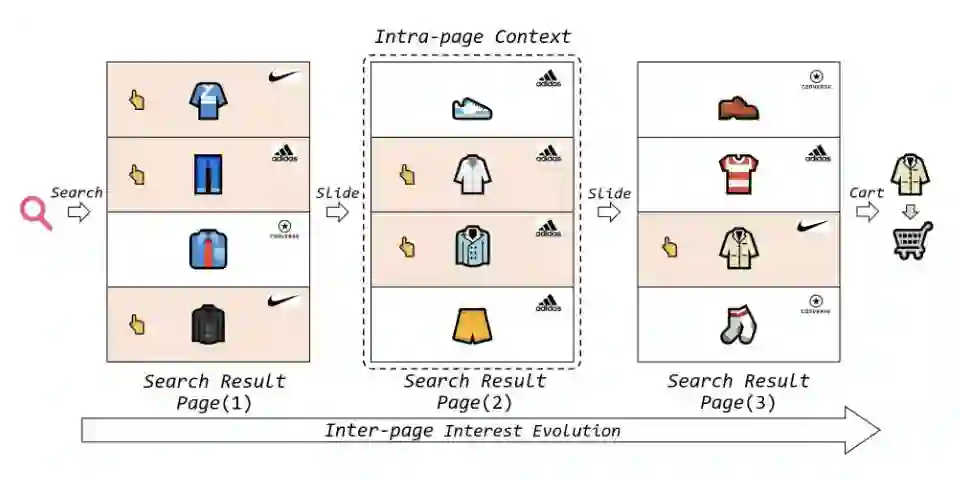
序列以 page 的形似分段,page 内不仅有点击 poi(正反馈),还有未点击 poi(负反馈),捕获页面内的 context 信息和页面间的兴趣演变。页面信息能学到什么?用户不点击可能不是因为不喜欢,而是页面中有一个同类型但更便宜的。
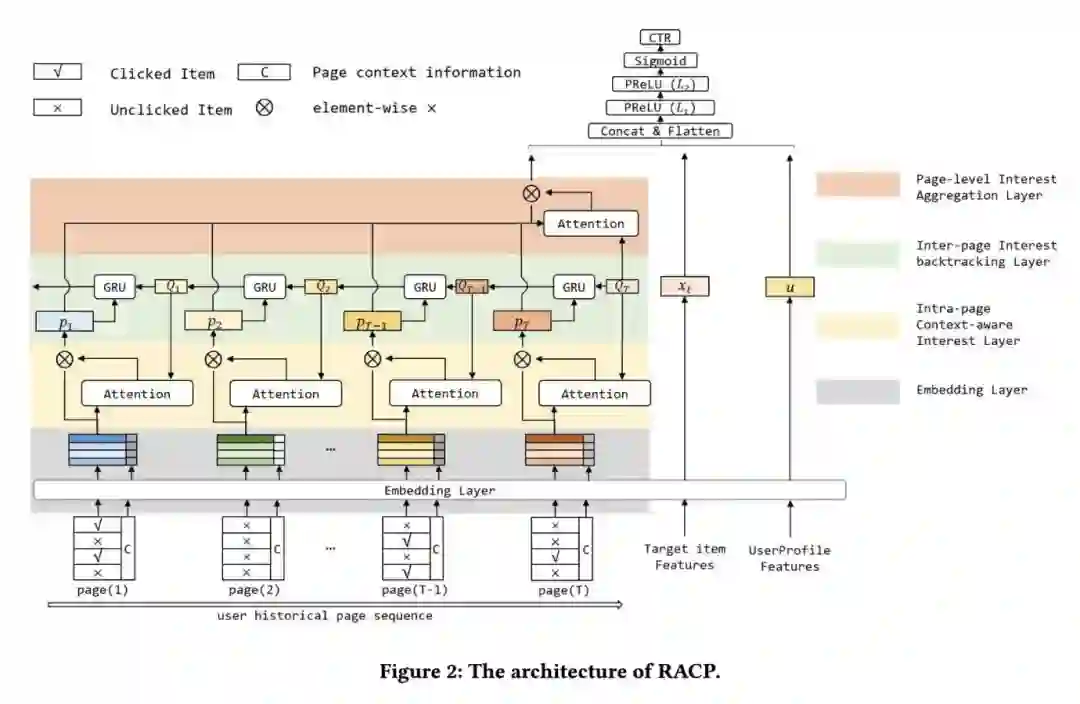
模型结构如下图。一般像这种两层结构的输入,模型也是有两层,一层提取页内信息(intra),一层聚合页间信息(inter)。这个模型有三层,中间加了一层 backtrack 层。还有一个细节,page 是经过过滤的,将其限制在与当前查询向量同类别的范围内。
重点解释一下兴趣回溯层,即上图中的绿色部分。一般的模型只注重了长期兴趣与 target item 的相关性,而忽略了短期兴趣的一致性。具体到这篇论文,短期兴趣指的就是每个 page 所代表的兴趣。
在这一层引入了一个用户当前兴趣的查询向量
(这是一篇搜索的文章,所以有查询向量),其余的
不再是真正的查询向量,而是 attention query vector。attention query vector 通过 GRU 一层一层往左传,影响 page 内的 attention 计算。
总结
玩法一:加 item 的属性。这个属性的选择非常有讲究,
得是变化的、且用户非常敏感的 ,比如价钱、比如补贴;不能是那种无关痛痒的属性。
玩法二:加更多的 item,不过不是加长,而是通过图(本质是通过其他用户),引入一些用户以前没见过(或没交互过)但可能感兴趣的 item;这种加 item 的方式可以离线完成,可以用一些“高大上”的方法吹牛逼。个人感觉,这种方法有效的本质是
学习了更多的共现关系 。之前在给 user 选择 poi 时,只学习了 user 自己历史内的 poi 的共现关系;通过某种合理的方式(如其他用户的历史行为)引入更多共现关系可以拓宽模型的视野。
玩法三:序列分段(分 page、分 session),混合序列(不仅仅是点击序列),最真实地 还原用户做选择的环境 ,推理用户在段内的点击逻辑,分析用户的选择心理。
欢迎 干货投稿 \ 论文宣传 \ 合作交流 推荐阅读
由于公众号试行乱序推送,您可能不再准时收到 机器学习与推荐算法 的推送。为了第一时间收到本号的干货内容, 请将本号设为 星标 ,以及常点文末右下角的“ 在看 ”。