AI综述专栏 | 跨领域推荐系统文献综述(上)
AI综述专栏简介
在科学研究中,从方法论上来讲,都应先见森林,再见树木。当前,人工智能科技迅猛发展,万木争荣,更应系统梳理脉络。为此,我们特别精选国内外优秀的综述论文,开辟“综述”专栏,敬请关注。
导读
跨领域推荐系统(Cross domain recommender systems,CDRS)能够通过源领域的信息对目标领域进行辅助推荐,CDRS由三个基本要素构成:领域(domain),用户-项目重叠场景(user-item overlap scenarios)和推荐任务(recommendation tasks)。这篇研究的目的就是明确几种广泛使用的CDRS三要素的定义,确定它们之间的通用特征,在已明确的定义框架下对研究进行分类,根据算法类型将同类研究进行组合,阐述现存的问题,推荐CDRS未来的研究方向。为了完成这些目标,我们挑选出94篇文献进行分析并最终完成本综述。我们根据标签法对选出的文献进行分类,并且设计了一个分类坐标系。在分类坐标系中,我们发现研究类域的文献所占权重最大,为62%,研究时域的文献所占权重最小,为3%,和研究用户-项目重叠场景的文献所占权重相同。研究单目标领域推荐任务的文献占有78%,研究跨领域推荐任务的文献只有10%。在29个数据集中,MovieLens所占权重最大,为22%,Yahoo-music所占权重最小,只有1%。在7种已定义算法类别中,基于因式分解的算法占了总数的37%,基于语义分析的算法占了6%。最终,我们总结出5种不同的未来研究方向。
「关注本公众号,回复"CDRS",获取英文版PDF」
一 介绍
推荐系统是一种特殊的软件程序,能够根据采集到的用户兴趣向用户推荐项目,用户兴趣的采集以交互的方式进行,例如使用由数字评分构成的评分矩阵。用户,项目和评分矩阵建立的推荐生态系统,通常被称为一个领域。
目前,推荐系统的研究聚焦于单领域推荐,例如,淘宝网向用户推荐商品;B站向其用户推荐视频内容,网易云音乐向用户推荐歌单。这些推荐系统往往都只是针对具有特定兴趣的用户,并没有覆盖大多数用户。
目前,推荐系统的研究聚焦于单领域推荐,例如,淘宝网向用户推荐商品;B站向其用户推荐视频内容,网易云音乐向用户推荐歌单。这些推荐系统往往都只是针对具有特定兴趣的用户,并没有覆盖大多数用户。
单领域推荐系统面临许多问题,如冷启动问题,稀疏性问题等。跨领域推荐系统为了解决这些问题,引进新的维度,将其它领域(源领域)的信息转移到目标领域中。
近年来,CDRS研究的势头很足,研究者从不同的方面对其做出了贡献,使用了许多不同的方法,这些方法有:
·基于图的方法,用于计算源领域和目标领域的用户与项目间的关系
·基于因式分解的方法,用于提取出源领域和目标领域的用户和项目之间的通用特征
·基于语义的方法,将源领域的属性应用到目标领域中,生成知识图谱
·基于标签的方法,生成涉及领域之间互相关联的元数据
每篇论文都试图将其观点在领域类型,用户-项目重叠场景和推荐任务分别进行说明,这三个属性是CDRS的基本要素,它们被不同的研究者提出:Li和Ivan提出领域的概念,Cremonesi和Fernandez-Tobias等人提出推荐方法的概念,Cremonesi、Fernandez-Tobias和Ivan Cantador等人提出了推荐任务的概念。
尽管这些人提出了CDRS的定义,但是他们的观点实际上并没有相互支持。而且他们中的一些人的研究方向并不相同,Li提出了“系统”、“时间”和“数据”领域,Ivan Cantador根据物品属性描述领域;Cremonesi等人描述了用户-项目重叠场景,Fernandez-Tobias对其进行了进一步研究;关于推荐任务,尽管Cremonesi、Fernandez-Tobias、Ivan Cantador等人分别提出他们自己的定义,没有进行引用,但是他们的提出的定义非常的相似。
现存的CDRS二级研究中,还没有对已提出的三要素定义的共同点进行说明的文献,这就导致需要根据不同的定义方法将研究者进行划分。在本文中,我们使用系统性文献综述方式去收集和分析一级研究的研究成果,使用普遍认可的评论方法去全面的展示CDRS研究,达到综述的目标。最终,我们使用推荐系统三要素构建的分类坐标系,列出了94篇文献并进行了分类和对比。根据三要素在分类坐标系水平和垂直方向上的权重的不同,我们制作了两种坐标图:领域vs用户-项目重叠场景坐标图和推荐任务vs用户-项目重叠场景坐标图。这两种坐标图与Ivan Cantador使用的分类方法非常相似。我们并未制作领域vs推荐任务坐标图,因为推荐任务相对于领域的变化并不是独立的。本文经过综合分析,基于对坐标图中主要研究的分类,得出当前研究的趋势。
为了解决系统性文献评论(systematic literature review,SLR)研究的主要问题,本文首先尝试去明确已有CDRS三要素定义的共同点。其次根据领域vs用户-项目重叠场景坐标图和推荐任务vs用户-项目重叠场景坐标图对主要的研究论文进行分类。第三,对CDRS使用的算法进行分组,列出对CDRS研究具有较大贡献的数据集。第四,描述CDRS普遍存在的问题。最后,指出CDRS未来的研究方向。因此,该文献综述对以下读者非常有帮助:
·首次接触CDRS,想找到研究CDRS的重点、问题、未来研究方向的研究者。
·对不同CDRS定义比较困惑的研究者,需要一篇综合说明指出这些定义间的共同点。
本文分为7个部分,第一部分是简单介绍。第二部分为相关研究,包括:1.列出了定义CDRS三要素的相关文献;2.收集并讨论了普遍认可的CDRS三要素定义;3.比较和评论了CDRS相关文献。第三部分包括本文献综述的研究目标和一系列关于经验性研究的分类准则的定义。第四部分阐述了研究问题,研究策略,纳入和排除准则,以及根据文献综述的一般方法进行的数据提取过程。第五部分为综述过程中遇到的问题及解决办法。第六部分讨论了合法性。第七部分为结论,并指出未来的研究方向。
二 相关研究
这部分收集了现有的相关文献,初步定义CDRS属性,列出与这些属性相关的多种定义,简述某些研究者们根据这些属性所设计的对于CDRS的主要研究成果的分类方法。
1 CDRS的三要素
CDRS方向的一级研究通常将其研究内容根据不同领域间的信息迁移进行划分,依据的是在两个领域上用户与项目之间的相似性。类似的,一旦产生信息迁移,则根据生成的推荐对一级研究进行分类,生成的推荐涉及的是面向目标领域用户还是源领域用户,还是两种用户都参与,这个过程被称为推荐任务。综上所述,领域差异,用户-项目重叠场景,推荐任务可以为认为是CDRS研究的三个最基本的方面,这三个方面称为CDRS的三要素。
考虑到三要素已经被广泛的使用,我们有必要首先对其定义分别作出解释。
(1)领域符号
领域符号的定义是Li和IvanCantador完成的,Li定义了系统、时间、数据领域(system,time,and data domain),Ivan Cantado分别定义了项目属性等级领域(item attribute level domain),项目类型等级领域(item typelevel domain),项目等级领域(item level domain),系统领域(system domain)等,截止到完成该综述,Li的定义方法更为流行,下面详细介绍两种定义方式:
·Li的领域定义方法:
系统领域:当数据在目标推荐系统评分矩阵(如MovieLens)比某些相关的推荐系统(如Netflix)更为稀疏时,每个推荐系统都被认为属于不同的领域。在这种情况下,信息从评分矩阵较为密集的领域传送到较为稀疏的领域。
数据领域:在推荐系统中,用户与项目的相互行为可以以数字评分方式(1-5分)或者0/1方式(如喜欢/不喜欢)进行存储。这些基于相互行为的多维数据可以被认为属于不同的数据领域。
时间领域:为当评分矩阵被时间戳分割成不同的时间序列时,每个时间序列都被认为是独立的时间领域。
·Ivan的领域定义方法:
项目属性等级:如果两个项目的属性是不同的,那么这两个项目被认为属于不同项目属性领域。如不同类型的电影,喜剧和动作片可以被认为属于不同的领域。
项目类型等级:如果两个项目的某些属性不同,但是其它的相同,那么它们被认为属于不同项目类型领域。如电影和电视节目可以看作属于不同的领域,因为虽然它们的项目可以拥有相同的标题和类型,但它们的其它属性(如播放时长)不同,比如《神话》的电影版和电视剧版。
项目等级:根据项目在某个主要属性上差异的划分方式。例如,电影和图书可以被认为是拥有相同名称(同一作品)但不同传播媒介的项目。
项目等级:属于不同系统的项目被认为是属于不同领域。例如,豆瓣和优酷被认为是属于不同的领域。
Li和Ivan的对于系统领域的定义方式是相似的,但是其它的定义方式有一些不同。Ivan的定义方式提出的较晚,但由于其表述不清等原因,学术界普遍采用Li的定义方式。
(2)用户-项目重叠场景
对于用户-项目重叠场景,最突出的贡献是Cremonesi提出的定义,他提出了四种用户-项目重叠场景,这四种方法已经被许多研究者引用过,除此之外还有一些其它的定义方法。
·Cremonesi定义的场景:
为了协助领域之间的信息的迁移,参与的领域中的用户和项目之间需要存在某种联系。通常情况下,这种联系表现为用户和项目在各个领域上的共同点。Cremonesi强调了这种联系的重叠方式,将它们用如图1的方式表现出来。
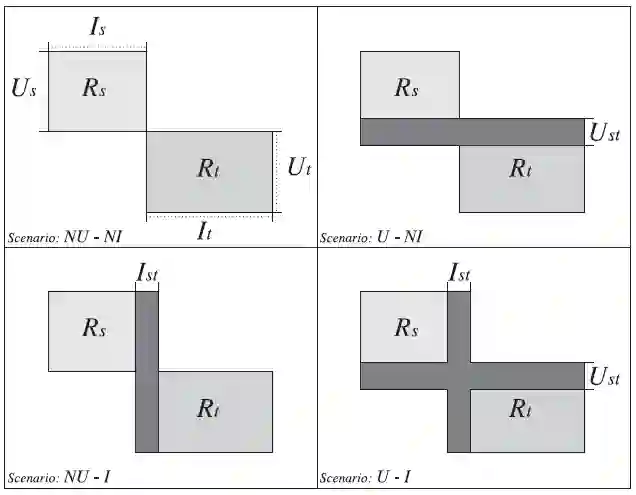
图1 用户-项目重叠场景
四种场景分别为:
无用户-无项目重叠(No User–No Itemoverlap,NU-NI):在这种场景中,涉及的领域没有相同的用户和项目,领域之间的评级被用来分析用户和项目之间的相似度。
用户-无项目重叠(User–No Itemoverlap,U-NI):涉及的领域中存在相同的用户,能够协助生成推荐。
无用户-项目重叠(No User–Item overlap,NU-I):涉及的领域中存在相同的项目,能够协助生成推荐。
用户-项目重叠(User–Item overlap,U-I):涉及的领域中存在相同的用户和项目,能够协助生成推荐。
·Fernandez定义的场景:
Fernandez提出,用户和项目在不同领域上小部分重叠的情况,会使生成的推荐不精确。所以他定义了用户和项目在不同领域之间的“特征(characteristics)”重叠。特征定义为由用户和项目在各领域上的评分生成的特征向量。
(3)推荐任务
跨领域推荐的推荐任务与用户推荐相关。涉及的两个主要因素就是被推荐项目的范围和目标用户的范围,被推荐项目可以来自于源领域或者目标领域,同样,目标用户也可以存在于源领域或者目标领域,这就催生了多种推荐场景。简单来说,推荐任务的概念为:
·Cremonesi提出的推荐任务:
单领域:根据从源领域获取到的信息,将目标领域的项目推荐给目标领域的用户,被称为单领域推荐任务。
跨领域:将源领域的项目推荐给目标领域的用户或者相反的方式,被称为跨领域推荐任务。
多领域:将目标领域和源领域的项目推荐给目标领域和源领域或其中之一的用户的方式,被称为多领域推荐任务。
·Ivan提出的推荐任务:
多领域推荐:将目标领域和源领域的项目推荐给目标领域和源领域或其中之一的用户的方式,被称为多领域推荐任务。
相关领域推荐:根据源领域的获取到的信息将目标领域的项目推荐给目标领域的用户,被称为相关领域推荐任务,也称为跨领域推荐。
·Fernandez提出的推荐任务
(场景一):根据源领域获取到的信息将目标领域的项目推荐给目标领域的用户。
(场景二):创建联合推荐,将目标领域和源领域的项目推荐给目标领域和源领域的用户。
不同的研究者提出了对CDRS三个基本要素的不同定义方式,下文中出现不同定义方式时会特别指出。
2 关于CDRS的三大基石的一些问题
Q1 为何不同的研究者会有不同的定义?
(1)直到现在,推荐系统社区还未做出有效措施去标准化CDRS三要素的定义。
(2)还未有研究尝试去总结现有的CDRS三要素的定义并找出不同定义方式之间的相同点。
(3)现有的研究定义CDRS三要素的方式没有进行相互引用。
由于截至目前还未有文献去区分不同定义之间的相似之处,造成CDRS主要研究成果互通的困难,所以本文尝试去区分现存的定义,找出其相似之处,这也是本综述所要完成的第一个目标。
Q2 不同定义之间都有哪些相似之处?
已提出的定义在二.1中进行了详细的阐述,所有的三要素定义方式都以评分矩阵为基础,评分矩阵是推荐系统最基础最重要的部分,评分矩阵包括用户对推荐系统中被推荐项目的行为。用户,项目和评分矩阵拥有类似的特征,如评分时间,物品类型,用户类型,评分类型,矩阵范围等。每种定义方式都尝试去根据这些特征聚集用户,项目和评分矩阵。
领域:时间领域与评分矩阵的时间特征有关,即与何时做出评分有关。数据领域与评分矩阵内评分的数据类型相关,例如数字评分或1/0评分等。系统领域和评分矩阵的范围有关。时间、数据和系统领域都是由Li提出的,系统领域的定义和Ivan提出的相同。Ivan余下几种概念的定义方式依赖于项目的属性,项目的属性与元数据的特征有关,元数据的特征又与评分矩阵内的项目有关。
推荐场景:推荐场景使用了涉及领域的相似特征,将信息从源领域传输到目标领域依据的是两个领域中用户和项目的相似性。通常情况下,相比于目标领域,源领域拥有更密集的评分。
推荐任务:推荐系统为用户生成推荐,这个过程被称为推荐任务,推荐任务的终极目标是在没有评分的情况下完成推荐。没有评分的情况可以存在于源领域和目标领域,因此,一个推荐任务可以为源领域和目标领域或二者之一提供推荐。
三.2中列出了以标签形式表示的已识别特征,并且使用这些特征对一级研究中的数据进行提取,提取的数据用于对一级研究进行分类,根据分类结果绘制出的分类坐标系在五.2中列出。
Q3 这些定义的数量未来还会增加吗?
推荐系统还在不断演化和改进中,会根据用户,项目和评分相关特征的增多不断进行改进,一个新的特征集会打开一片关于源领域到目标领域信息传输的新视野。因此,很可能未来CDRS三要素的相关定义还会增加,这一部分在五.4.(2)中进行了详细说明。
尽管定义数量会增多,但是要素的种类(领域、重叠场景和推荐任务)基本上不会再增加了,它们将服务于信息转移过程的具体步骤。
总的来说,领域,用户-项目重叠场景和推荐任务在一级研究中非常常见,它们的属性被认为是两个二级研究的分支,根据二级研究总结出的比较结果将在下一节中进行简单介绍。
3 二级研究比较
近年来,跨领域推荐系统研究的势头很猛。然而只有两个二级研究吸引了研究的潮流,表1列出了两个二级研究中的共同属性,并根据一级研究进行了分类。
表1 二级研究比较

提到的属性中,前三个为前文阐述的三要素,实现算法、已定义问题,未来方向都与一级研究的实验相关,Fernandez针对协同过滤技术和基于内容技术,分别对跨领域推荐系统的一级研究进行了分析。有时也根据用户-项目重叠场景或推荐任务对一级研究进行分类。类似的,Ivan分别根据领域、用户-项目重叠场景和推荐任务对一级研究进行了分类,他更多的关注了跨领域推荐中的用户和项目模型。这两种研究都指明的未来的研究方向,Ivan同时指出了跨领域推荐系统面临的问题。
三 研究目标和分类标准
本文的研究目标针对CDRS的三要素(领域、用户-项目重叠场景、推荐任务)和实验性属性(包括实现算法、存在的问题、未来发展方向),分析现存的跨领域推荐系统相关文献。
1 系统文献综述需求
表1比较了不同一级研究类别下的二级研究的差异,相关二级研究覆盖了一部分的目标;然而,还不能通过提供一套方法论的研究策略去验证这些研究。因此,我们使用系统文献综述的方式完成这一目标,同时使用标签法对一级研究进行分类。
2 分类标准
我们使用了标签法对一级研究进行分类。知识标签是元数据信息的一种,可以描述观察到的数据的某些方面。在标签法中,与一组项目相关的概念以关键词的形式进入备选范围,每个项目都由相关的标签进行表示。标签法已经存在了很长的时间,被许多研究者用于分类、组合和筛选一级研究。
请读者记住二级研究的特性,我们将基本的CDRS概念标签(如表二所示)进行组合,然后对进入备选范围的一级研究进行分类。
表2 分类标签组
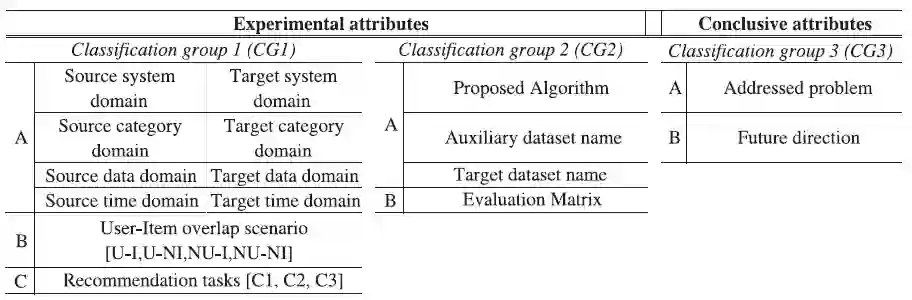
使用标签法的主要考量就是尽可能多的收集一级研究。进一步说,每个一级研究都不能覆盖所有的标签。某些研究能覆盖领域、用户-项目重叠、算法实验、算法使用和现存问题,即CG1A,CG1B,CG1C,CG2A和CG3A。另一些研究也能按他们的想法进行任意组合,将标签进行的组合顺序为:领域知识转移属性(Classification Group 1: CG1),算法和分析属性(CG2)、当前存在的问题和未来的研究(CG3)
总的来说,上文提到的标签将会在一级研究的筛选(4.3)和分类(4.7)中用到。
四 研究方法
与非结构化的评论过程相比,系统研究综述试图使用详细专业的步骤,按照序列收集相关程度最高的文献。我们根据Brereton的指导,构建3步评审过程,包括准备、实施和记录阶段,图2为每个阶段的具体工作和驱动每个阶段的结果。为了更清楚的说明研究过程,每个阶段的具体工作由实际研究的文献题目表示。
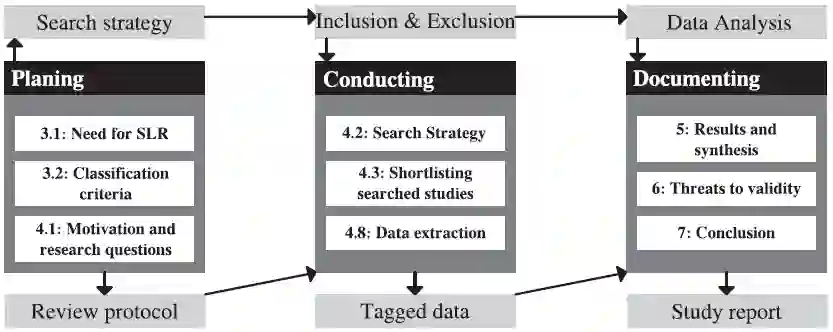
图2 研究阶段
1 动机和研究问题
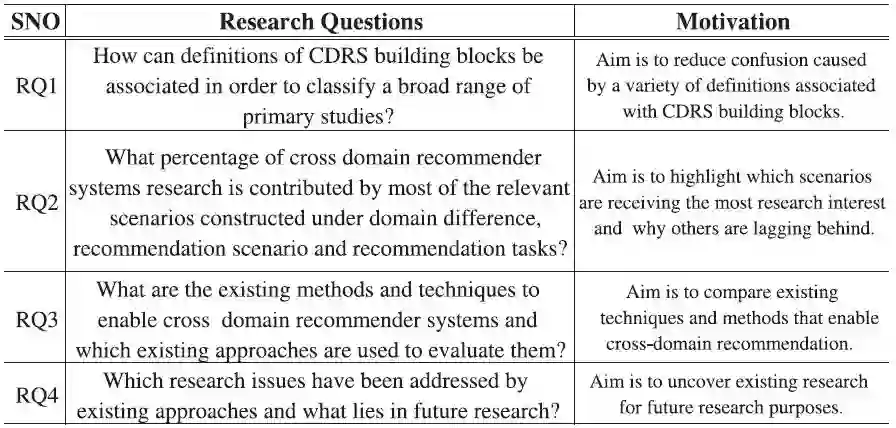
比较2.3中讨论的二级研究,我们决定使用文献综述研究方法,根据领域差异,用户-项目重叠场景,推荐任务,目前存在的问题和未来研究方向分别进行总结。我们的研究动机在3.1中已经定义过了,在本节中,研究问题列在表3中。
表3动机和研究问题
我们同时在表4中确定了PICOC(population人数、intervention影响、comparison比较、outcome结果、context语境)准则,定义了SLR的范围。
表4 PICOC准则

PICOC列出的五条准则都是SLR所要尽量满足的,人数和研究问题的参与者的身份有关,影响是比较一类研究者的先决条件,结果与基于比较结果的分析有关,语境与系统性研究的贡献有关。
2 研究策略
一级研究由2.3中提到的二级研究的比较进行分析。每个一级研究中,搜索关键词被汇集成一个文件,然后对该文件进行词频分析,词频最高的短语被选出,图3为二级研究中出现词频最高的短语。
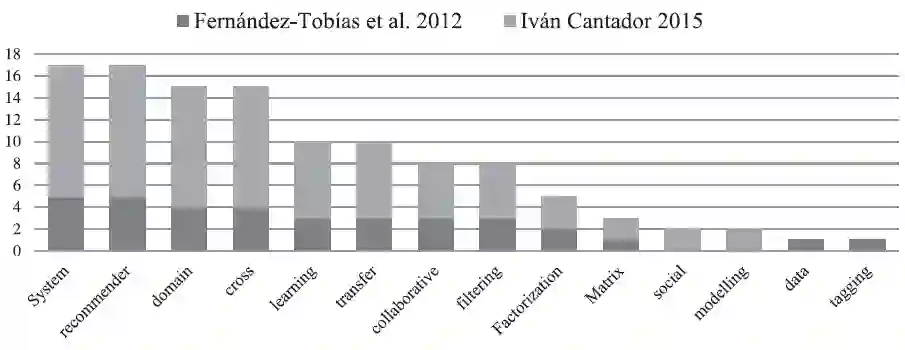
图3 短语出现频率
频率最高的短语在二级研究中往往都是成对出现的,例如跨领域、推荐系统、协同过滤、迁移学习、矩阵分解等。本文的搜索关键词依据前期的短语统计,使用表5中的短语生成。
另外,根据相似性将短语进行分组。因此组1的短语和多种实体之间存在的关系有关。组2和研究领域有关。搜索关键词由此被构建出,如表5所示。
表5 搜索关键词和搜索语句

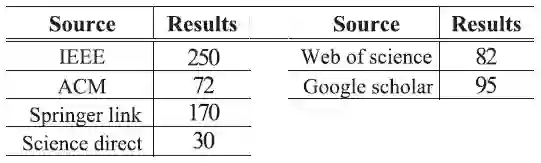
为了收集一类研究,一种高亮伪搜索字符串被用作文献检索系统的搜索关键词,我们选择ACM,IEEE,Springer Link和Science Direct作为文献库,为了查漏补缺,较大的文献库如Web of Science和Google scholar也被搜索过。基于每个搜索源提供的搜索,可以确立包含题目和摘要的搜索集。另外,搜索结果和时间也有关系,覆盖的搜索结果包括2016年以前的文献。
表6为每个搜索源中发现的文献数量,在下一节中,我们描述我们筛选一级研究的纳入和排除标准。
表6 搜索结果
3 筛选研究
对于一级研究的筛选包含三个阶段,首先是搜索标题,其次是阅读摘要,最后是标注,过程如图4所示。搜索结果中收集的文献列在了表格中,对每篇文献,题目和摘要都会被提及。这个表格文件用于筛选的前两个阶段,纳入和排除标准用于辅助筛选过程。
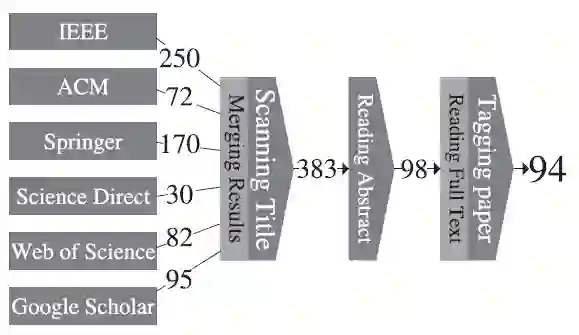
图4 筛选研究
4 纳入和排除标准
在纳入过程中,根据标题和搜索关键词的相似程度,我们选出383篇文献。下一步,我们阅读了每篇选出文献的摘要和文献分析基于的定义。在此过程中,一些文献和第2节中讨论的CDRS定义较为匹配,最终我们选出98篇文献,其中4篇我们认为具有定义性的贡献【Cremonesi 2011; Li 2011; Fernandez-Tobıas 2012; Ivan Cantador 2015】,其他的文献对CDRS都有实验性贡献。在标注过程中,根据提取出的数据对94篇一级研究进行了标注。
在排除过程中,首先题目和摘要中没有搜索关键词的文献被排除,搜索结果中包括硕士论文和博士论文,其中一部分来自电子通信领域,还有一些重复搜索结果,这些都要进行排除,最困难的是排除那些讨论推荐系统但没有涉及跨领域的文献。最后,涉及跨领域推荐但未做出足够贡献的也被排除。
5 标注文献
选出的94篇一级研究经过详细的复核后,使用表2中的标签对其进行标注,分类组1(CG1)中包含两种“标签”,领域(CG1A)和用户-项目重叠场景(CG1B)标签存在于86个一级研究中,推荐任务(CG1C)标签存在于65个研究中。分类组2中的(CG2A)和(CG2B)分别存在于70和72个一级研究中。最后,文献中的67篇指出了存在的问题(CG3A),46篇提供了未来的研究方向,这些被划分在分类组3(CG3)中。每个研究和其对应的标签在附录中的表9中列出。
本文对每篇文献都设置了唯一的ID并在附录的表8中列出,文献ID(paper ID,PID)被用于代表每个相关的一级研究,往往在该研究中的范例都非常的灵活,能够适应所有的已标注研究,这一部分将在第5节中详述。
6 出版趋势
入选的94篇一级研究中,57%是会议出版的,25%是期刊出版的,18%是书籍章节。图5为研究的趋势,最早的研究是2005年的。从2013年开始期刊出版的文献增长迅速,会议文献和书籍章节数量逐渐降低,这一结果和某综述的结论相似。
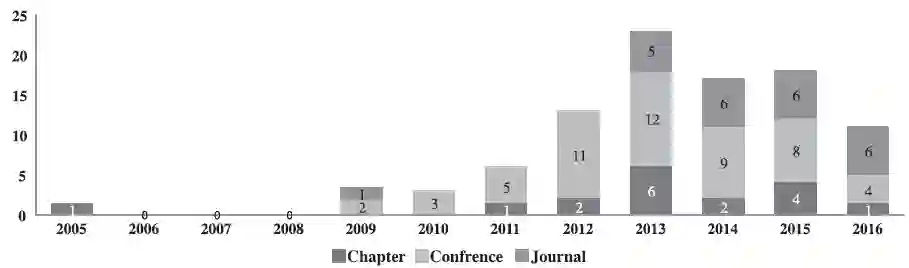
图5 一级研究趋势
7 数据提取
标注一级研究后,进行数据提取过程,在此过程中,每篇一级研究都被下载下来并赋予一个文件ID。根据表2中的ID创建表格,其中每一列代表组号(CG1A,CG1B等)。对每个一级研究,相关标签的信息被收集并被放入各自的文件中。附加信息如数据集信息,分析方法,比较算法,未来工作和结论等也被存放在每个文件表格各自的列中。提取出的数据被用来进行分析,相关内容在下一节进行详述。
扫描下方二维码加入跨领域推荐系统述讨论群

感谢内容伙伴雷智文推荐并翻译本文
内容伙伴持续招募中,有意者联系微信号"前沿讲习班小助手(ID:must-tech)"

历史文章推荐:
AI综述专栏 | 11页长文综述国内近三年模式分类研究现状(完整版附PDF)
AI综述专栏 | 朱松纯教授浅谈人工智能:现状、任务、构架与统一(附PPT)
【AIDL专栏】罗杰波: Computer Vision ++: The Next Step Towards Big AI



