基于对比学习的推荐算法总结
今天我们来聊一聊推荐系统中不得不学的Contrastive Learning方法,近年来Contrastive Learning在CV和NLP领域的应用越来越广泛,在推荐系统中当然也不例外。我想大家将对比学习与推荐系统结合主要有以下四个原因:
一、是因为数据的稀疏性。众所周知,在推荐系统中有点击的数据是非常少的,可能系统推荐了十篇文章,用户只点击了一篇文章,因此我们可以通过自监督学习对点击数据进行增强;
二、是因为item的长尾分布。主流商品往往代表了绝大多数用户的需求,而长尾商品往往代表了一小部分用户的个性化需求,若要对用户行为很少的长尾商品进行推荐,也可以通过自监督进行增强;
三、是因为在跨域推荐中若有多个不同的view,可以通过自监督学习融合多个view的信息,而非动态的线性加权,增强网络的表达能力;
四、是因为增加模型的鲁棒性或对抗噪音,可以通过一些例如Mask和Droupout的方法。
那我们今天就一起讨论一下Contrastive Learning在推荐系统中的主流做法和前沿应用。
1.DHCN

论文标题:Self-Supervised Hypergraph Convolutional Networks for Session-based Recommendation
论文方向:会话推荐
论文来源:AAAI2021
论文链接:https://arxiv.org/abs/2012.06852
论文代码:https://github.com/xiaxin1998/DHCN
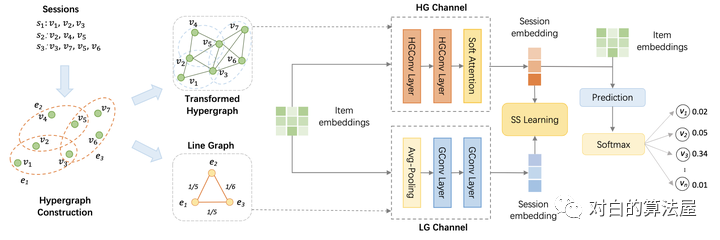
Session-based recommendation (SBR) 也就是会话推荐主要的任务就是基于目前已有的多个用户物品交互序列,完成 next-item 预测。在这种情况下,用户配置文件不可用,因此从多个用户物品交互序列中提取用户意图嵌入就格外重要。
基于此本文将会话数据建模为超图,提出了一种双通道超图卷积网络DHCN。同时本文为了增强超图建模,创新性地将自监督学习融入到网络训练中,最大化通过 DHCN 中两个通道学习的会话表示之间的互信息,作为改进推荐任务的辅助任务。
超图定义
超图的定义:一条超边
线图定义
将超图中的每个边(即每个用户的session)看作是一个节点,而任意两个节点之间的边权重看作是这两个用户session的相似度,计算为
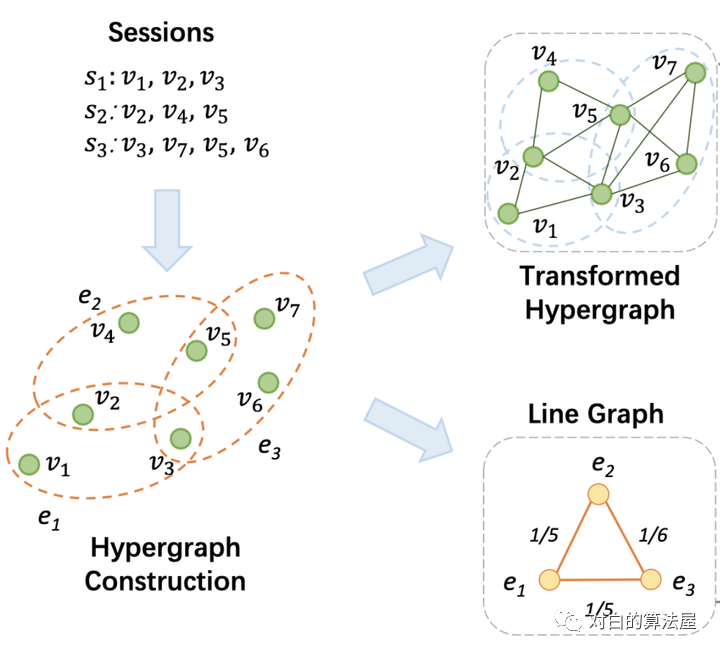
构建超图
因为超图定义为超边可以包含多个节点,因此这些节点可以被看作是通过共同的边而互相连接,因此每个用户的session或者超边将构成一个完全子图,且该子图中的边权重都相等(因为共享同一条超边)。而对应的线图则是一个完全图,任意两个节点(session)的边权重说明了这两个用户session的相似程度。
超图卷积
包含多个超图卷积层,用于items-embedding的传播和更新,描述为:涉及同一条超边的两个节点进行消息传递,因此在构建好的超图上就是相邻的两个节点进行传播(因为它们涉及共同的超边,或者共同出现在某个用户的session中):
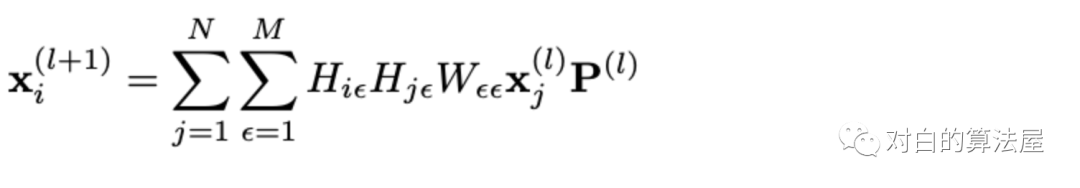
矩阵表达形式为:
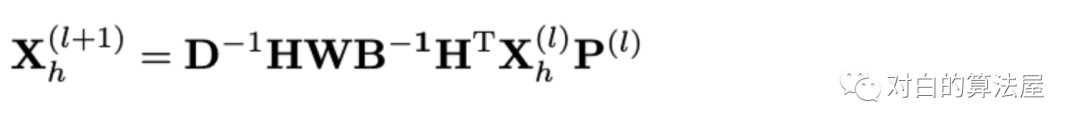
注意上述操作没有涉及序列特征,为此作者引入一个可训练的位置编码矩阵
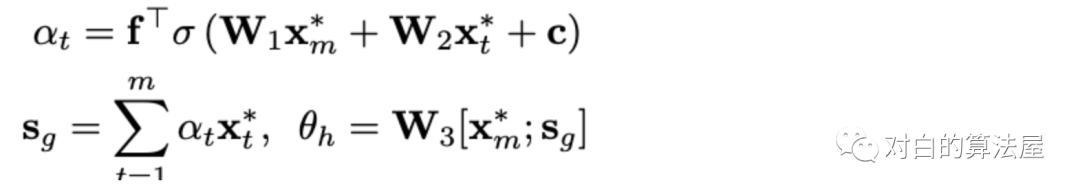
其中
预测部分就是常规的训练,计算session-embedding
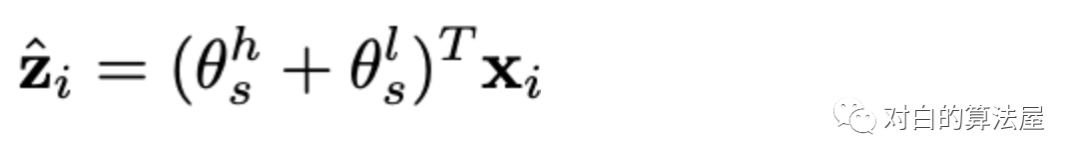
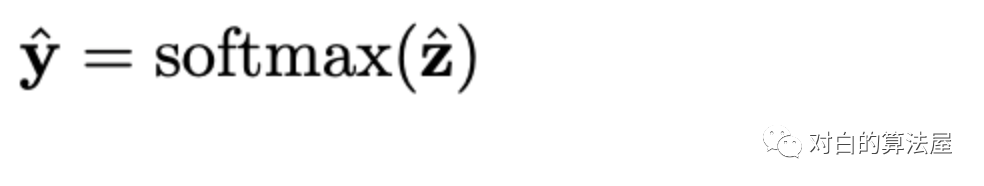
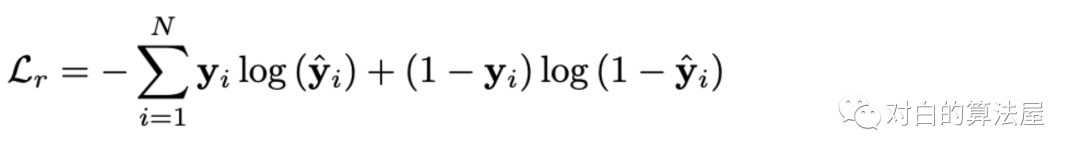
自监督学习增强DHCN
超图建模使模型能够实现良好性能。作者认为会话数据的稀疏性可能会阻碍超图建模,这将导致次优推荐性能。受自监督学习在简单图上的成功实践的启发,作者将自监督学习集成到网络中以增强超图建模。利用自监督信号进行学习被视为有利于推荐任务的辅助任务,它分为两个步骤:
创建自监督信号
在DHCN中,通过这两个通道学习两组特定于通道的会话Embedding。由于每个通道编码一个超图,该图只描述由会话诱导的超图的物品级(插入)或会话级(会话间)结构信息,所以两组Embedding对象彼此了解很少,但可以互补。在训练中,两组会话Embedding之间有一个客观映射。简单地说,这两组映射可以成为彼此的基础用于自监督学习,这种一对一的映射被视为标签的增广。如果两个会话Embedding在两个视图中都表示同一个会话,就将这一对标记为 ground-truth,否则将其标记为 negative。
对比学习
通过创建自监督信号,利用互信息最大化原则对两个图得到的表示进行对比,以及对线图卷积得到的embedding使用row-wise and column-wise shuffling后得到负样本,即增大两个角度session-embedding之间的一致性:
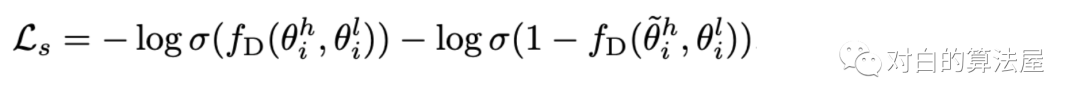
最后的损失函数为两部分之和:

总结文本的创新点如下:
为 SBR 任务提出了一种双通道超图卷积网络 DHCN,通过超图建模,可以捕获项目之间的超配对关系和交叉会话信息。
-
首次将自监督学习学习的概念放入到推荐任务的网络训练中,自监督学习可以加强模型的表达能力和推荐任务的完成效果。
2.MHCN

论文标题:Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation
论文方向:社交推荐
论文来源:WWW2021
论文链接:https://arxiv.org/abs/2101.06448
论文代码:https://github.com/Coder-Yu/QRec
在推荐系统中,当用户-物品交互数据比较稀疏时,通常使用社交关系来提高推荐质量。大多数现有的社交推荐模型利用成对关系来挖掘潜在的用户偏好。然而,现实生活中用户之间的互动非常复杂,用户关系可能是高阶的。超图提供了一种自然的方法来建模复杂的高阶关系,而它在改善社交推荐方面的潜力还有待开发。
在本文中,作者提出了一个多通道超图卷积网络(MHCN),利用高阶用户关系来增强社交推荐。从技术上讲,网络中的每个通道都通过超图卷积来编码一个超图,该超图描绘了一个常见的高阶用户关系模式。通过聚合多个通道学习到的Embedding,可以得到全面的用户表示,从而生成推荐结果。
然而,聚合操作也可能掩盖不同类型的高阶连接信息的固有特征。为了弥补聚合损失,作者将自监督学习融入超图卷积网络的训练中,以获得层次互信息最大化的连通性信息。
现有的自监督学习(SSL)方法主要用于训练来自人工平衡数据集(如ImageNet)的表示模型。目前还不清楚它们在实际情况下的表现如何,在实际情况下,数据集经常是不平衡的。基于这个问题,作者在训练实例分布从均匀分布到长尾分布的多个数据集上,对自监督对比学习和监督学习方法的性能进行了一系列的研究。作者发现与具有较大性能下降的监督学习方法不同的是,自监督对比学习方法即使在数据集严重不平衡的情况下也能保持稳定的学习性能。
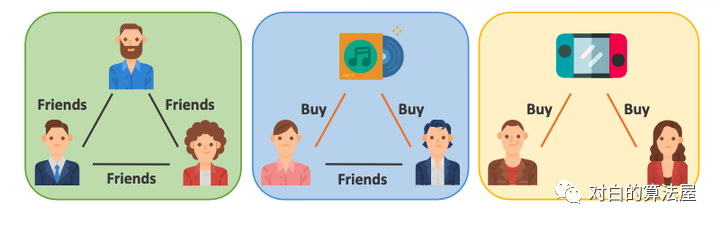
社交推荐系统中常见的高阶用户关系类型(引自MHCN论文)
构建超图
超图,它推广了边的概念,使其连接到两个以上的节点,为建模用户之间复杂的高阶关系提供了一种自然的方法。作者通过统一形成特定三角形关系的节点来构造超图,这些三角关系是一组精心设计的具有底层语义的三角主题的实例,如下图所示:

从左到右为图M1 ~ M10,我们根据其隐含的语义将其分为三组。M1~M7概括了显性社交网络中所有可能的三角关系,并描述了高阶社交连接,比如“有一个共同的朋友”,我们称之为“Social Motifs”。M8~M9表示联合关系,即“朋友购买同一件物品”。这种类型的关系可以看作是加强联系的信号,我们将M8 ~ M9命名为“Joint Motifs”。最后,我们还应该考虑那些没有显性社交关系的用户。因此,M10是非封闭的,它定义了没有社交关系但购买了相同物品的用户之间的隐性高阶社会关系。我们将M10命名为“Purchase Motif”。在这三种模态的约束下,我们可以构造出包含不同高阶用户关系模式的三个超图。
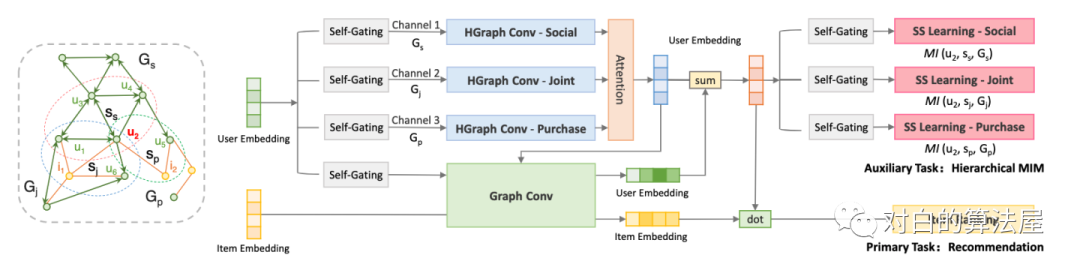
MHCN框架图(引自MHCN论文)
多通道超图卷积
在本文中,作者使用了三种通道设置,包括“社交通道(s)”、“联合通道(j)”和“购买通道§”,以应对三种类型的三角形主题,但通道的数量可以调整,以适应更复杂的情况。每个通道负责编码一种高阶用户关系模式。因为不同的模式可能会对最终的推荐性能表现出不同的重要性,所以直接将整个基本的用户嵌入Embedding提供给所有通道是不明智的。为了控制从基本的用户Embedding到每个通道的信息流,作者设计了一个具有自门控单元(SGU)的预过滤器,其定义为:
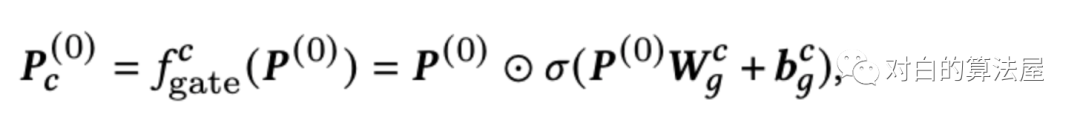
超图卷积定义为:
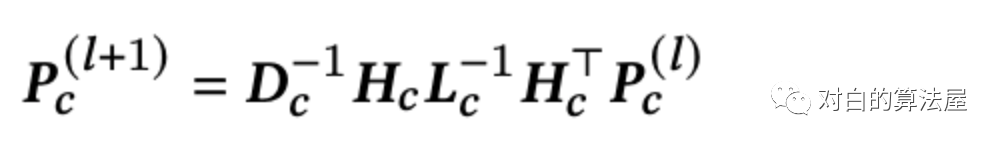
超图卷积可以看作是对超图结构进行“节点-超边-节点”特征变换的两阶段精化。乘法运算
通过降低计算代价(感兴趣的可以阅读原文获悉),我们将变换后的超图卷积定义为:
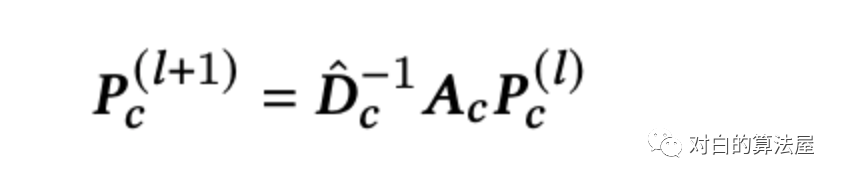
学习全面的用户表示
在通过𝐿层传播用户嵌入后,我们平均每一层获得的Embedding,以形成最终的特定于通道的用户表示:
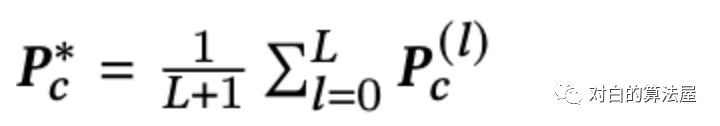
为了避免过度平滑问题,然后我们利用注意力机制对不同通道的用户嵌入信息进行选择性聚合,形成全面的用户嵌入。对于每个用户𝑢,我们学习了一个三元组(𝛼𝑠、𝛼𝑗、𝛼𝑝)来测量三个特定于通道的嵌入对最终推荐性能的不同贡献。注意力函数
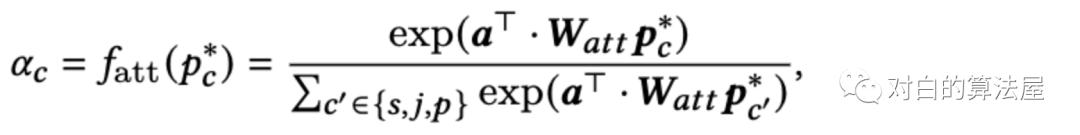
全面的用户表示定义为:
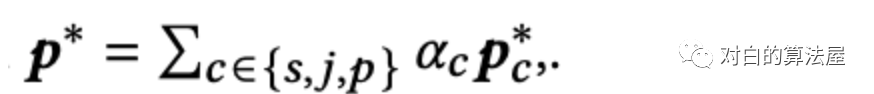
自监督学习增强MHCN
由于利用了高阶关系,MHCN表现出了很好的性能,然而,MHCN的一个缺点是聚合操作可能会导致高阶信息的丢失,因为不同的通道会在不同的超图上学习不同分布的Embedding。为了解决这个问题,并充分继承超图中丰富的信息,我们将自监督学习融入到MHCN的训练中。
创建自监督信号
对于MHCN的每个通道,我们建立邻接矩阵𝑨𝑐,以捕获高阶连接信息。𝑨𝑐中的每一行都表示以行索引表示的用户为中心的相应超图的子图,然后我们可以引出一个层次结构:“用户节点←以用户为中心的子超图←超图”,并从该结构创建自监督信号。
作者引入自监督任务的目标是:全面的用户表示应该反映用户节点在不同超图中的局部和全局的高阶连接模式,可以通过分层最大化用户表示、以用户为中心的子超图和每个通道中的超图之间的互信息来实现这一目标。
对比学习
Deep Graph Infomax (DGI)是一种通用和流行的方法,用于自监督的方式学习图结构数据中的节点表示。我们遵循DGI,使用InfoNCE作为我们的学习目标,以最大化层次互信息。但我们发现,与二元交叉熵损失相比,成对排序损失(在互信息估计中也被证明是有效的)更适合推荐任务。因此定义自监督任务的目标函数如下:
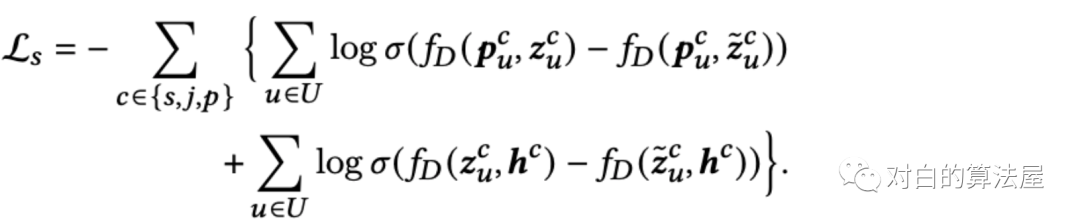
最后,我们将推荐任务的目标(主要的)和最大化层次互信息的任务(辅助的)统一起来进行联合学习。总体目标函数定义为:
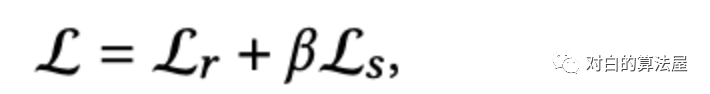
本文的主要贡献总结如下:
研究了通过利用多通道设置下的多种高阶用户关系,在社交推荐中融合超图建模和图神经网络。
将自监督学习融入到超图卷积网络的训练中,证明了一种自监督辅助任务可以显著改善社交推荐任务。
3.SGL

论文标题:Self-supervised Graph Learning for Recommendation
论文来源:SIGIR2021
论文链接:https://arxiv.org/abs/2010.10783
论文代码:https://github.com/wujcan/SGL
这篇文章提出了一种应用于用户-物品二分图推荐系统的图自监督学习框架。核心的思想是,对输入的二分图,做结点和边的dropout进行数据增强,增强后的图可以看做原始图的子视图;在子视图上使用任意的图卷积神经网络,如LightGCN来提取结点的表征,对于同一个结点,多个视图就能形成多种表征;然后借鉴对比学习的思路,构造自监督学习任务,即:最大化同一个结点不同视图表征之间的相似性,最小化不同结点表征之间的相似性;最后对比学习自监督任务和推荐系统的监督学习任务联合起来,构成多任务学习的范式。
文章的方法很简洁,这种思想和陈丹琦的工作,基于对比学习的句子表征SimCSE有异曲同工之处,值得借鉴到实际的图表征学习中。
解决目前基于user-item二分图表征学习的推荐系统面临的两大核心问题:
长尾问题。high-degree高度的结点对表征学习起了主导作用,导致低度的结点,即长尾的item的学习很困难。
鲁棒性问题。交互数据中包含着很多噪声。而基于邻域结点汇聚的范式,会扩大”噪声观测边”的影响力,导致最终学习的表征受到噪声交互数据的影响比较大。
因此,作者提出了图自监督学习的方法SGL,来提高基于二分图推荐的准确性和鲁棒性。
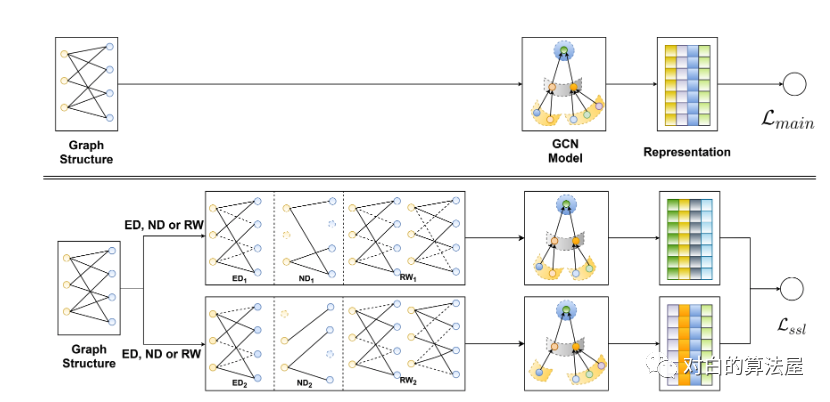
SGL的总体系统框架(引自SGL论文)
图结构上的数据扩充
由于以下特定特征,直接在基于图的推荐中采用CV和NLP任务中的数据增强是不可行的。
用户和物品的特征是离散的,如one-hot ID等分类变量。因此,图像上的增强操作,如随机裁剪、旋转或模糊,是不适用的。
更重要的是,与将每个数据实例视为独立的CV和NLP任务不同,交互图中的用户和项目本质上是相互连接和依赖的。因此,我们需要为基于图的推荐定制新的增强运算符。
二部图建立在观察到的用户-物品交互上,因此包含协同过滤信号。具体来说,第一跳邻近节点直接描述了自我用户和项目节点,即用户的历史项目(或项目的交互用户)可以被视为用户(或项目)的预先存在特征。用户(或项目)的第二跳邻近节点表示类似用户(或类似项目)。此外,从用户到商品的higher-order路径反映了用户对商品的潜在兴趣。毫无疑问,挖掘图结构中的固有模式有助于表示学习。因此,作者在图结构上设计了三个算子:node dropout, edge dropout 和 random walk,以创建不同的节点视图。运算符可以一致表示为:
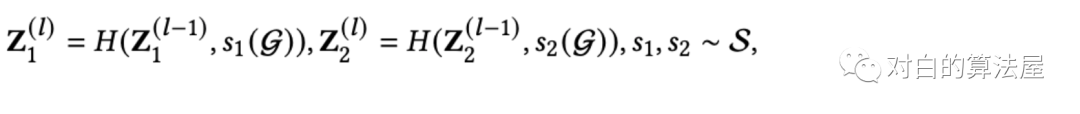
其中,在图G中独立进行随机选择s1和s2,从而构建两个相关视图Z1(l)和Z2(l)。三个增广算子详细阐述如下:Node Dropout (ND):以概率ρ从图中丢弃每个节点及其连接边。
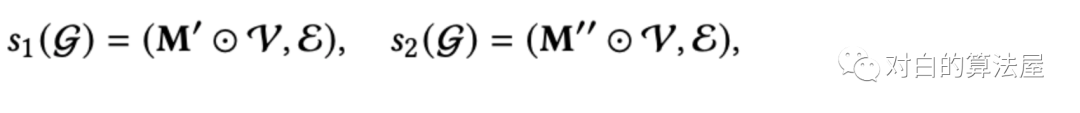
式中,M`, M``∈{0,1} | V |是两个掩码向量,应用于节点集V生成两个子图。因此,这种增强可以从不同的增强视图中识别出有影响的节点,使表示学习对结构变化不那么敏感。Edge Dropout (ED):以概率ρ从图中丢弃边。
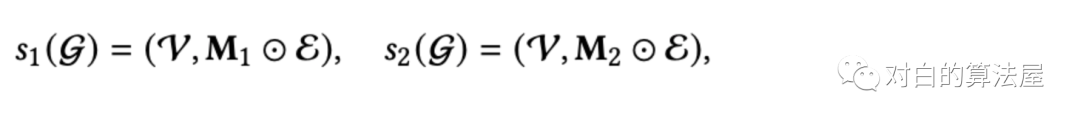
其中M1, M2∈{0,1} | E |是边集E上的两个掩码向量。只有邻域内的部分连接对节点表示有贡献。因此,耦合这两个子图的目的是捕获节点局部结构的有用模式,并进一步赋予表示对噪声交互的更强的鲁棒性。
Random Walk :上面的两个算子生成一个跨所有图卷积层共享的子图。为了探索更高的性能,作者考虑为不同的层分配不同的子图。这可以看作是使用随机游走为每个节点构造单独的子图。假设在每一层(有不同的比例或随机种子)选择edge dropout,则可以通过利用边掩蔽向量对层敏感来制定RW(如下图所示):
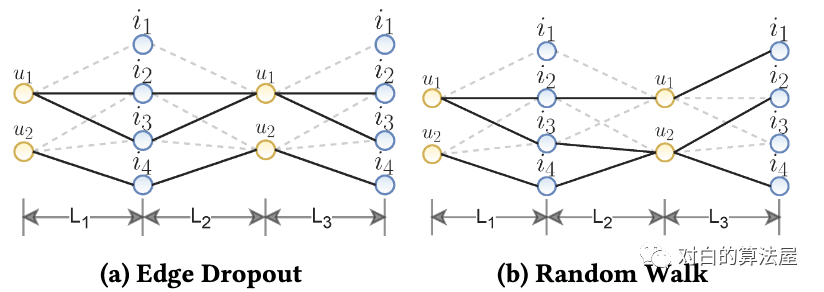
为了简单起见,作者在图结构的每个epoch上应用这些增强,也就是说,在一个新的训练epoch开始时,对每个节点生成两个不同的视图(对于RW,每层生成两个不同的视图)。请注意,对于两个独立进程(即s1和s2), dropout和masking比率是相同的。我们将不同比例的调整留到以后的工作中。值得一提的是,只涉及到dropout和masking操作,并且没有添加任何模型参数。
对比学习
将来自同一节点的增强视图视为正例,来自不同节点间的增强视图视为负例。正例辅助监督促进了同一节点的不同视图之间的预测一致性,而负例监督则强化了不同节点之间的分歧。形式上,遵循SimCLR,并采用对比损失InfoNCE来最大化正例的一致性,最小化负例的一致性:
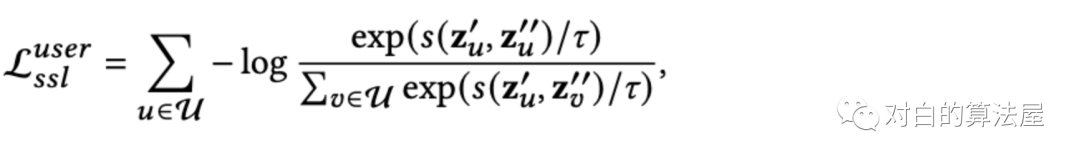
项目上的损失如上类似构建。最终的自监督任务损失如下:
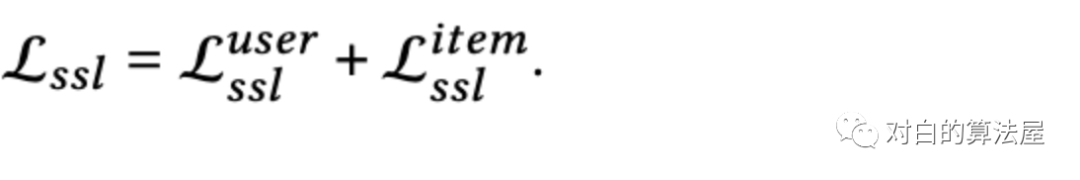
多任务学习
为了改进自监督学习任务的推荐,作者利用多任务训练策略联合优化经典推荐任务和自监督学习任务:
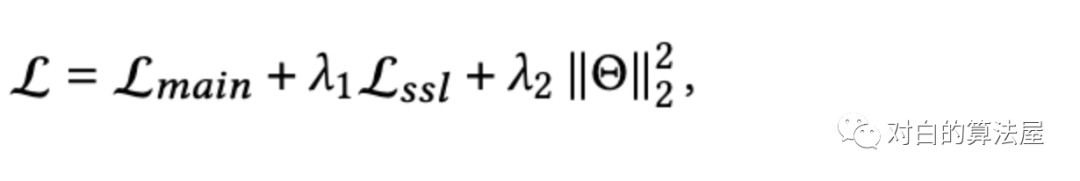
本文的主要贡献总结如下:
探索了自监督学习解决监督学习范式下基于图推荐的局限性的潜力;
提出了一个模型无关的框架SGL来补充监督推荐任务与自监督学习的用户-项目图;
从图结构的角度,设计了三种不同方面的数据扩充来构建辅助对比任务。
下面给大家留一个讨论题,希望大家踊跃发表意见,让我们所有人都从讨论中受益:
除了DHCN、MHCN和SGL,你还知道哪些将对比学习与推荐系统结合的模型,它们是如何将自监督应用在推荐任务中的,损失函数又是什么样的?



