多视图多行为对比学习推荐系统
作者:吴贻清
单位:中科院计算所
研究方向:多行为推荐
多行为推荐(MBR)旨在联合考虑多种行为以提高目标行为的推荐效果。我们认为 MBR 模型应该:(1)对用户不同行为之间的粗粒度共性进行建模,(2)在多行为建模中同时考虑局部的序列视图和全局图视图,以及(3)捕获细粒度的用户的多种行为之间的差异。在这项工作中,我们提出了一种新的多行为多视图对比学习推荐(MMCLR)框架,包括三个新的对比学习任务,分别用于解决上述挑战。
多行为对比学习旨在使同一用户在每个视图中的不同用户单行为表示相似。多视图对比学习试图对其用户的序列视图和图形视图表示。行为区分对比学习侧重于对不同行为的细粒度差异进行建模。在实验中,我们进行了广泛的实验和消融测试,验证了 MMCLR 和设计的各种对比学习任务在两个真实世界数据集上的有效性,相比于现有的基线实现了SOTA性能。
本文基于DASFAA 2022论文《Multi-view Multi-behavior Contrastive Learning in Recommendation》,论文作者来自中科院计算所,微信,北航。

论文: https://arxiv.org/pdf/2203.10576
背景介绍
个性化推荐旨在根据用户的喜好为用户提供合适的物品。个性化推荐的核心问题是如何从用户行为中准确捕捉用户偏好。在现实世界的场景中,用户通常有不同类型的行为来与推荐系统进行交互。例如,用户可以对电子商务系统(例如,亚马逊、淘宝)中的物品进行点击、加购物车、购买等行为,在社交推荐系统中(例如 推特,微博)可以进行点赞,分享,评论等行为。一些传统的推荐模型经常依赖单一的行为进行推荐。但是在实际系统中这样可能存在严重的数据稀疏性和冷启动问题,尤其当目标行为是高成本低频的行为。在这种情况下,其他行为(例如,点击,加购物车)可以为理解用户偏好提供额外的信息,从不同方面反映用户多样化和多粒度的偏好。
多行为推荐(MBR)综合考虑了不同类型的行为,因而能更好的学习到用户的偏好。多行为推荐在其它工作中得到了广泛的探索和验证。但是MBR仍然存在三个挑战:
如何对用户行为之间的粗粒度共性进行建模?用户的所有类型的行为都从某些方面反映了该用户的偏好,因此这些行为天然具有一些共性。考虑不同行为之间的共性可以帮助学习更好的用户表示来对抗数据稀疏问题。这一点在现有的 MBR 模型中经常被忽略。然而,如何通过用户不同类型的行为提取其中的共性信息是一个有挑战性的工作。
如何联合考虑用户个体和全局的视图?传统的 MBR 模型通常只采用一种视图(图视图或序列视图)。序列视图往往更关注于用户个体层面的兴趣演化。相比之下,图视图通常专注于从整个系统中的协同信息来探索用户的兴趣。从不同层次考虑用户兴趣并应用相应的建模方法(基于序列和基于图),能够从不同的方面捕获用户的兴趣。他们相互补充,有助于提升MBR的推荐效果。
如何学习用户多行为之间的细粒度差距?一个用户不同类型的行为之间除了粗粒度的共性之外,还存在细粒度的差异。在目标行为和其它行为之间通常存在着优先级(例如购买的优先级通常高于点击)。在现实世界的电子商务数据集中,用户的平均点击数通常是平均购买次数的 7 倍以上,因而存在大量点击但未购买的商品。将点击未购买的物品视为更加难的负样本,可以让模型学习到阻止用户购买的原因。现有的作品很少考虑多种行为之间的差异,我们想要将这种差异编码到用户的多行为表示中。
近几年,对比学习(CL)在推荐系统中展现了它的力量,它极大地缓解了数据稀疏和流行度偏差问题。我们发现对比学习天然适用于对多行为和多视图用户表示之间的粗粒度共性和细粒度差异进行建模。为了解决上述挑战,我们提出了一种新颖的多行为多视图对比学习推荐(MMCLR)框架。具体来说,MMCLR 包含一个序列编码模块和一个图编码模块,分别用于学习用户多行为下的用户表示。我们针对现有挑战设计了三个对比学习任务,包括多行为对比学习、多视图对比学习和行为区别对比学习。他们建模了用户多行为和多视图之间的复杂关系,从而能够学习到更好的用户表示。
多行为对比学习:我们在每一个视图下的不同行为之间设置对比学习任务。它假设从同一用户的不同行为中学习到的用户表示与其他用户的表示相比应该更接近,其目的是提取不同类型行为之间的共性。
多视图对比学习:我们在两个视图中的用户表示之间进一步的设置对比学习任务。它帮助建模了基于序列的用户的局部信息,和基于图的用户的全局信息之间的共性信息,并对其他们的表示。从而可以提升图编码器和序列编码器的效果。
多行为区分对比学习:与多行为对比学习不同,多行为区分对比学习致力于建模不同行为之间的细粒度的差异,而不是粗粒度的共性。它专门用于捕获用户针对于目标行为的细粒度偏好。
通过这三种对比学习任务,MBR可以更好的理解用户不同行为之间的共性和差异,此外可以更好的建模不同视图之间的关系,从而提高对目标行为的推荐效果。
方法
如下图所示,我们的模型包含三大块,多视图编码器,多行为融合器,和多视图融合器三部分组成。此外在每一部分中我们分别在内部设置了多行为对比学习,多视图对比学习,行为区分对比学习三个任务,以帮助模型学习到更好的表示。具体的方法如下:
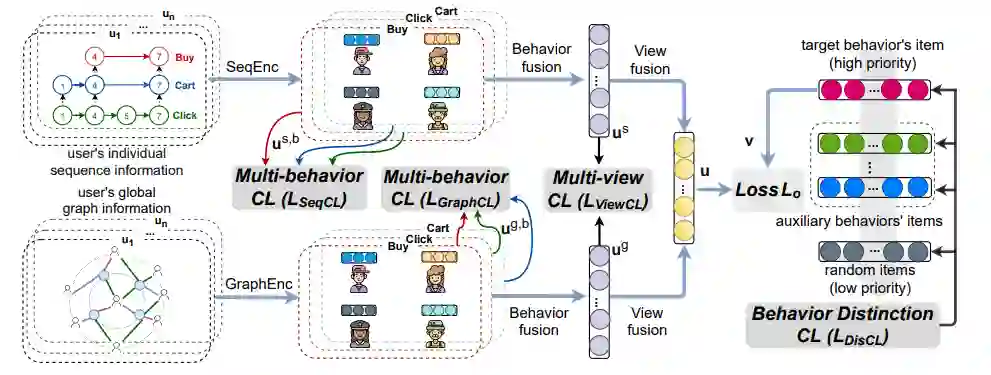
(2)多视图编码器:在构造好不同的视图后,他们分别被送入序列编码器和图编码器。这里图编码器和序列编码器可以灵活选择,在本文中我们采用经典的Bert4Rec和LightGCN分别作为序列编码器和图编码器。通过编码器我们可以得到在每个视图下每个行为的表示:

这里 u^{s,b} ,u^{g,b} 分别为用户在序列和图视图下关于行为b的编码表示。
我们针对不同的用户行为应用多行为对比学习,其核心是一个用户的不同行为之间的表示应当要比另一个用户更加接近,因为用户的不同行为均在某种程度上表示了用户的兴趣片偏好。这样我们得到辅助loss:L_{seqcl} 和L_{graphcl} :
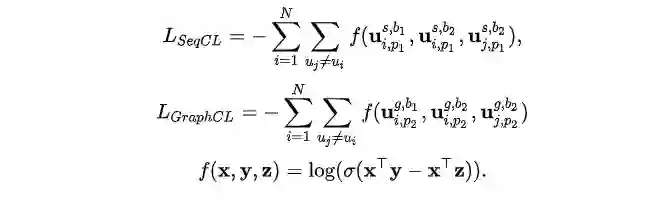
(3)多行为融合器:在每个视图下,我们对每种行为进行编码后,将其送入多行为融合器,从而得到用户在每个视图下的综合表示。这里多行为融合器我们采用简单的2层MLP:
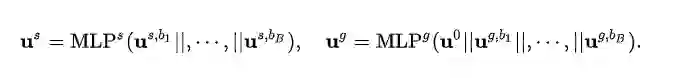
在得到不同视图的表示后,我们用图视图和序列视图的表示做对比学习任务,其核心是同一个用户不同视图下的表示应当比另一个用户更为接近,这样我们得到辅助loss: L_{viewcl}
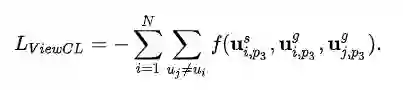
(4)多视图融合器: 在融合多行为后我们得到了用户在每个视图下的表示,我们进一步的将不同视图的表示进行融合,同样这里采用2层MLP进行融合。这样我们就得到了用户的最终表示:
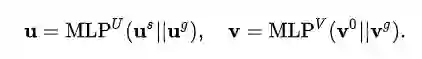
在得到用户的最终表示后。我们利用对比学习建模不同行为之间的细粒度差异。具体的按照不同行为的优先级,对于产生了高优先级行为的物品其打分要比低优先级要高。这里我们认为目标行为的优先级要高于辅助行为,辅助行为的优先级要高于随机采用的物品。通过多行为差异的对比学习模块我们得到了辅助loss L_{discl} :
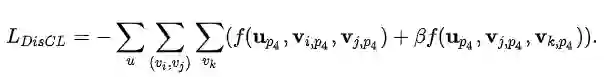
(5)最后三种对比学习任务所得到的loss和推荐loss L_0一起加权求和,并进行联合训练。
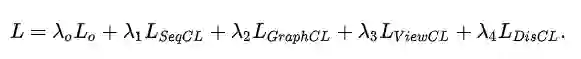
这里我们采用pair-wise排序loss作为推荐损失函数:
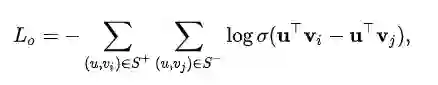
实验
我们在两个公开电商数据集数据集上做了实验,其中每个数据集都包括了点击,加购物车,收藏,购买四种行为。我们将购买行为作为目标行为。实验结果如下:
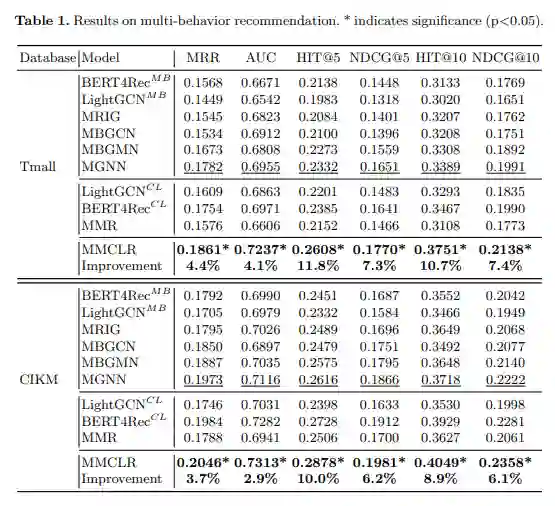
可以看到相对其它方法,我们的方法得到了显著的提升。MMR是我们去除对比学习的版本,我们可以看到如果去除对比学习任务,我们的方法会大幅下降。由此可以看到我们设计的对比学习方法能够显著的帮助模型建模用户多行为下的兴趣。
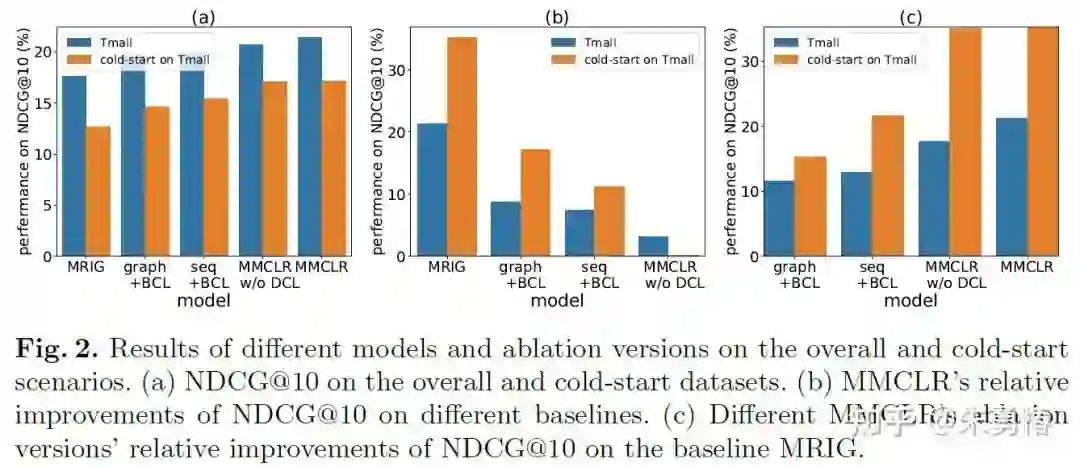
此外,我们还测试了冷启动条件下(用户目标行为小于3)的我们模型的推荐效果。其中BCL代表多行为对比学习,DCL代表多行为区别对比学习。首先从图(a)可以发现在冷启动条件下,推荐效果明显下降。其次从图(c)我们可以发现随着我们对比学习任务的增加,我们的模型相对于基线在冷启动上的相对提升要远大于整体。这可以说明我们的模型在数据越稀疏的条件下相对表现得越好。
总结
在这篇文章中,为了缓解用户高价值的目标行为稀疏的问题,我们利用用户的多行为信息来更好的建模用户偏好。具体的我们提出了一种多行为多视图的对比学习框架,他能够帮助模型更好的建模用户不同行为类型和不同视图的复杂关系。实验证明我们的模型能够显著的提升在目标行为上的推荐效果。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。



