CIKM2021 | 将对比学习用于解决推荐系统长尾问题
本文主要分享一下 Google 发表于 CIKM 2021 的文章如何采用对比学习解决推荐长尾问题。

论文标题:
Self-supervised Learning for Large-scale Item Recommendations
https://arxiv.org/abs/2007.12865

先来个定义

对比学习
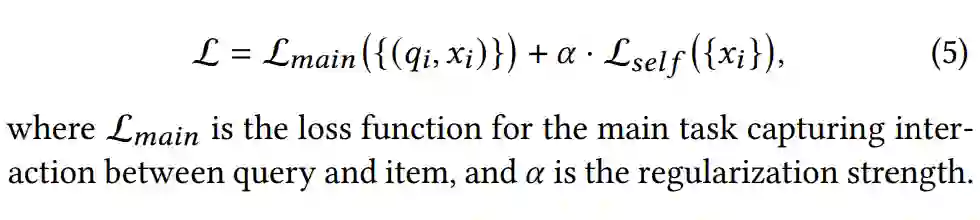

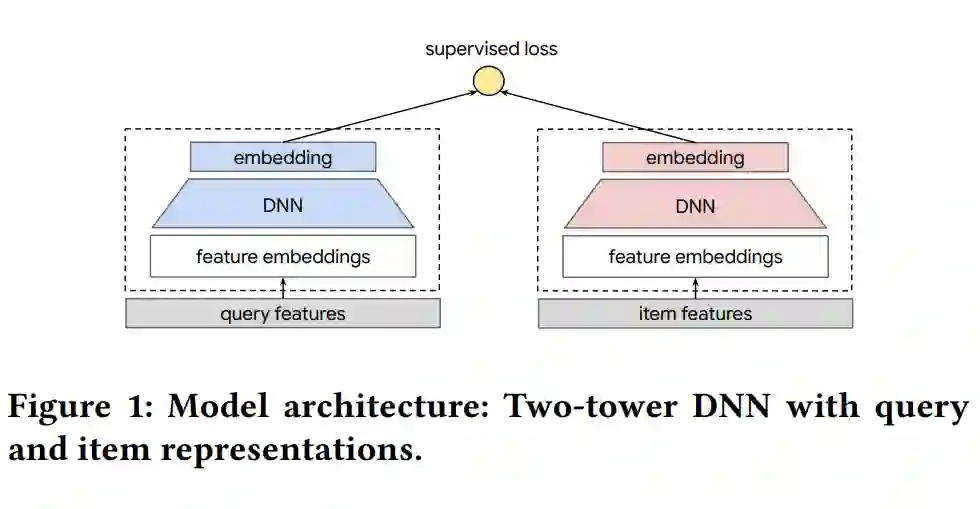
论文解读
3.1 数据增强
3.2 Random Feature Masking(RFM)
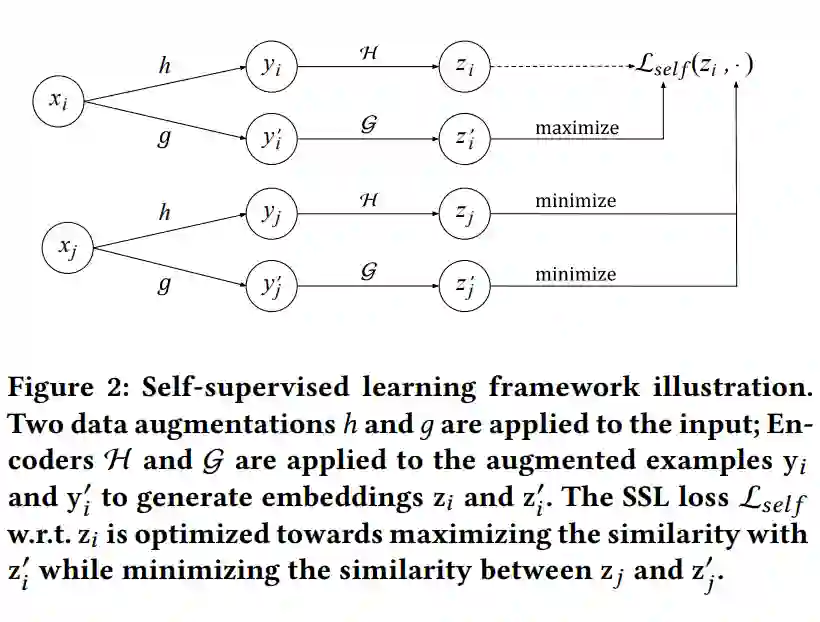
某个 item xi, 随机抽取一半的特征 h,得到变体 yi,再经过 Encoder H,得到向量 zi;保留剩下的另一半特征 g,得到变体 yi’,再经过 Encoder G,得到向量 zi’。
-
来自同一个 item xi 的两种变体对应的 embedding zi 和 zi’,两者之间的相似度应该越大越好。 -
按照同样的作法,另一个 item xj,用一半特征 h 得到变体,再经过 Encoder H 得到 yj;用另一半特征 g,得到变体,再经过 Encoder G 得到 yj’。 来自不同 item 的变体对应的 embedding,两者之间的相似度应该越低越好。
3.3 Correlated Feature Masking(CFM)
3.4 为什么采用 CFM
For instance, the SSL contrastive learning task may exploit the shortcut of highly correlated features
between the two augmented examples, making the SSL task too easy.
3.5 联合训练

参考资料
[1] 石塔西:少数派报告:谈推荐场景下的对比学习:https://zhuanlan.zhihu.com/p/435903339
[2] 推荐场景下的对比学习总结
[3] 基于对比学习的推荐算法总结
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
登录查看更多
相关内容

专知会员服务
10+阅读 · 2022年3月29日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
21+阅读 · 2019年5月11日




相关VIP内容
专知会员服务
10+阅读 · 2022年3月29日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日
Arxiv
21+阅读 · 2019年5月11日