【速览】TIFS 2022 | 通过标签感知机制检测 X 射线安全图像中的重叠对象
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
通过标签感知机制检测 X 射线安全图像中的重叠对象
*通讯作者:赵才荣
◆ ◆ ◆ ◆
X 光安检的主要挑战之一是在 X 光图像中检测背包或手提箱中的重叠物品。大多数现有方法通过增强颜色和边缘等底层视觉信息来提高模型对对象重叠问题的鲁棒性。但是,该策略忽略了对象与背景具有相似的视觉线索以及对象相互重叠的情况。由于这两种情况很少出现在现有的数据集中,我们公开了一个新的数据集——Cutters and Liquid Containers X-ray Dataset (CLCXray) 来进行相关研究。此外,我们提出了一种新的标签感知机制(LA)来解决对象重叠问题。特别的,LA 建立了特征通道和不同标签之间的关联,并根据分配的标签(或伪标签)调整特征,以帮助改进预测结果。实验表明,LA 在检测重叠对象方面是准确且稳健的,并且还验证了 LA 对于最先进 (SOTA) 方法的有效性和良好的泛化性。此外,实验结果表明,LA构建的网络优于OPIXray和CLCXray上的SOTA模型,特别是在有着高度重叠对象的子集上。
由于X光的成像原理,堆放在行李中的物品影像经常相互重叠。与光学图像中的遮挡问题不同,重叠的物体在X 光安检图像中仍然可见。然而,由于图像的重叠,对重叠物体检测受到干扰。根据重叠对象的不同,重叠问题可以分为三种类型,对象与无关背景的重叠,对象与相似背景的重叠,以及多个对象之间的重叠。以前的工作主要研究威胁品和无关背景之间的重叠。Liu等人[1]提出了一种两阶段方法,首先使用颜色信息从输入图像中分割出目标图像,然后对目标图像进行检测。Hassan等人[2]也提出了一种两阶段方法,首先使用轮廓信息从图像中分割出感兴趣区域(ROI),然后对ROI进行检测。Wei 等人[3]并没有从背景中分割对象,而是采用注意力机制使网络关注图像中物体的颜色和轮廓。此外,曹等人[4]提出使用局部外观来识别威胁对象,这需要额外的局部外观标签。然而,真实的场景是复杂的。在某些场景中,背景和物体的颜色相似,并且物体没有清晰可分离的轮廓。此外,不同对象之间存在重叠。在本文中,我们提供了一个新的数据集——刀具和液体容器的 X 光图像数据集(CLCXray)来进一步研究重叠问题。与OPIXray[3]不同,CLCXray更关注对象和相似背景之间的重叠,以及多个对象之间的重叠。 在类别上,CLCXray 数据集中有两大类威胁对象,刀具和液体容器,它们很普遍,但在之前的研究中被忽略了。CLCXray的样本如图 1 所示。

图 1 十二个类别的样本和对应的 X 光安检图像。CLCXray数据集包含各种刀具和可能存放易燃或易爆液体的容器
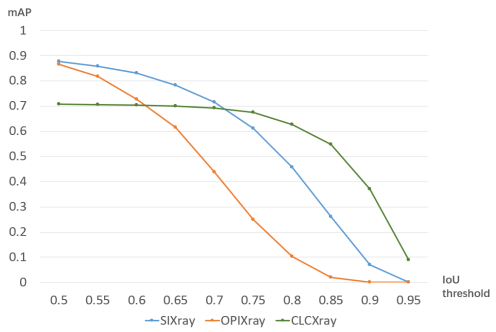
图 2 mAP随着 IOU 阈值的增加而减小的折线图
CLCXray 数据集包含 9,565 张X光安检图像,其中 4,543 张 X 光图像(真实数据)来自真实的地铁场景,另外5,022 张X光图像(模拟数据)由人工设计的行李扫描得到。CLCXray数据集中有12个类别,包括5种刀具和7种液体容器,5种刀具包括刀片、匕首、刀、剪刀、瑞士军刀。七种液体容器包括易拉罐、纸盒饮料、玻璃瓶、塑料瓶、真空杯、喷罐、锡罐。 CLCXray 数据集包含 20,000 多个潜在危险物品,每张 X 光图像平均包含两个以上的潜在危险物品。图像的分辨率在 373×200 和 732×1280 之间。

图 3 SIXray(A)、OPIXray(B)和CLCXray(C)三个数据集的检测框标签可视化
标签被制作成COCO格式。参考一般划分,CLCXray按照8:1:1的比例分为训练集、验证集和测试集。我们首先通过随机抽样构建模拟数据与真实数据比例为 1:9 的测试集。然后我们使用剩余的样本以 8:1 的比例形成训练集和测试集。测试集包含的真实样本比例(90%)远高于训练集和验证集中真实样本的比例(43%)。
与 GDXray、SIXray 和 OPIXray 相比,CLCXray 具有以下独特的特性:首先,CLCXray 中多个对象之间的重叠更多,这是因为平均每张图像的标记对象更多。CLCXray数据集中近 60%的X光图像包含至少两个或多个前景。在SIXray和OPIXray中,只有少数X光图像包含多个对象。其次,CLCXray中的类别包含液体容器,这在以往的研究中是没有见过的。液体容器可能含有有毒、腐蚀性、易燃易爆的液体,这些液体很危险,但很容易被忽视。第三,CLCXray有更准确的bbox标注。图2显示了通过在不同数据集上训练和测试基线模型 ATSS [5]获得的折线图。OPIXray 和 SIXray 上发生的急剧下降表明模型难以从框注释中学习准确定位。此外,我们将不同数据集的注释可视化,如图 3 所示。与 SIXray 和 OPIXray 相比,CLCXray 的注释在视觉上更贴合对象边缘。
图4显示了真空杯(A)、塑料瓶(B)和未标记的键盘(背景)之间的重叠。P是位于绿色网格中的采样点。由于P在重叠区域中,因此P从A、B和背景中提取低级视觉特征。当P负责预测A时,来自B和背景的信息是冗余的。而当P负责预测B时,来自A和背景的信息是多余的。冗余信息导致P的高级特征接近特征流形上的决策边界。标签感知方法(LA)思想在于根据分配给P的标签信息区分冗余信息,并通过生成权重的方式调整高层特征以使P远离特征流形上的决策边界。标签信息可以分为类别和回归,因此LA机制有基于类别的实现(LAcls)和基于回归的实现(LAreg)。

图 4 重叠示意图。图像上的每个网格对应于特征图上的一个采样点,黄色框和蓝色框定位了两个重叠的对象。
红色框定位了一个未标记的对象(背景)
在基于类别的方法设计中,我们最初的想法是让网络直接通过分配标签的类别和预测的多类置信度来学习用于调节特征图的权重。因此,LA的早期版本首先计算预测类别和类别标签的置信度的交叉熵,然后根据计算结果使用一组1x1卷积来学习权重。该方法的网络结构如图5(A)所示。虽然早期版本的LA可以提高模型的性能,但它不稳定,缺乏可解释性。为了让生成的权重能够合理地反映特征和标签之间的对应关系,我们利用了梯度。对于特定类别的预测置信度,特征图对应的梯度反映了特征图上不同位置的重要性,以提高置信度。因此,这个梯度与我们的目标是一致的。考虑到残差的形式有利于恒等映射,生成新特征图的公式有以下形式:
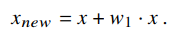
但是,预测不同类别所需的不同特征通道之间可能存在交集。增强公共特征不仅会增加对正确类别的置信度,还会增加对错误类别的置信度。为了抑制错误预测,我们根据除正确类别之外的最高置信度类别生成第二个权重。通过从第一个权重中减去第二个权重我们得到当前版本的LAcls,如图5(B)所示。
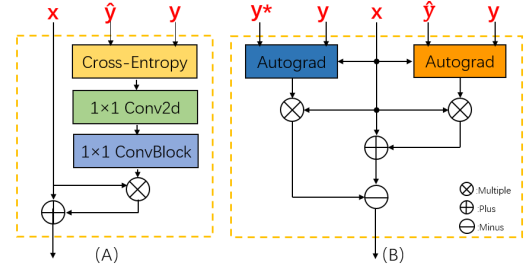
图 5 LA的早期版本(左)和最终版本的LAcls(右)
LAcls 生成的新特征图具有以下形式:
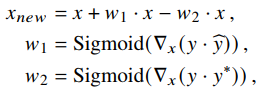
LA主要工作在训练阶段,使用分配的标签来调整特征。在测试阶段,标签不适用于 LA。为了解决这个问题,我们使用预测类别生成的伪标签来代替标签在测试阶段的作用。
与使用类别标签构建LA相比,使用回归标签更加困难。因为测试阶段使用的伪标签不能凭当前通用的回归形式生成。为了解决这个问题,我们参考了GFL[6]和Scope head[7] 的策略来修改回归分支。在网络中,我们首先将原来的回归表示改为FCOS[8]的回归表示,将中心点到bbox四个边界的四个距离进行回归。然后将预测四个方向的距离转化为预测距离值落在不同数值范围内的概率。通过以这种方式离散化回归量,我们可以采用与 LAcls 相同的策略来使用回归标签构造 LA。此外,该方法仍然可以通过计算期望值来获得四个方向上的连续预测距离。在我们的实验中,我们将最大距离设置为步幅的 16 倍,并将最大距离平均分成 16 个区间。在LAreg中,新的特征图由以下形式生成:
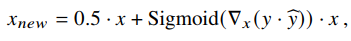
我们在OPIXray和CLCXray两个数据集上进行了实验。对于 OPIXray,我们采用 OPIXray [3]文中的评估指标,即在 0.50 的IoU阈值下计算的mAP。对于 CLCXray,我们采用 COCO 评估指标。结果如表1和表2所示所示。
表 1 在OPIXray数据集上的方法性能对比
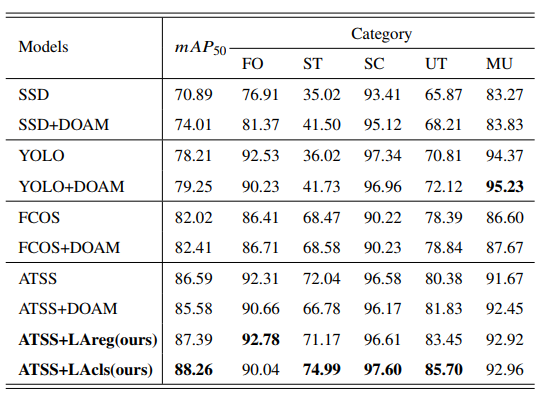
表 2 在CLCXray数据集上的方法性能对比
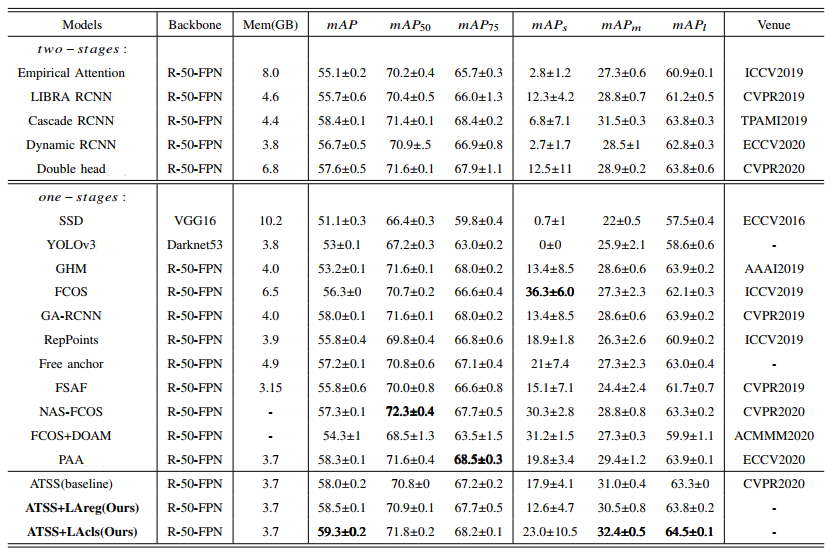
在OPIXray数据集中,我们使用ATSS作为基线,并测试它的性能。此外,我们测试了在ATSS上使用DOAM[3]、LAreg和LAcls的性能,其中DOAM是OPIXray文章中提出的方法。所有测试方法的配置与在CLCXray数据集上的配置一致。如表1的mAP50 所在列所示,ATSS比SOTA模型FCOS+DOAM高了4.17%。在这样的强基线上,LAcls将ATSS提高了1.67%。在CLCXray数据集中,我们测试了目前的SOTA模型FCOS+DOAM,以及近年来通用目标检测的先进模型。同样,我们使用ATSS作为基线并测试其性能。我们还测试了LA对ATSS 的改进。如表2的mAP列所示,基线 ATSS比FCOS+DOAM 高 3.7%。在这一强基线上,所提出的方法 LAcls将ATSS提升了1.3%的mAP,而LAreg对ATSS提升了0.6%的mAP。与相对早期的方法相比,各个方法在CLCXray上的提升较小,说明 CLCXray具有挑战性。此外,在所有模型中,ATSS+LAcls 在mAP上的得分最高。

图 6 可视化效果。左右图像来自同一组图像,分别由 ATSS 和 ATSS+LAcls 检测得到
图6显示了基线模型 ATSS 和模型 ATSS+LAcls 的可视化测试结果。如左侧的一组图像所示,有许多液体容器没有被成功检测到。这些液体容器通常要么与其他物体重叠,要么与背景非常相似。当物体与相似背景存在重叠时,采样点会提取过多的背景信息,从而导致对背景的预测。当多个对象之间存在重叠时,采样点提取了太多其他对象的特征,导致预测出其他对象的低质量检测框,然后这些预测框被后处理去除。在右侧的一组图像中,算法正确检测到了几个具有重叠问题的对象。同时,由于 LA 对特征进行了调整,检测到的对象通常对预测具有更高的置信度。实验数据和可视化结果表明,通过优化重叠区域采样点的特征提取,LA提高了模型对重叠问题的鲁棒性和准确性。
[1] J. Liu, X. Leng, and Y. Liu, “Deep convolutional neural network based object detector for x-ray baggage security imagery,” in 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2019, pp. 1757–1761.
[2] T. Hassan, S. H. Khan, S. Akcay, M. Bennamoun, and N. Werghi, “Cascaded structure tensor framework for robust identification of heavily occluded baggage items from multi-vendor x-ray scans,” arXiv preprint arXiv:1912.04251, 2019.
[3] Y. Wei, R. Tao, Z. Wu, Y. Ma, L. Zhang, and X. Liu, “Occluded prohibited items detection: An x-ray security inspection benchmark and de-occlusion attention module,” in Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 138–146. Munich, Germany, September 8-14, 2018, Proceedings, Part IV, ser. Lecture Notes in Computer Science, V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss, Eds., vol. 11208, 2018, pp. 501–518.
[4] S. Cao, Y. Liu, W. Song, Z. Cui, X. Lv, and J. Wan, “Toward human-in-the-loop prohibited item detection in x-ray baggage images,” in 2019 Chinese Automation Congress (CAC). IEEE, 2019, pp. 4360–4364.
[5] S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li, “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9759–9768.
[6] X. Li, W. Wang, X. Hu, J. Li, J. Tang, and J. Yang, “Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 632–11 641.
[7] G. Zhan, D. Xu, G. Lu, W. Wu, C. Shen, and W. Ouyang, “Scope head for accurate localization in object detection,” arXiv preprint arXiv:2005.04854, 2020.




