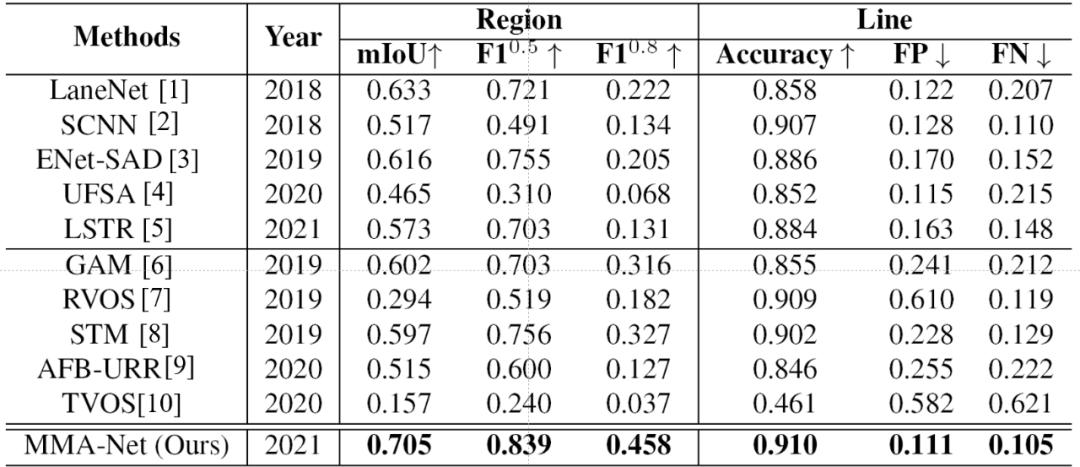
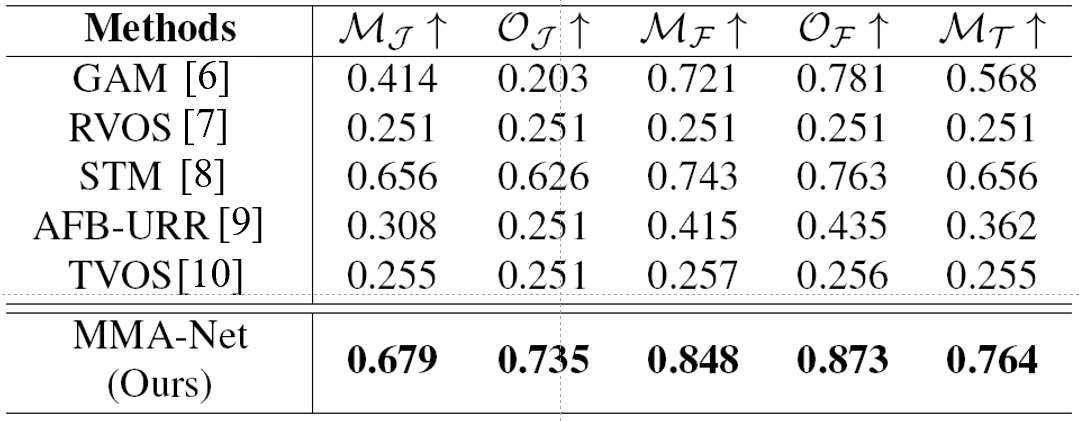
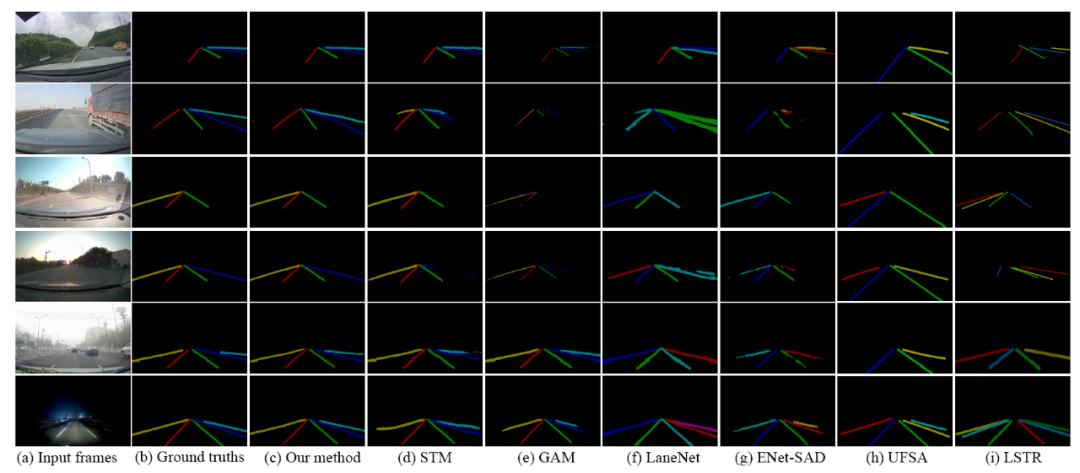
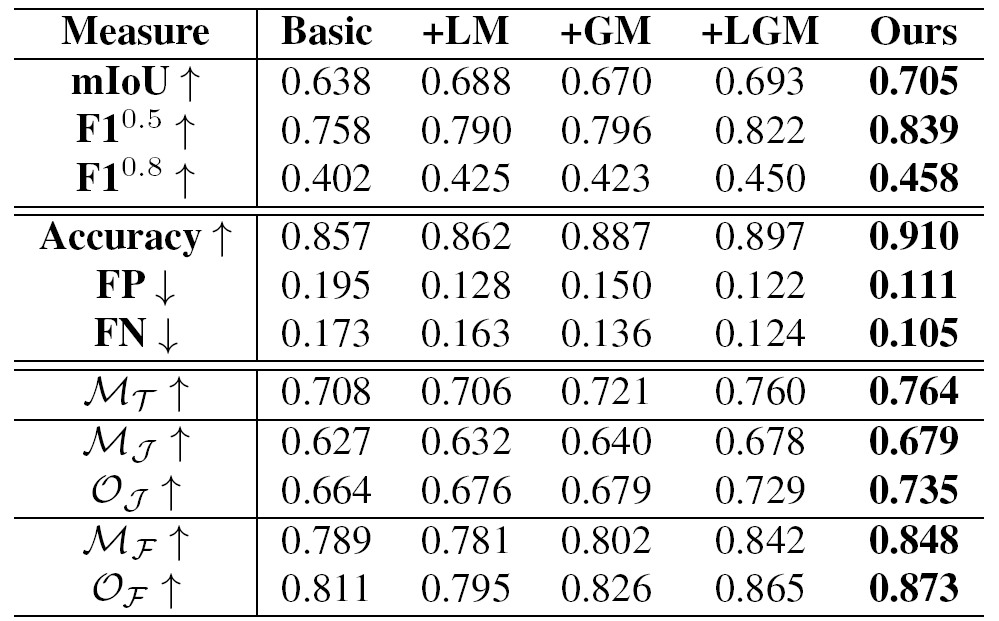
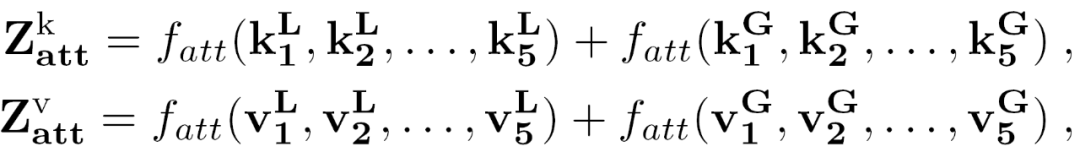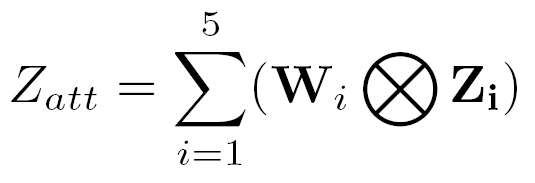推荐理事:林宙辰原文标题:VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection原文链接:https://arxiv.org/abs/2108.08482原文代码链接: https://github.com/yujun0-0/MMA-Net数据集链接:https://pan.baidu.com/s/1NkP_5LMLTn6qsu9pSbyi0g 提取码:iy16
参考文献
[1] Davy Neven, Bert De Brabandere, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool. Towards end-to-end lane detection: an instance segmentation approach. In IVS, pages 286–291, 2018.[2] Xingang Pan, Jianping Shi, Ping Luo, XiaogangWang, and Xiaoou Tang. Spatial as deep: Spatial cnn for traffific sceneunderstanding. In AAAI, pages 7276–7283, 2018.[3] Yuenan Hou, Zheng Ma, Chunxiao Liu, and ChenChange Loy. Learning lightweight lane detection cnns by self attentiondistillation. In ICCV, pages 1013–1021, 2019.[4] Zequn Qin, Huanyu Wang, and Xi Li. Ultra fast structureaware deep lane detection. In ECCV, pages 276–291. Springer, 2020.[5]Ruijin Liu, Zejian Yuan, Tie Liu, and Zhiliang Xiong. End-to-end lane shape prediction with transformers. In WACV, pages 3694–3702, 2021.
[6] Joakim Johnander, Martin Danelljan, Emil Brissman, Fahad Shahbaz Khan, and Michael Felsberg. A generative appearance model for end-to-end video object segmentation. In CVPR, pages 8953–8962, 2019.
[7] Carles Ventura, Miriam Bellver, Andreu Girbau, Amaia Salvador, Ferran Marques, and Xavier Giro i Nieto. RVOS: Endto-end recurrent network for video object segmentation. In CVPR, pages 5277–5286, 2019.[8] Seoung Wug Oh, Joon-Young Lee, Ning Xu, and Seon Joo Kim. Video object segmentation using space-time memory networks. In ICCV, pages 9226–9235, 2019.[9] Yongqing Liang, Xin Li, Navid Jafari, and Qin Chen. Video object segmentation with adaptive feature bank and uncertain-region refifinement. In NeurIPS, 2020.[10] Yizhuo Zhang, Zhirong Wu, Houwen Peng, and Stephen Lin. A transductive approach for video object segmentation. In CVPR, pages 6949–6958, 2020.