【速览】ACM MM-21丨从合成到真实:无标签真实数据协同驱动的图像去雾算法
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
从合成到真实:无标签真实数据协同驱动的图像去雾算法
通讯作者:万亮
◆ ◆ ◆ ◆
单幅图像去雾是一项具有挑战性的任务,合成训练数据和真实测试图像之间的域迁移(domain shift)通常会导致现有方法结果的退化。为了解决这个问题,本文提出了一种将有标签的合成训练数据与无标签的真实数据协同训练的图像去雾框架。首先,本文提出了一个基于特征解耦的图像去雾网络(DID-Net),该网络根据雾的生成过程的物理模型,将输入图像的特征解耦为三个特征分量,即无雾图像特征分量、传输图特征分量和全球大气光特征分量。对解耦后的特征分量,本文采用由粗到细的两阶段方式分别进行预测。然后,采用基于特征解耦的半监督mean-teacher网络(DMT-Net)对无标签的真实数据进行训练,以提高网络模型的去雾能力。
为了解决这些问题,本文提出了一种基于特征解耦的半监督学习框架(DMT-Net),利用基于物理模型的特征解耦和基于真实数据的半监督学习来提高图像去雾能力。具体而言,本文首先提出了一个基于特征解耦的去雾网络(DID-Net),将输入图像的特征解耦为不同尺度的三个特征分量,分别是用于传输图估计的特征,用于无雾图像估计的特征,和用于全球大气光估计的特征。之后,对相邻尺度的不同特征分量分别进行特征融合,以预测传输图、无雾图像和全球大气光。另一方面,为了利用真实有雾图像,本文采用基于mean-teacher的半监督学习框架,最小化合成数据的监督损失和真实数据的一致性损失,以优化网络模型。
•采用基于特征解耦的半监督网络(DMT-Net)对有标签的合成数据进行监督学习,对无标签的真实数据利用学生网络和老师网络的一致性约束进行半监督学习。
图1显示了DMT-Net的网络结构,该网络采用特征解耦的方式对有标签的合成数据进行监督学习,对无标签的真实数据进行半监督学习。具体地说,将有标签的合成数据输入到学生网络,获得三个分量的粗略预测(
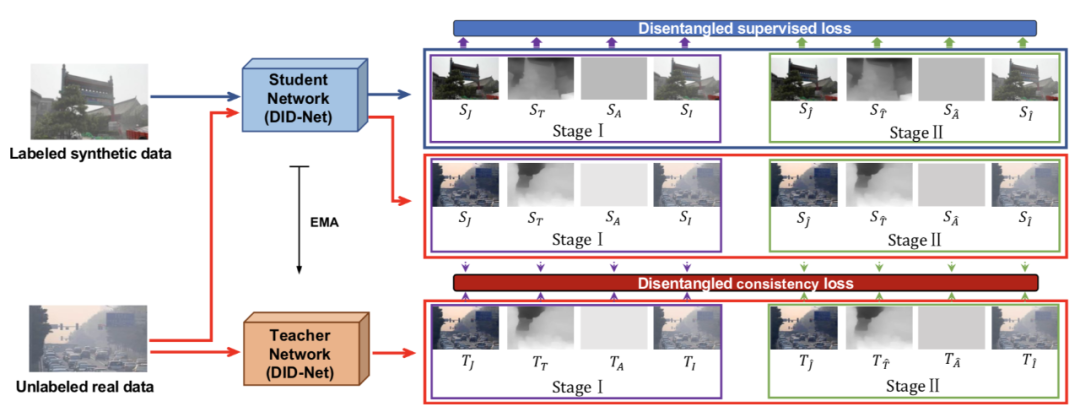
图 1 DMT-Net的网络结构
2.1 基于特征解耦的图像去雾网络DID-Net
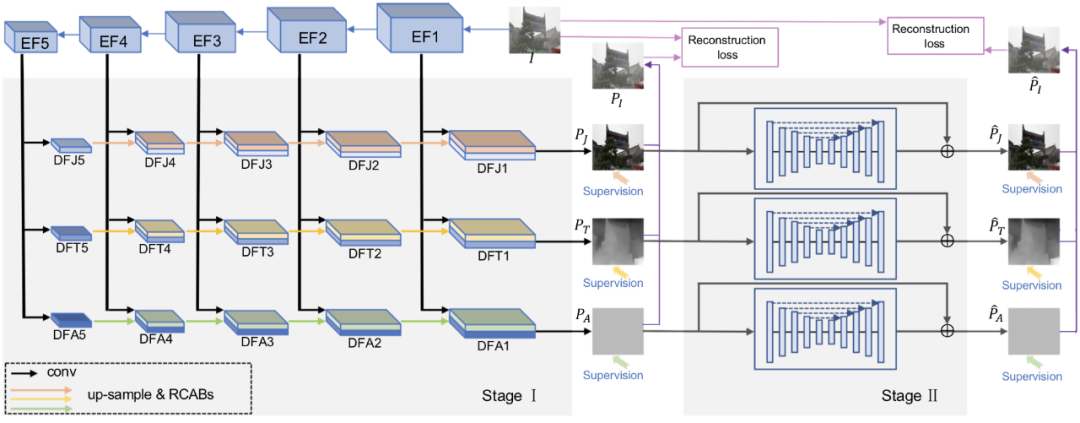
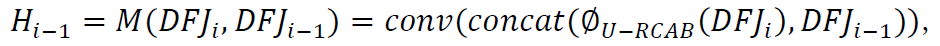
2.2 有标签数据的监督损失
2.3 无标签数据的一致性损失
对无标签真实数据,我们考虑学生网络和老师网络预测结果的一致性约束,够建如下所示的一致性损失函数:
3.1 数据集
我们使用现有工作[1]中的两个公共数据集SOTS和HazeRD。其中SOTS数据集由1000个测试图像组成,HazeRD包含15幅具有更真实雾的室外图像。除了SOTS和HazeRD之外,还创建了一个包含4000幅图像的合成数据(Haze4K),其中每张有雾图像都有无雾图像、传输图和大气光对应的标签。具体来说,随机选取NYU-Dept [2]数据集里的500张室内图像和OTS[3]数据集里的500张室外图像,共收集了1000张干净的图像。其中,从室内图像集(125幅图像)和室外图像集(125幅图像)中随机选择250幅图像作为测试集,其余750幅图像作为训练集。之后,对于每个干净的图像生成4张有雾图像。因此,Haze4K共有4000张图像,其中3000张训练图像,1000张测试图像。
3.2 在合成图像上的实验结果
实验对比了2种传统的基于先验知识的方法(DCP[4]和NLD[5])以及11种基于CNN的方法。表1和图3分别展示了不同去雾方法的PSNR和SSIM以及可视化效果。可以看到,本文提出的基于特征解耦的半监督去雾网络可以更好地完成图像去雾任务。
表 1 不同方法的量化结果
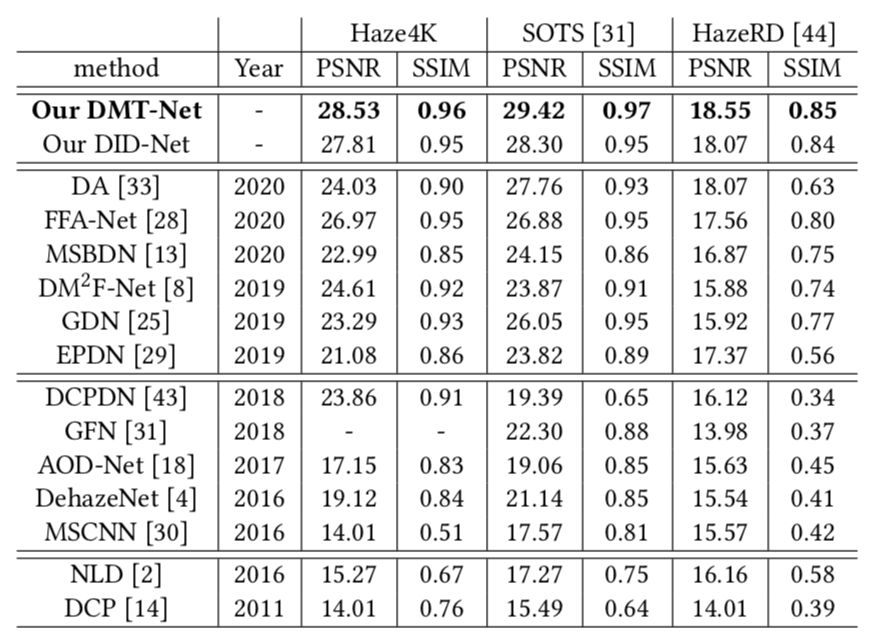

图 3 合成图像上的可视化效果
3.3 在真实图像上的实验结果
图4直观地比较了真实世界有雾照片上的去雾结果,这些照片来自于RESIDE数据集[3]。方法DA[1]存在颜色失真的问题,GDN[6]倾向于使区域变暗;参见图4的第一幅图像(车道区域)。AOD-Net、MSBDN、FFA-Net和DM2F-Net仅仅去除了少量雾,生成的图像中仍存在大量的雾;参见图4的放大视图。本文的方法可以在产生逼真颜色的同时更有效地去雾。

图 4 真实图像上的可视化效果
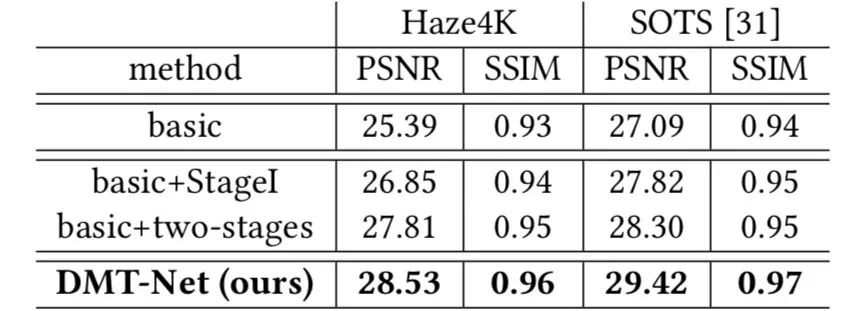
3.4 消融实验
为了探讨不同模块的有效性,本文进行了一系列消融实验。第一行是通过删除预测传输图和大气光的两个分支、删除预测细化和删除无标签数据来构建的。第二行使用三个分支对输入图像进行特征解耦,对解耦的特征预测三个分量(A,T和J)。第三行通过添加U-Net来对预测结果进一步优化。第四行则是本文提出来的基于特征解耦的半监督网络模型。
表 2 消融实验的量化结果
[1] Yuanjie Shao, Lerenhan Li, Wenqi Ren, Changxin Gao, and Nong Sang. 2020. Domain Adaptation for Image Dehazing. In CVPR. 2805–2814.
[2] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. 2012. Indoor segmentation and support inference from rgbd images. In ECCV. 746–760.
[3] Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. 2018. Benchmarking single-image dehazing and beyond. TIP 28, 1 (2018), 492–505.
[4] Kaiming He, Jian Sun, and Xiaoou Tang. 2011. Single image haze removal using dark channel prior. TPAMI 33, 12 (2011), 2341–2353.
[5] Dana Berman and Shai Avidan. 2016. Non-local image dehazing. In CVPR. 1674– 1682.
[6] Xiaohong Liu, Yongrui Ma, Zhihao Shi, and Jun Chen. 2019. Griddehazenet: Attention-based multi-scale network for image dehazing. In ICCV. 7313–7322.

CSIG图像图形中国行承办方征集中





