干货 | 快速端到端嵌入学习用于视频中的目标分割
三月即没,四月在望。四月者,送严寒而迎东君,历清明而过谷雨。金风和煦,万物复苏。百芳发而幽香逸,春鸟还而鸣声碎。
好几天没有和大家一起学习,探讨问题了。最近主要去打理“计算机视觉协会”知识星球,给星球的同学们讲解了目标检测中遇到遮挡该怎么去解决的方法。
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

暗中观察

默默关注
那我们开始进入今天的主题,接下来主要和大家分享目标在视频中的实时分割技术,来,一起学习吧!

背景及动机
最近对于目标分割的技术,已经出现很多很多,但都比较复杂,严重依赖于第一帧的微调,而且与/或速度慢,因此实际应用特别有限。
在今天的分享中,新框架将FEELVOS(Fast End-to-End Embedding Learning for Video Object Segmentation)作为一种简单、快速、不依赖于微调的方法。

为了分割视频,FEELVOS对每一帧使用语义像素级嵌入和全局和局部匹配机制,将信息从第一帧和视频的前一帧传输到当前帧。与以前的工作相比,该嵌入仅用作卷积网络的内部指导,该技术新的动态分割头允许训练网络,包括嵌入,端到端的多目标分割任务的交叉熵损失。
最后,在不需要微调的Davis 2017验证集上实现了视频目标分割的新技术,其J&F值为69.1%。
新框架方法
今天提及的新框架,提出了一种用于半监督视频目标快速分割的FEELVOS算法。
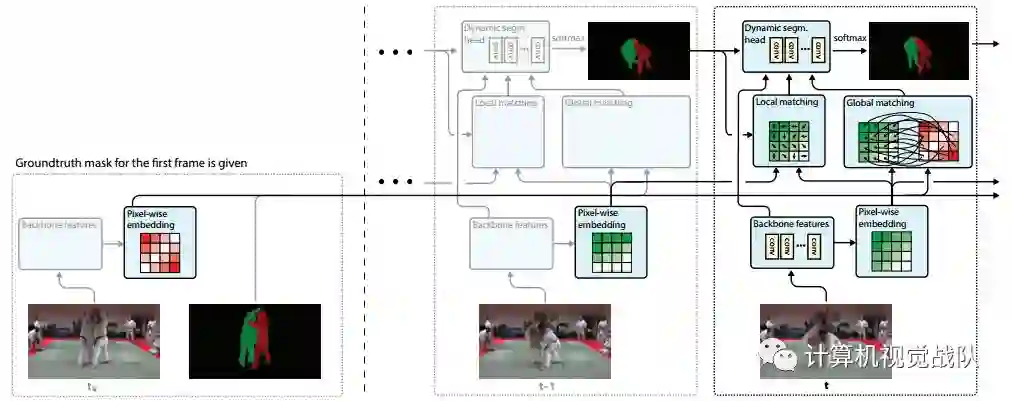
FEELVOS使用单个卷积网络,每个视频帧只需要一次前向传输。有关FEELVOS的概述,请见如下整体框架图。
该体系结构使用DeepLabv 3+(去掉其输出层)作为主干,与原始图像相比,提取步长为4的特征。在此基础上,新框架增加了一个嵌入层,该层提取同一步长的嵌入特征向量。然后,通过全局匹配当前帧的嵌入向量和第一帧中属于该目标的嵌入向量来计算每个目标的距离图。
另外,通过将当前帧嵌入到前一个帧的嵌入向量进行局部匹配,从而为每个目标计算另一个距离图。
下面将更详细地描述全局匹配和局部匹配。最后,新框架结合了所有可用的线索,即全局匹配距离映射、局部匹配距离映射、来自前一帧的预测以及主干网络特征。
然后,将它们提供给一个动态分割头,该动态分割头为每个像素(步长为4)在第一帧中的所有目标上产生后验分布。整个系统在不需要嵌入直接损失的情况下,对多目标分割进行端到端的训练。在下面的部分中,我们将更详细地描述每个组件。
语义嵌入
对于每个像素,在学习的嵌入空间中提取一个语义嵌入向量。嵌入空间的思想是,属于同一目标实例(同一帧或不同帧)的像素将在嵌入空间中临近的,属于不同目标的像素将远离。
请注意,这不是显式强制的,因为新框架没有直接使用嵌入空间中的距离来生成像PML或VideoMatch中那样的分段,而是使用它们作为一个软提示,可以通过动态分割头进行细化。然而在实践中,嵌入实际上是这样的,因为这为动态分割头提供了一个强有力的线索,以进行最终的分割。
全局&局部匹配
类似于PML和VideoMatch,通过在学习的嵌入空间中考虑最近的邻域,将第一个视频帧的语义信息从具有基本真实度的第一个视频帧转移到要分割的当前帧。
如下图所示,全局匹配距离图的可视化(暗颜色表示小距离,亮颜色表示大距离)。可以看出,鸭是比较好捕获,但距离图是嘈杂的,并包含许多假阳性的小距离在水中。这是一个强烈的动机,不使用这些距离直接产生分段,而是作为一个输入的分割头部,可以从噪声的距离恢复。
在实际应用中,用一个大型矩阵乘积来计算全局匹配距离映射,由此得到当前帧到第一个帧之间的所有配对距离,然后应用对象极小化。
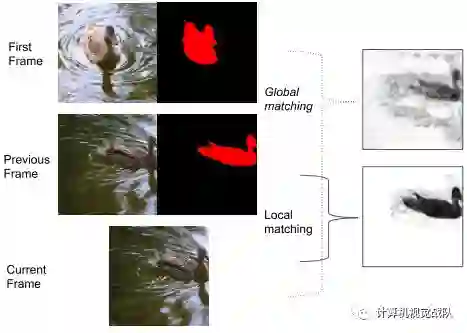
上图也给出了一个局部匹配距离图的可视化实例。请注意,与前一个帧掩码太远的所有像素都被分配了1的距离。由于前帧和当前帧之间的运动很小,局部匹配产生了非常清晰和准确的距离图。
动态分割头
动态分割头为了系统有效地处理可变数量的目标,新框架提出了一个动态分割头,对每个具有共享权重的目标进行动态实例化一次(见下图)。
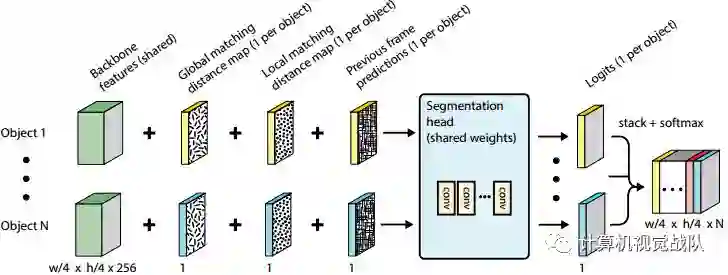
每个目标都需要运行一次分割头,但是大多数计算都是在提取共享主干网络特征时进行的,这使得FEELVOS能够很好地扩展到多个目标。此外,能够训练端到端的多目标分割,甚至对可变数量的目标。这两个属性与许多最近的方法(如rgmp)形成了强烈的对比。
实验结果
Davis 2017验证集上的结果
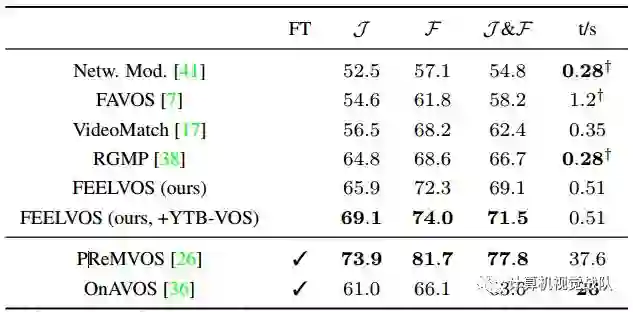
Davis 2017验证集上的结果
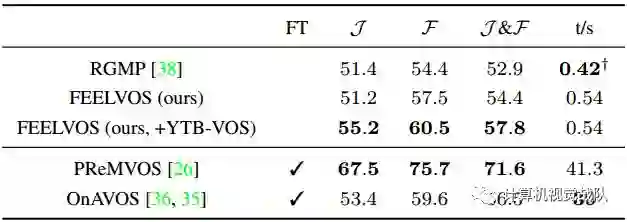
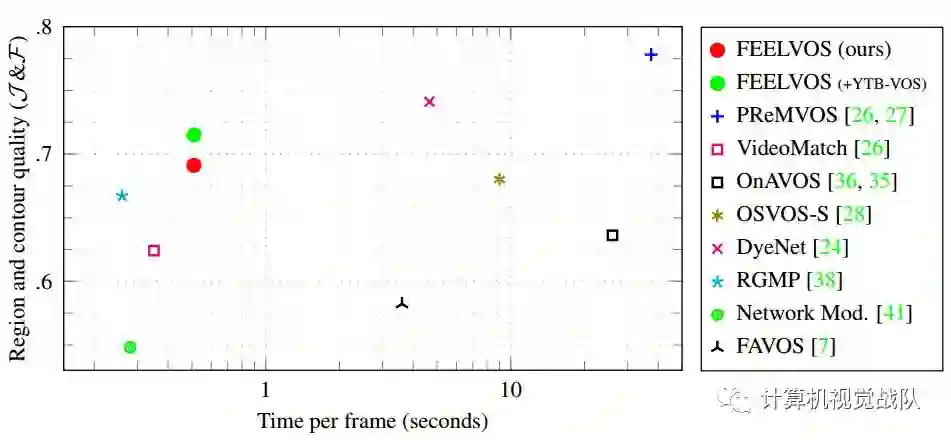
时间
在两个数据集上的可视化结果

如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!




