【速览】ICCV 2021丨Visual Saliency Transformer: 视觉显著性转换器
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
Visual Saliency Transformer: 视觉显著性转换器
#通讯作者:韩军伟(junweihan2010@gmail.com)
◆ ◆ ◆ ◆
目前基于卷积神经网络架构的先进的显著性检测方法虽然已经得到了很好的效果,但是它们在学习全局信息方面还存在一定的缺陷。而对于显著性目标检测来说,全局上下文信息和全局对比度是非常重要的。然而,由于卷积操作是在局部滑动窗口中提取特征,因此以前基于卷积神经网络架构的方法很难去探索关键的全局信息。虽然有一些方法利用全连接层、全局池化层和非局部模块来整合全局信息,但是它们只是在特定的几层被使用而且依旧保持着标准的卷积神经网络架构形式。
在机器翻译任务中,Transformer方法[1]可以探索单词之间的全局长范围依赖信息。其核心思想是自注意力机制(self-attention),即利用查询-键来建模不同位置之间的相关性。Transformer方法[1]在编码器和解码器中多次堆叠自注意力层,从而在每一层都实现了全局长范围依赖建模。因此,将Transformer引入显著性检测来探索全局长范围依赖是非常可行的。
至此,本文首次从序列到序列的角度来重新思考显著性检测任务,并为RGB和RGB-D显著性检测提出了一个统一的模型,命名为Visual Saliency Transformer。我们延续ViT[2]的方法将图片裁剪成图片块,然后利用Transformer模型来在图片块之间探索全局长范围依赖。然而,将ViT[2]应用到显著性检测上并不容易。一方面,如何利用纯transformer来解决密集型任务是一个需要解决的问题;另一方面,ViT[2]将图片处理成非常粗糙的尺寸,如何将ViT适应到显著性检测任务上来获取高分辨率的预测结果也是需要解决的。
为了解决第一个问题,我们设计了一个基于token的多任务解码器,它通过引入任务相关的tokens来学习决策。接着,我们提出了一个新的patch-task-attention机制来生成密集预测结果,这为密集型预测任务中使用transformer提供了新的范式。由于受到先前利用边缘检测来提高显著性检测性能的方法的启发,我们设计了多任务解码器,即通过引入显著性token和边缘token来同时进行显著性检测和边缘检测。该策略通过简单地学习与任务相关的tokens来简化多任务预测的工作流程,从而在获得更好的结果的同时降低了计算成本。为了解决第二个问题,我们受到Tokens-to-Token (T2T) 转化算法[3]的启发,提出了一个新的RT2T (反向T2T)转化算法。该算法可以将每一个token扩展为多个子token来实现对tokens的上采样。我们于是用所提的RT2T转化算法逐步对patch tokens进行上采样并将它们与编码器中的低层级的tokens进行融合来获得最终的全分辨率的显著图。此外,我们还使用了跨模态Tansformer来深入探究RGB-D显著性检测中多模态信息之间的相互作用。最终,我们提出的VST模型在参数量和计算成本相当的情况下,在RGB和RGB-D显著性检测上都超过了现有的先进方法。
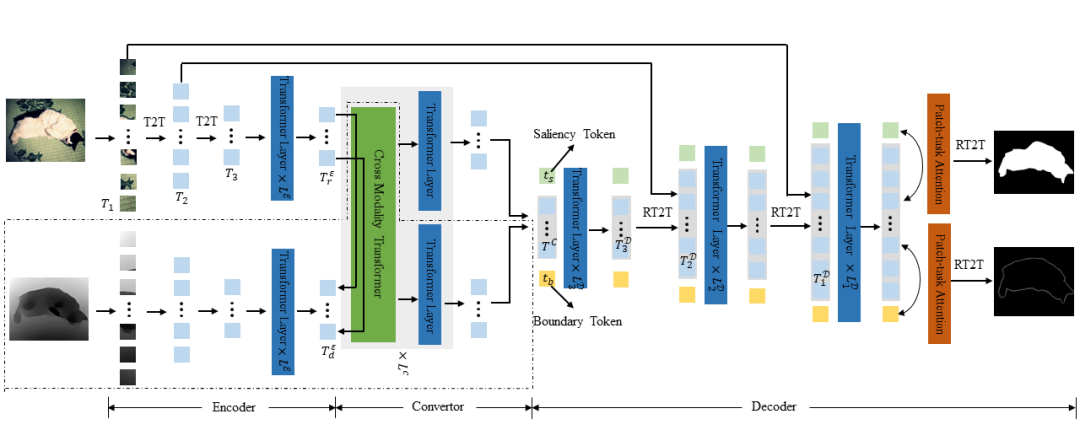
图 1 VST整体网络架构图
VST的整体框架如图1所示。首先,它用编码器从裁剪后的图片块序列中去生成多层级的tokens。然后,利用转化器将patch tokens转化到解码器空间,同时对RGB-D的数据进行多模态信息融合。最后,解码器通过提出的与任务相关的tokens和patch-task-attention来同时预测显著图和边缘图,期间还用到了RT2T算法来对patch tokens进行上采样。
一、编码器
先前基于卷积神经网络的显著性检测方法通常都采用预训练好的图像分类模型来作为编码器来提取图片特征。与它们类似,我们采用预训练模型T2T-ViT[3]作为我们的编码器。有关细节可参考T2T-ViT原文[3]。对于RGB显著性检测,我们用一个单一的transformer编码器来提取RGB patch tokens
二、转化器
我们在编码器和解码器之间插入一个转化器,用来将编码器得到的patch tokens从编码器空间转化到解码器空间。
1.RGB-D转化器
对于RGB-D显著性检测,我们设计了一个跨模态Transformer(CMT)来融合从编码器中提取到的RGB patch tokens
首先,类似于标准的self-attention层,我们通过三个线性投影操作将
接着,我们计算来自一种模态的查询和另一种模态的键之间的attention,然后和值加权求和得到最终的输出,整个过程可表示成:
经过上述流程后,我们又给RGB patch tokens和深度patch tokens分别应用一个标准的transformer层。最后,我们将获得的RGB patch tokens和深度patch tokens级联起来并投影得到最终转化后的patch tokens
2. RGB 转化器
对于RGB显著性检测,我们直接在RGB patch tokens
三、解码器
我们设计的解码器主要包括token上采样、多级别token融合和基于token的多任务预测三个部分。
1.Token上采样
假设H和W是图片的高和宽,我们得到的
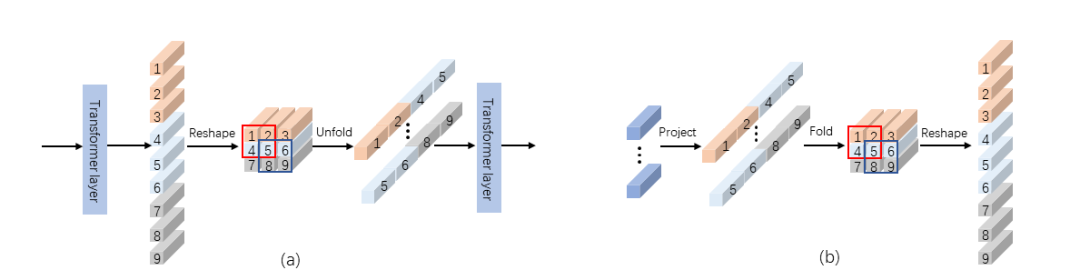
图 2.(a) T2T 模块[3] (b) 本文所提出的RT2T上采样方法
具体来说,我们首先使用一个线性投影将patch tokens的维度从
2.多级别token融合
由于目前很多显著性检测方法已经证明了多层级特征融合是有效的,因此受到这些方法的启发,我们也利用来自编码器中低层级的tokens,即
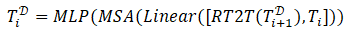
[,] 表示沿着token的嵌入维度进行级联操作,“Linear”表示级联后采用的线性投影来降低维度。其中
3.基于token的多任务预测
目前一些纯transformer方法[2,3]通过给patch tokens增加一个class token来进行图片分类。受到它们的启发,我们也利用与任务相关的tokens来预测结果。然而,我们无法直接在任务相关token上使用MLP来获得密集预测的结果。因此,我们提出patch-task-attention来通过探索patch tokens和任务相关token之间的关系进行显著性检测。另外,受到显著性模型中广泛使用的边缘检测的启发,我们还采用多任务学习策略来同时进行显著性检测和边缘检测,从而用边缘检测来帮助提升显著性检测的性能。
为此,我们设计了两个与任务相关的tokens, 即显著性token
为了得到显著性和边缘预测结果,我们在最后一个解码器中对patch tokens
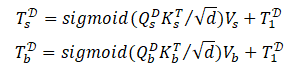
这里在计算attention时用sigmoid激活是因为只存在一个键。
因为
对于RGB显著性检测任务,我们在6个RGB显著性检测数据集上验证了我们的VST模型,分别是ECSSD[4]、HKU-IS[5]、PASCAL-S[6]、DUT-O[7]、SOD[8]和DUTS[9]。对于RGB-D显著性检测任务,我们在9个RGB-D显著性检测数据集上进行了验证,分别是STERE[10]、LFSD[11]、RGBD135[12]、SSD[13]、NJUD[14]、NLPR[15]、DUTLF-Depth[16]和ReDWeb-S[17]。表1和表2分别展示了RGB和RGB-D显著性检测的定量结果。实验结果表明在RGB和RGB-D显著性检测两个任务上,我们的VST模型在参数量和计算成本相当的情况下,性能超过了之前所有基于卷积神经网络的方法。此外,图3展示了定性结果的比较。可以看出我们提出的VST在极具挑战的场景下(如大目标、复杂背景、前背景相似等)可以精确地检测出显著性物体。
表 1 本文VST和其他12个SOTA RGB 显著性方法在6个数据库上的定量比较
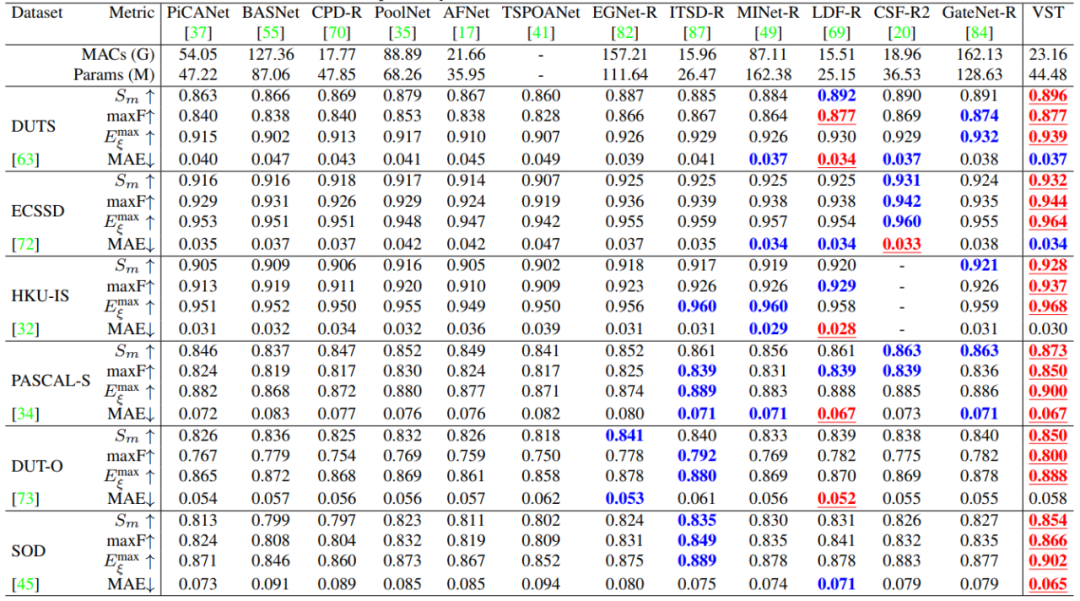
表 2 本文VST和其他14个SOTA RGB-D 显著性方法在9个数据库上的定量比较
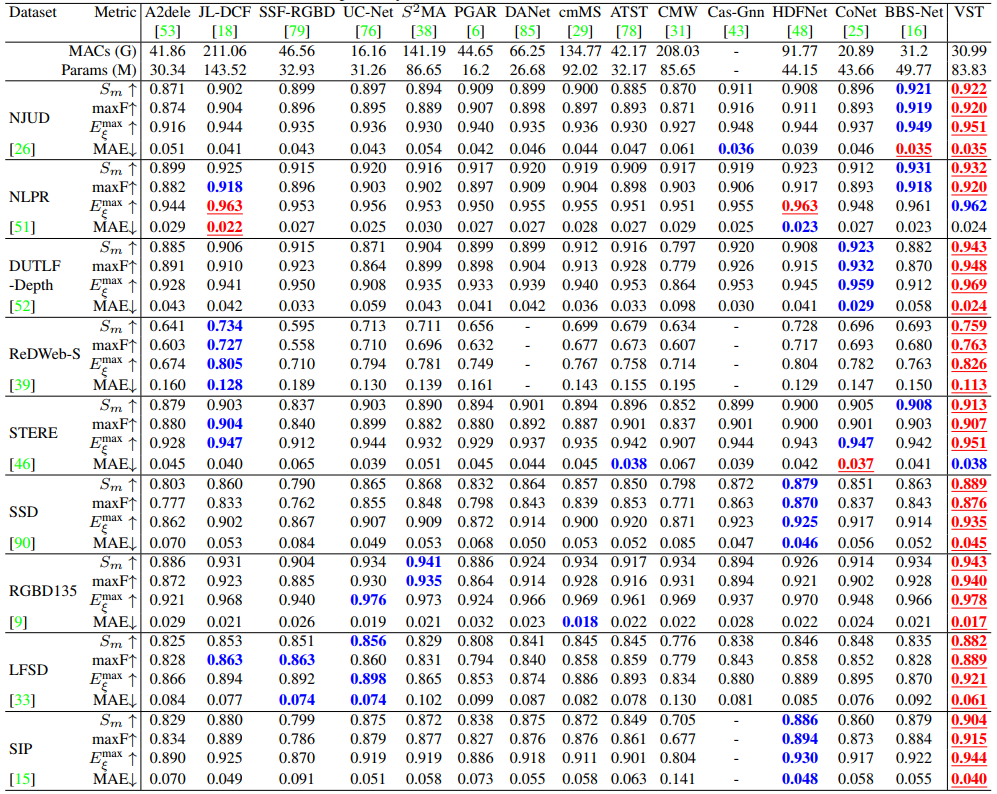

图 3 与SOTA RGB-D(左)和RGB(右)显著性方法的定性比较
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 5998– 6008, 2017.
[2] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2020.
[3] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Francis EH Tay, Jiashi Feng, and Shuicheng Yan. Tokensto-token vit: Training vision transformers from scratch on imagenet. In ICCV, 2021.
[4] Qiong Yan, Li Xu, Jianping Shi, and Jiaya Jia. Hierarchical saliency detection. In CVPR, pages 1155–1162, 2013.
[5] Guanbin Li and Yizhou Yu. Visual saliency based on multiscale deep features. In CVPR, pages 5455–5463, 2015.




