【速览】ACM MM 2021 | 针对场景文本图像超分辨率任务的并行上下文注意力网络
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
针对场景文本图像超分辨率任务的并行上下文注意力网络
通讯作者:赵才荣
◆ ◆ ◆ ◆
现有的文本超分辨率方法存在如下问题。早在真实的(基于相机不同拍摄焦段构建的低分辨率-高分辨率图像对)文本超分辨率数据集发布之前,大多数方法针对合成的(低分辨率图像由高分辨率图像降采样获得)超分辨率数据设计模型,仅微调现有的通用超分辨率算法就很快的达到了此场景的性能上限。也因此,少有针对文本图像特点的超分辨率方法被提出。然而,近期的研究主要围绕真实场景下的文本超分辨率数据设计模型,这些方法没有充分考虑隐藏在文本图像中的上下文信息以及文本轮廓信息。一方面,文本图像水平方向上蕴含了字符之间不同程度的上下文依赖,尤其是字符之间的关系符合某种语言先验(诸如单词、词组等)。字符内部采用相同的字体、字号,其结构之间的上下文关系也可以作为一种提升文本图像超分辨率质量的有效信息。在网络设计的环节,首先要考虑的就是上述上下文信息的合理建模方式。另一方面,文本的字体、颜色等并非是文字识别的关键特征,因此我们希望分别从隐式和显式的角度来增强文本轮廓信息这一极具辨识力的关键特征。
因此,基于以上内容,我们提出了一种新颖的并行上下文注意力网络(PCAN)用于解决上述问题。首先,我们探讨了水平和垂直方向上的上下文信息建模方法对文本超分辨率任务的重要性,然后设计了一个并行上下文注意力模块,以自适应地选择正交方向上下文依赖中有助于文本图像超分辨率的关键信息。其次,为了分别从隐式和显式的角度建模文本图像中的高频信息,我们提出了层次正交纹理感知注意力模块和边缘引导损失函数。前者综合了垂直和水平正交方向上不同感受野的卷积输出结果,构建了自适应关注文本轮廓的注意力机制。后者设计了一个可微分的Sobel计算模块,将端到端的获取超分辨率图像以及高清图像上的轮廓图像,辅助监督超分辨率网络的训练。PCAN网络的示意图如图1所示:
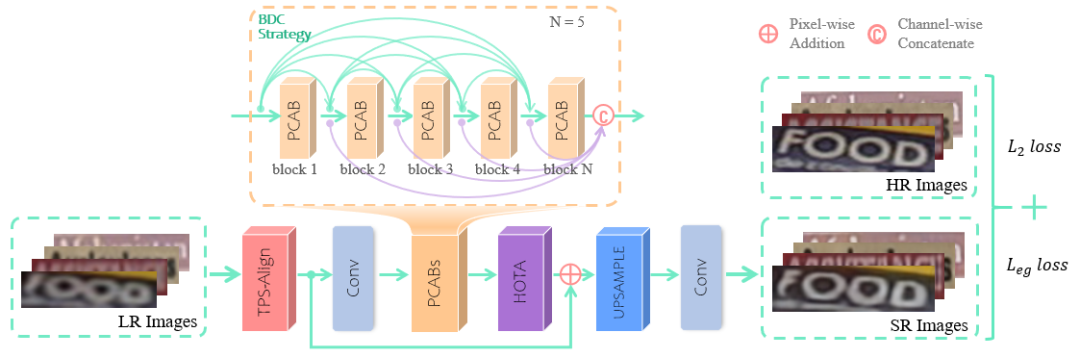
图 1 PCAN网络流程图
我们的网络结构基于TSRN [1],在此基础上我们提出了如下几个核心组件,分别是并行上下文注意力模块(PCAB)、层次正交纹理感知注意力模块(HOTA)和边缘引导的损失函数(
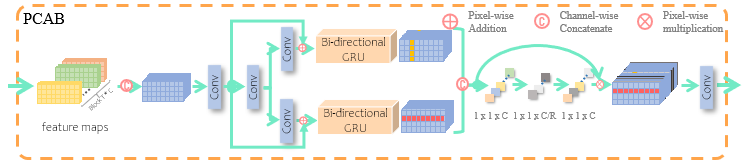
图 2 PCAB网络结构
并行上下文注意力模块(PCAB)旨在寻求文本超分辨率块上更有效地上下文信息建模方法。经验上,我们发现一种双分支结构,并行地构建垂直和水平方向上视觉特征的依赖关系,能够得到比串行方式建模更好的结果。此外,利用通道注意力自适应加权以上特征,作为两种依赖信息的门控,可以进一步提高我们算法的性能(见实验1)。如图2所示,我们将卷积层得到(B,C,H,W)维度特征通过矩阵转置得到(B*H,W,C)维度的特征,GRU模块能够作用于(B,T,C)输入特征的T方向上,构建此维度特征的循环连接,最后将特征转换为原来的形状以便后续融合。公式描述如下:
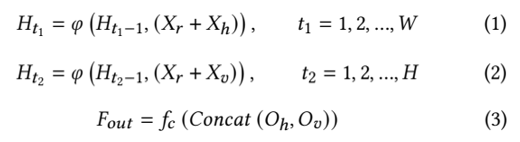
其中
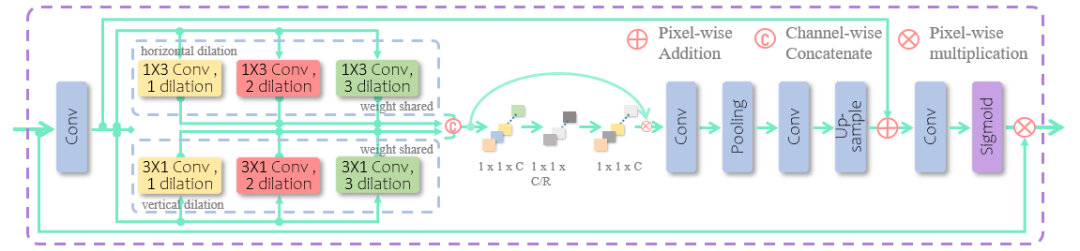
图 3 层次正交纹理感知模块
层次正交纹理感知模块(HOTA)借鉴自ContourNet [3]的LOTM模块,其设计初衷是用于捕获文本高频纹理特征用于进行精确地轮廓分割。我们将这种做法迁移到文本图像超分领域,同样分为垂直和水平方向上扩张卷积核的尺寸使得此层能够感知更多的高频轮廓信息,将其建模成通道空间注意力模块,能够隐式地增强文本轮廓的表达能力。如图1和图3所示,各级PCAB模块的输出被级联起来,作为HOTA模块的输入,因此它能综合网络不同层次的特征进行自注意力。HOTA模块也是一种双分支再特征聚合的结构,双分支分别以1xk和kx1聚合水平和垂直方向更大感受野的纹理信息,并为其添加上空洞系数,共享不同空洞系数的卷积层参数,使得其能够得到更加显著的效果。双分支特征通过一个通道注意力模块特征融合汇总以后,经过若干层卷积、残差、上采样处理,经过一层Sigmoid激活函数对每一特征值归一化,从而得到相应的注意力响应图。最后将注意力响应图与输入特征进行点乘,即可得到纹理感知增强过后的输出特征。
边缘引导的损失函数同样是一种基于L2距离的回归损失。我们将Sobel算子的参数嵌入到网络最后一层的卷积层中,并且固定此层参数,使其能端到端的获取超分辨率输出以及高清图像上的边缘响应图,用此信息来辅助网络的训练能够得到更加稳定的效果。
我们在真实文本超分辨率数据集(TextZoom)上和七个主流场景文本识别数据集(CUTE80, IC03, IC13, IC15, IIIT5K, SVT, SVTP)上对我们的算法进行了评价。此项任务中,我们将以CRNN [6]、ASTER [7]、MORAN [5]的识别准确率作为评估超分辨率图像质量的标准,也提供PSNR/SSIM指标作为参考。
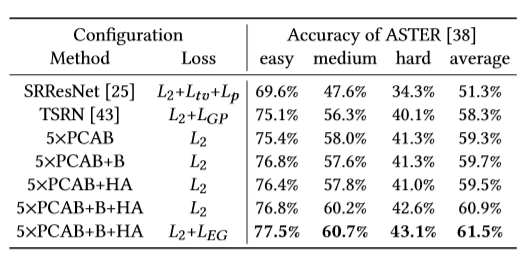
首先,为了证明所提出的方法以及其中每一模块的有效性,我们分别设计了如下几组实验。如表1所示,实验对比了超分辨率块中上下文信息不同的建模方式,分别从循环连接的方向性、特征解耦和特征冗余这几个角度进行比较,最终得出最优的设计方案(也即PCAB模块的由来)。如图4所示,我们比较了PCAB模块所用数量以及不同连接方式带来的性能差异。如表2所示,我们对PCAB、HOTA、Edge Guidance Loss分别进行了消融实验,并且与baseline网络进行了性能对比。
表 1 不同的上下文特征建模方法结果对比。V和H分别表示循环连接视觉的特征的不同方向,垂直或者水平。连接方式S和P分别表示串行连接和并行连接。注意力用的是通道注意力模块,作为循环连接后特征的信息门控
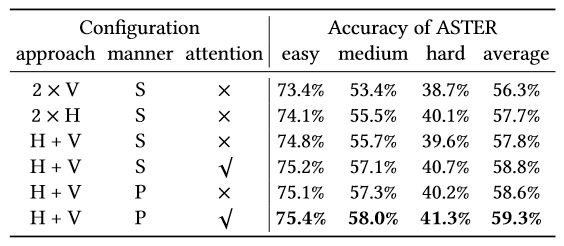
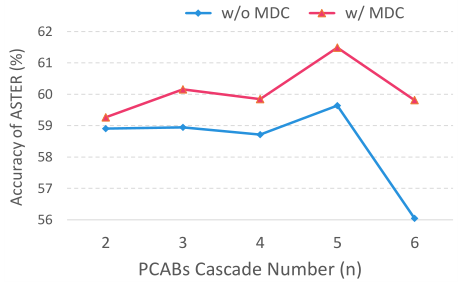
图 4 PCAB模块的连接方法、数量方面的性能差异。MDC表示模块间稠密连接
表 2 所提模块的消融实验对比分析
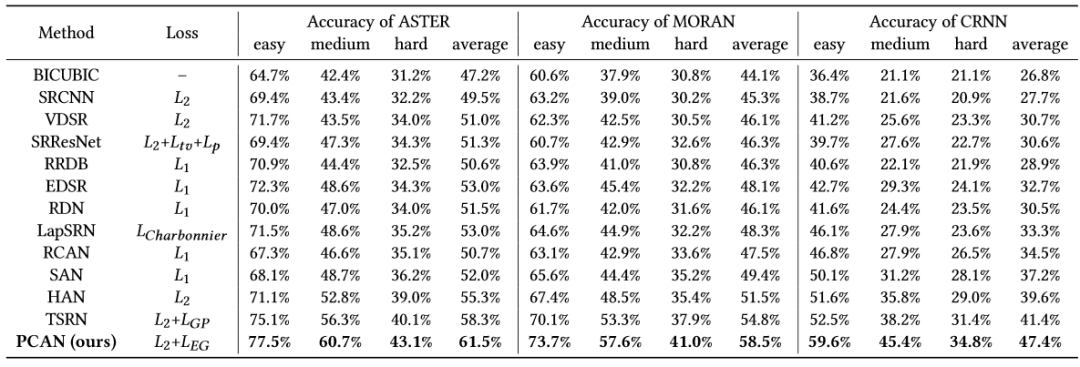
其次,如表3所示,与当前性能最优的各大通用超分网络以及文本超分网络进行性能对比。如图5所示,我们可视化了一些样例图。

图 5 超分辨率图像可视化
最后,我们讨论了一种文本超分辨率新的用途。将其作为抵抗对抗噪声的一种有效手段,为OCR管道同时带来性能和安全性方面的提升。如图6所示,我们可以看到经过PCAN处理的带噪低分辨率样本,对对抗噪声能够起到改变数据流型、去除噪声的效果,同时还能很明显的看出来文本部分的细节被更多的重建出来了。如表4所示,我们横向比较了若干超分方法,我们的方法能够一定程度上提升OCR识别管道的安全性,可作为研究OCR管道安全性的一个值得探讨的研究方向。

图6 文本超分辨率对对抗扰动的影响
表4 超分辨率方法作为抵抗对抗噪声有效性比较

[1] Wenjia Wang, Enze Xie, Xuebo Liu, Wenhai Wang, Ding Liang, Chunh3ua Shen, and Xiang Bai. 2020. Scene text image super-resolution in the wild. In European Conference on Computer Vision. Springer, 650–666.
[2] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. 2017. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition. 4681–4690.
[3] Yuxin Wang, Hongtao Xie, Zheng-Jun Zha, Mengting Xing, Zilong Fu, and Yongdong Zhang. 2020. Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11753–11762.
[4] Xing Xu, Jiefu Chen, Jinhui Xiao, Lianli Gao, Fumin Shen, and Heng Tao Shen.2020. What machines see is not what they get: Fooling scene text recognition models with adversarial text images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12304–12314.
[5] Canjie Luo, Lianwen Jin, and Zenghui Sun. 2019. Moran: A multi-object rectified attention network for scene text recognition. Pattern Recognition90 (2019),109–118.



