【速览】ICCV 2021 | 当图卷积遇上多视角3D人体姿态估计
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
当图卷积遇上多视角3D人体姿态估计
*通讯作者:刘文韬
◆ ◆ ◆ ◆
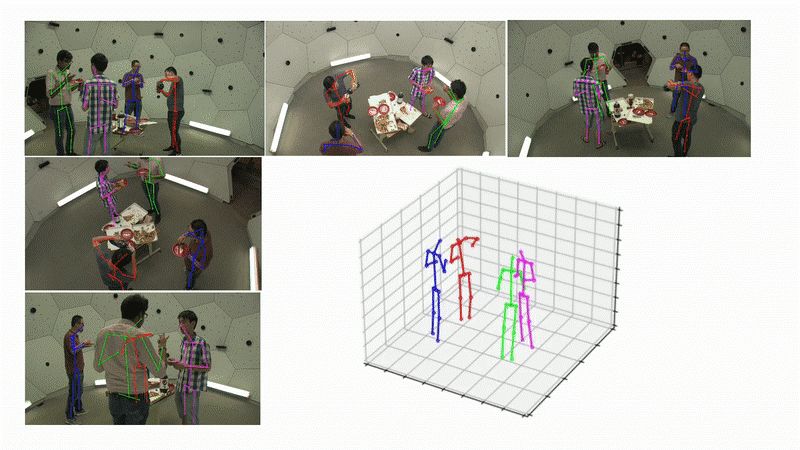
图 1 本文算法的可视化展示
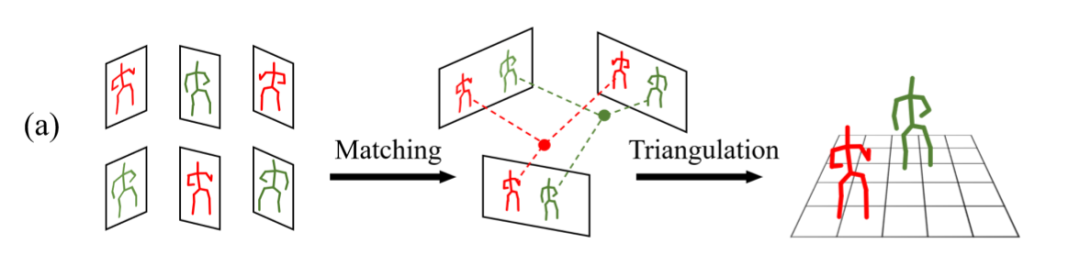
图 2 匹配+三角化重建算法的示意图
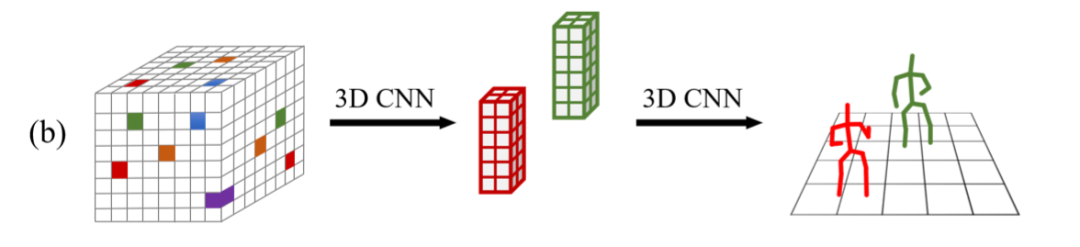
图 3 3D空间体素化算法的示意图
(b)3D空间体素化:将 3D 空间等距地划分为一个个小网格,通过概率模型或者 3D 卷积神经网络(CNN)检测关键点。代表方法:VoxelPose [2]。
缺点:(1)空间体素化的精度会受到网格大小的制约,会产生量化误差;(2)空间体素化在相同的精度下,计算复杂度随空间大小三次方增长,无法应用于较大场景。
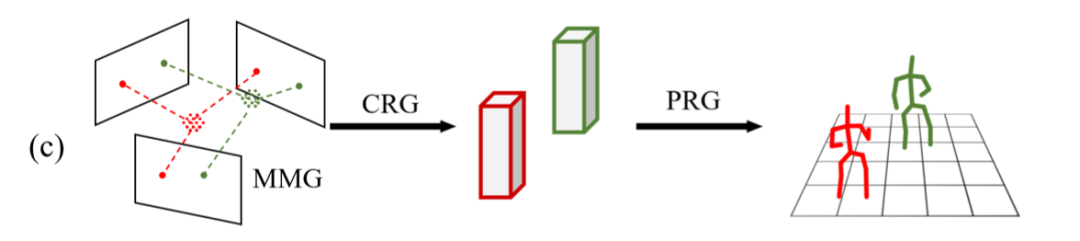
图 4 本文算法的示意图
(c)本文方法:我们结合两者的优势,提出了一种基于图卷积神经网络的,自顶向下(Top-down)的两阶段算法。我们的整体算法流程,分为两个阶段:3D人体中心点定位+3D人体姿态估计。
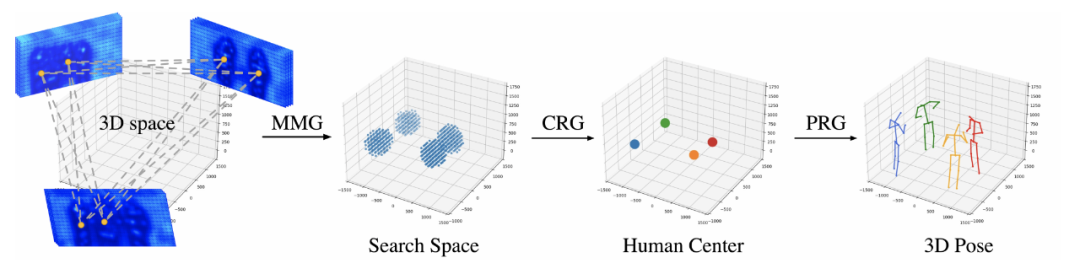
图 5 本文方法的整体框架图
Part 2.1 中心点候选区域生成 ---- Multi-view Matching Graph (MMG)
我们设计了多视角匹配图神经网络(MMG),判断不同视角的两两2D中心点,是否属于同一个人。随后,对于属于同一个人的一对关键点,两两重建出一个3D坐标作为候选中心点。
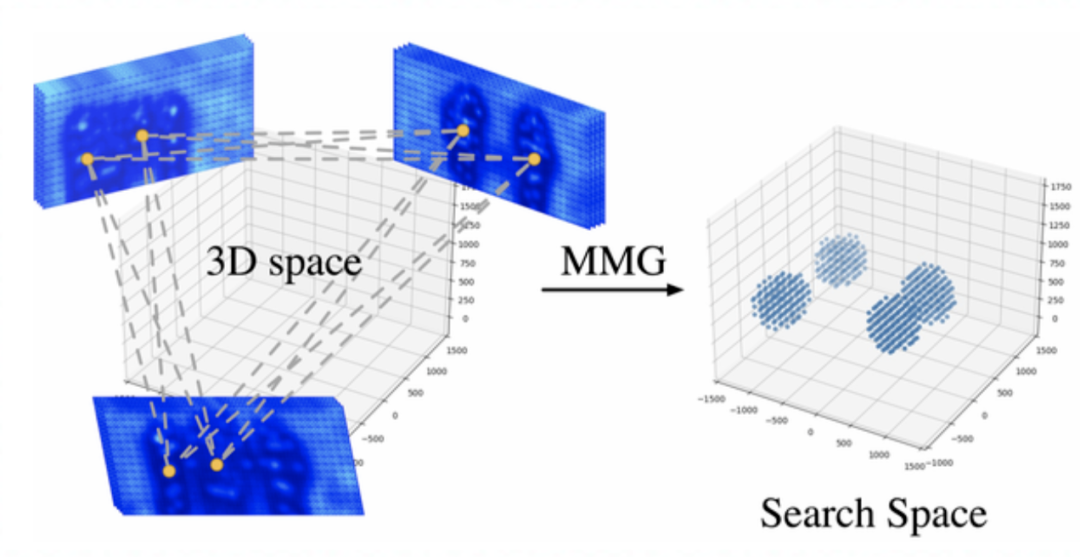
建图(Graph Construction):我们利用各个视角检测得到的人体2D中心点,来构造跨视角图模型。
图模型的“节点”为 各个视角检测到的2D人体中心点;节点的特征为:2D人体中心点位置的图像特征。
图模型的“边”,两两连接不同视角的节点,两个节点对应的2D中心点的极线距离作为边特征。
信息传递(Message Passing):利用GNN来进行相关性特征的学习。我们使用EdgeConv来搭建图卷积神经网络模型,对所构造好的Graph 进行卷积,不断更新节点的特征;通过图的表征,模型同时利用了几何信息(边特征)和图像信息(节点特征),高效的融合多视角特征,匹配精度远高于直接利用极线匹配。
判断边的属性:训练一个边判别器(Edge Discriminator),对每一对中心点(即一个边)进行判别,判断这一对中心点是否属于同一个人;
提出候选点:每一对被判断为同一个人的中心点,通过三角化重建出一个3D候选点。
Part 2.2 中心点坐标优化 ---- Center Refinement Graph (CRG)
有了候选中心点后,我们以候选点为球心的球形范围作为搜索空间,灵活地在候选区域采样。对于每个采样点,将采样点投影到各个视角并在相应位置提取特征。接着利用中心点优化图模型(CRG),通过多个视角节点的连接,实现了高效的多视角特征融合,可以准确地判断采样点是否为人体中心点。
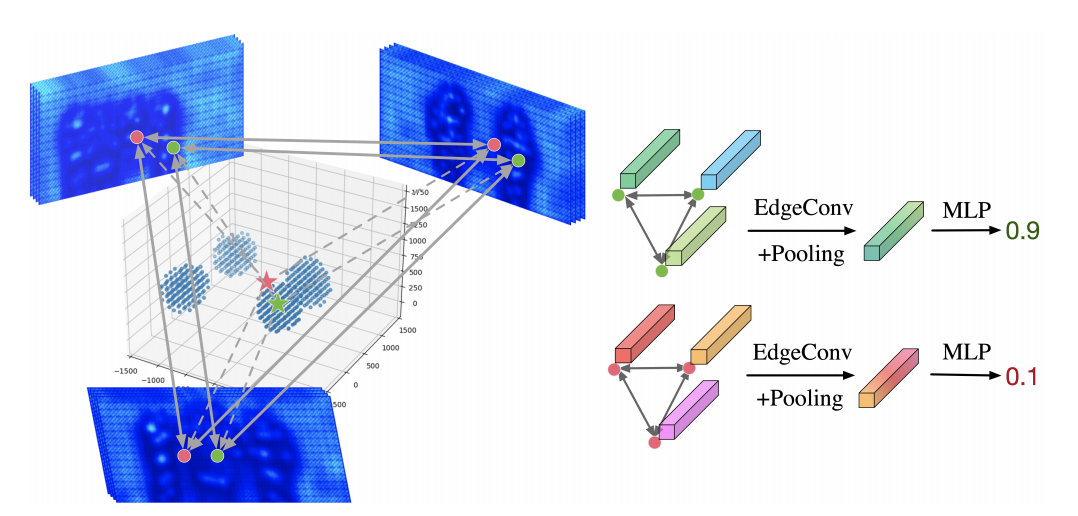
图 7 CRG模块示意图
搜索空间:以候选点为球心的球形范围作为搜索空间,所有搜索空间的并集作为总的搜索空间;
采样:我们可以进行适应性的采样,先在搜索空间中等距采样,用中心点图卷积网络检测中心点,在检测到的中心点周围进一步精细采样,以获得更精确的位置;
建图(Graph Construction):对每一个3D 采样点,构建一个图模型。其中,节点和节点特征分别对应 3D采样点投影到各个视角后的2D位置 以及 该位置的图像特征。图中的边,对各个节点进行全连接。
信息传递(Message Passing):利用GCN来进行相关性特征的学习。我们使用EdgeConv来搭建图卷积神经网络模型,利用多层图卷积不断更新节点的特征;
判断图的属性:首先对图中节点进行全局池化,得到图的特征,再训练一个多层感知机MLPs,判断图的属性:判断采样点是否为人体中心,即输出每个采样点为人体中心的置信度。
非极大值抑制 (NMS):得到每个采样点的置信度后,通过NMS操作,获得优化后的人体中心点坐标。
Part 2.3 人体 3D 姿态优化 ---- Pose Regression Graph (PRG)
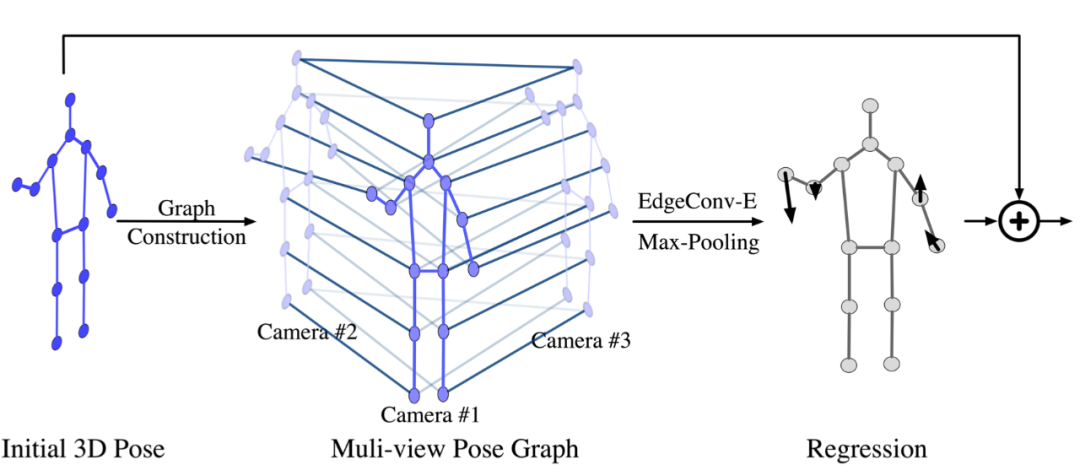
图 8 PRG模块示意图
我们采用"由粗到精"的策略,来估计人体3D姿态。首先,我们采用现有的姿态估计方法[2],得到初始的3D人体姿态(Initial 3D Pose);为了提升人体关键点的预测精度,本文提出了人体姿态回归图模型(Pose Regression Graph, PRG),利用图卷积,高效地融合多视角的特征和人体的拓扑结构信息(头和脖子相连,手和胳膊相连等),回归出每个关键点坐标的修正值。
建图(Graph Construction):首先将初始3D人体姿态,投影到各个相机视角,得到各个视角的2D人体姿态。利用各个视角下的2D人体关键点,构造跨视角姿态图(Multi-view Pose Graph)。
图模型的每个“节点”代表各个视角的每个2D关键点。节点的特征包括:关键点的类别信息,2D关键点位置处的图像特征,以及初始3D人体姿态中对应关键点的置信度。
图模型的“边”代表节点之间的关系,共包括两种类型的边:跨视角且相同类型关键点间的连接边 和 单视角且不同类型关键点间的连接边。
信息传递(Message Passing):利用GCN来进行相关性特征的学习。我们使用EdgeConv来搭建图卷积神经网络模型,对所构造好的Graph 进行卷积,不断更新节点的特征;完成多视角特征的更新和融合后,对相同类型的关键点特征进行最大值池化,得到一副人体骨架。
回归修正值(Regression):使用回归模型,预测出 N x 3 维的偏移向量(其中,N代表关键点个数),代表相对于初始3D人体姿态的修正值。
我们在 CMU Panoptic 和 Shelf 两个主流的数据集上做了实验。定量实验表明,我们提出的算法,取得了最优的精度。而且在计算量和耗时方面,我们的方法相比之前的SOTA也有明显优势。
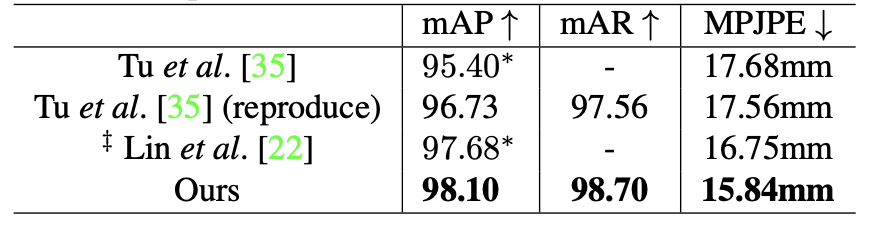
表 2 Shelf 数据集的定量结果对比

在本文中,我们提出了一套自顶向下的多视角3D人体姿态估计解决方案。我们针对该任务,精心设计了各类“多视角”图卷积神经网络(MMG, CRG, PRG)来提取人体结构性特征。我们在各数据集上的实验,也充分证明了我们算法的有效性。关于对未来的展望,我们将继续研究把算法扩展到时序,实现更高效的多视角人体姿态跟踪。在方法层面,如何更加合理地利用相机的几何信息,设计更高效的图卷积神经网络,是一个重要的改进方向。
[1] Dong, J., Jiang, W., Huang, Q., Bao, H., & Zhou, X. (2019). Fast and robust multi-person 3d pose estimation from multiple views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7792-7801).
[2] Tu, H., Wang, C., & Zeng, W. (2020). Voxelpose: Towards multi-camera 3d human pose estimation in wild environment. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16 (pp. 197-212). Springer International Publishing.



