
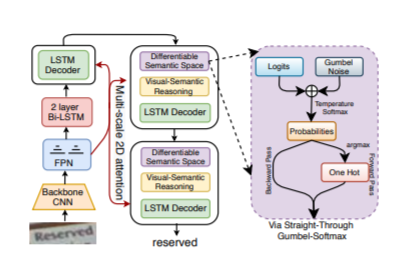
本文简要介绍ICCV2021录用论文“Joint Visual Semantic Reasoning: Multi-Stage Decoder for Text Recognition”的主要工作。作者提出了一种多阶段多尺度注意力解码器,用于执行联合视觉语义推理,从而进一步利用语义信息。第一阶段使用视觉特征进行预测,随后的阶段使用联合视觉语义信息进行优化。
由于复杂的背景、不同的字体、不受控制的照明、扭曲和其他人为因素,最先进的文本识别框架仍然难以适应各种场景[1]。当人类面对这些挑战时,我们可以通过联合视觉语义推理来很容易地识别它们。因此,“如何开发文本识别的视觉语义推理技能”是一个重点问题。
在野外场景中,文字图像可能会模糊、扭曲或部分失真,噪声或有伪影,这使得仅使用视觉特征识别非常困难。在这种情况下,我们人类会首先尝试仅使用视觉线索来解释易于识别的字符。然后,联合处理先前已经识别的字符序列的视觉和语义信息,应用语义推理技巧对最终的文本进行解码。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2022年1月28日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年1月28日