一文带你浏览Graph Transformers

极市导读
本文通过整理分析2020-2022年不同顶会关于Graph Transformers的论文,汇总并对比了该领域的各种前沿方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前头
为什么图上要使用Transformer?
-
能捕获长距离依赖
-
减轻出现过平滑,过挤压现象
-
GT中甚至可以结合进GNN以及频域信息(Laplacian PE),模型会有更强的表现力。
-
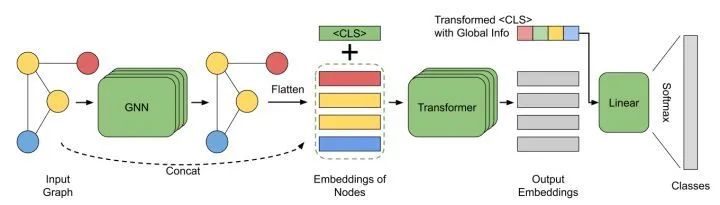
利用好[CLS] token,不需要额外使用pooling function。
-
etc...
文章汇总
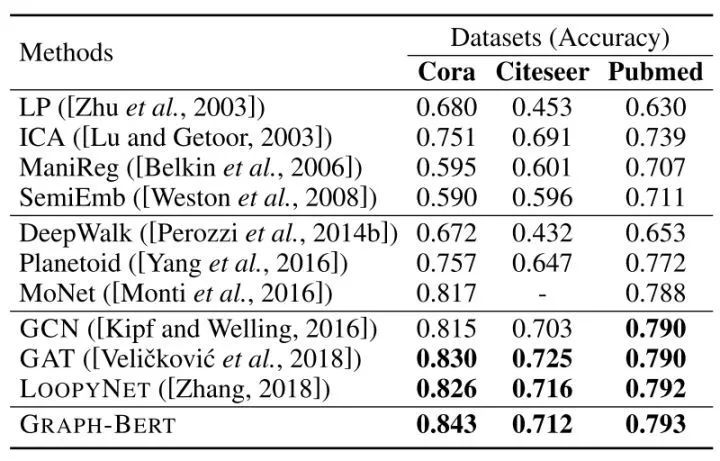
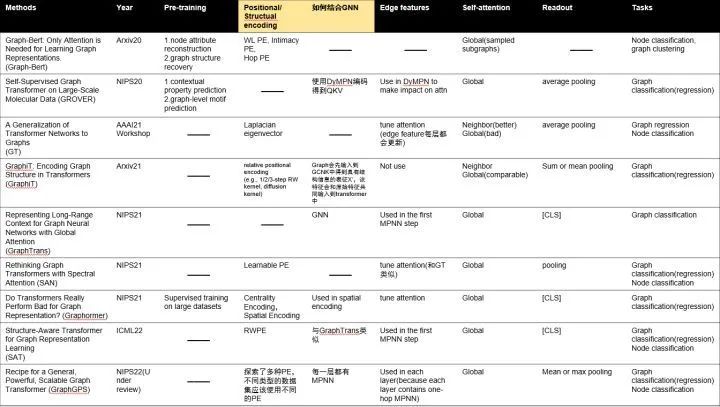
[Arxiv 2020] GRAPH-BERT: Only Attention is Needed for Learning Graph Representations
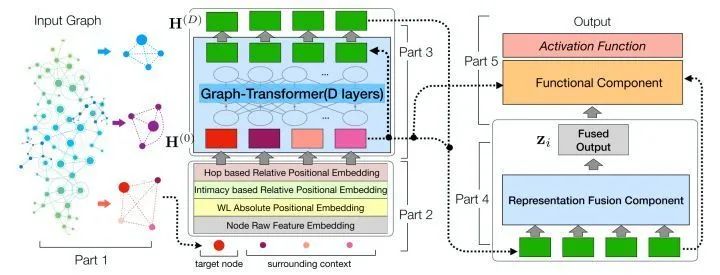
为了便于操作,作者将subgraph根据 图亲密度矩阵( https://zhuanlan.zhihu.com/p/272754714)进行排序[i, j, ...m],其中S(i,j) > S(i,m),得到序列化的结果。
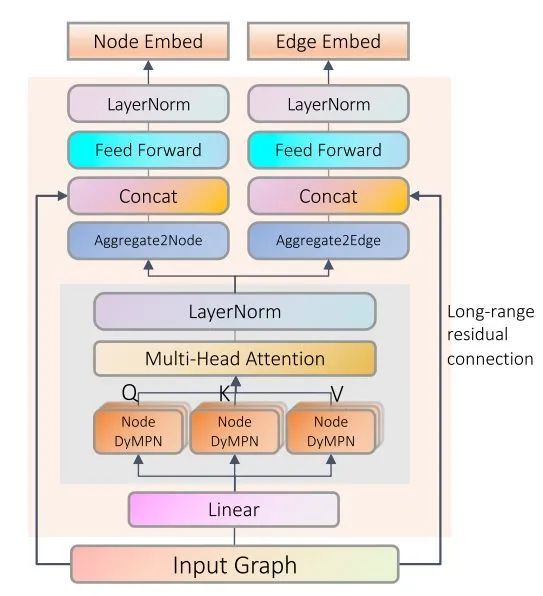
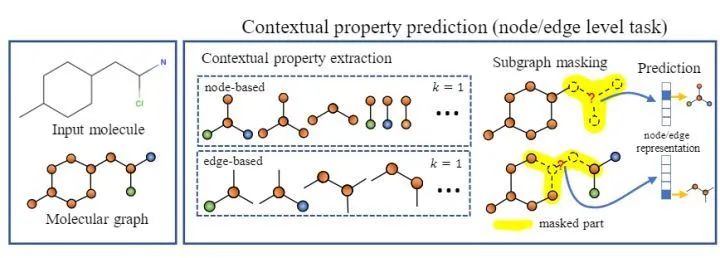
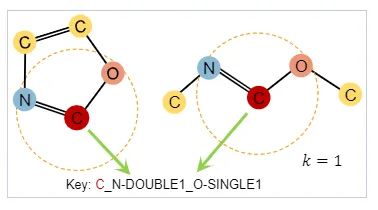
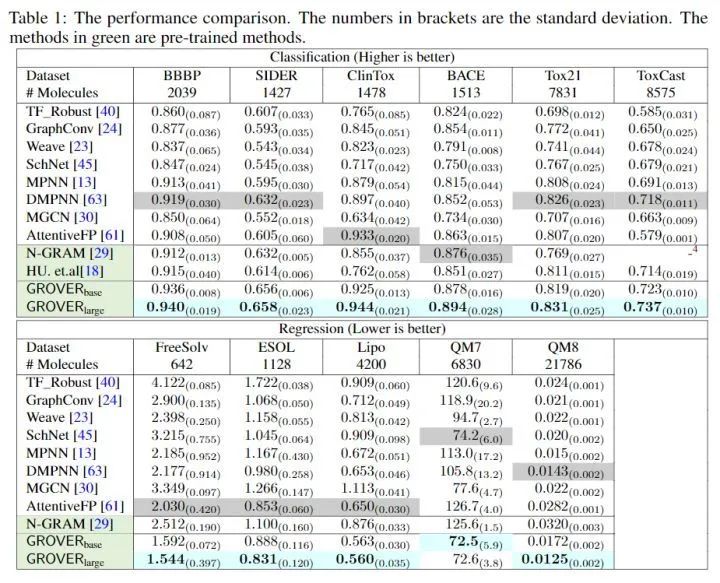
[NIPS 2020] (GROVER) Self-Supervised Graph Transformer on Large-Scale Molecular Data
-
预测目标是可信的并且是容易得到的。
-
预测目标应该反应节点或者边的上下文信息。基于这些性质,作者设计了基于节点和边的自监督任务(通过subgraph来预测目标节点/边的上下文相关的性质)。
[AAAI 2020 Workshop] (GT) A Generalization of Transformer Networks to Graphs
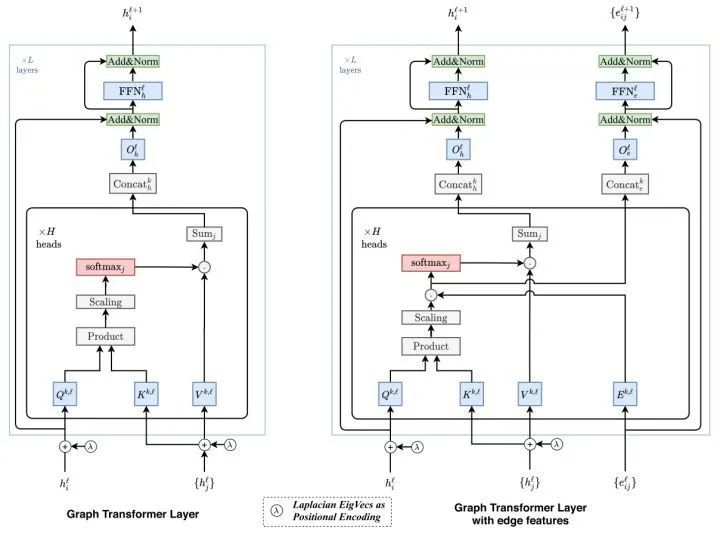
[Arxiv 2021] GraphiT: Encoding Graph Structure in Transformers
(i) leveraging relative positional encoding strategies in self-attention scores based on positive definite kernels on graphs, and (ii) enumerating and encoding local sub-structures such as paths of short length
[NIPS 2021] (GraphTrans) Representing Long-Range Context for Graph Neural Networks with Global Attention
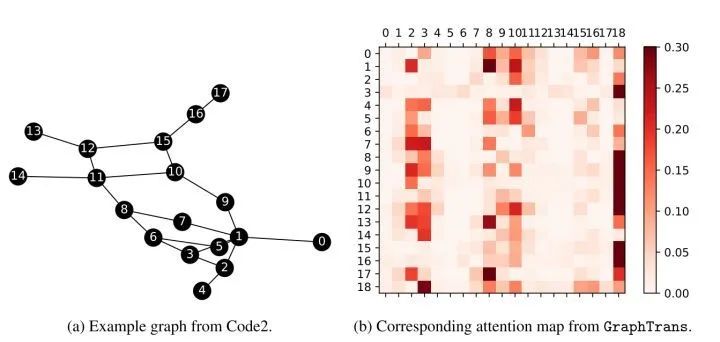
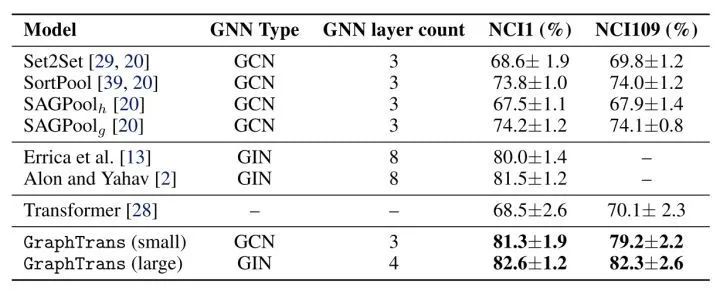
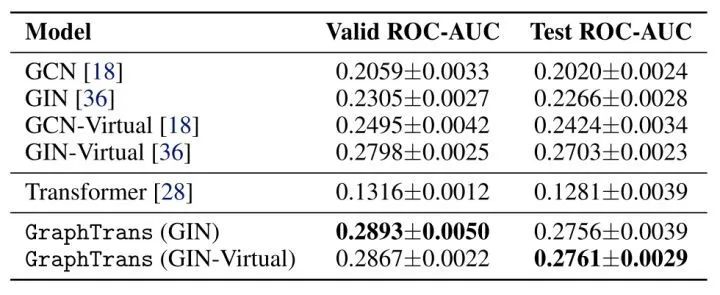
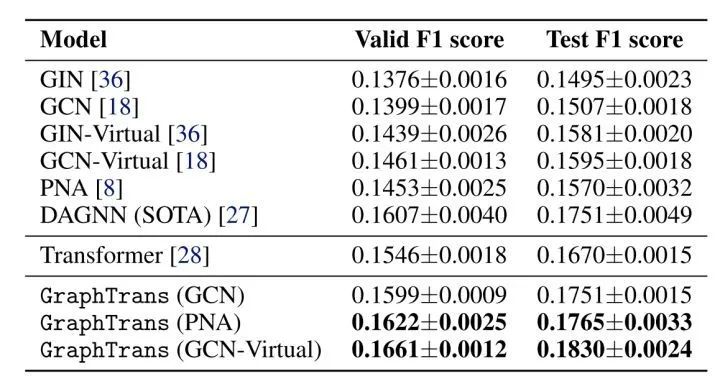
[NIPS 2021] (SAN) Rethinking Graph Transformers with Spectral Attention
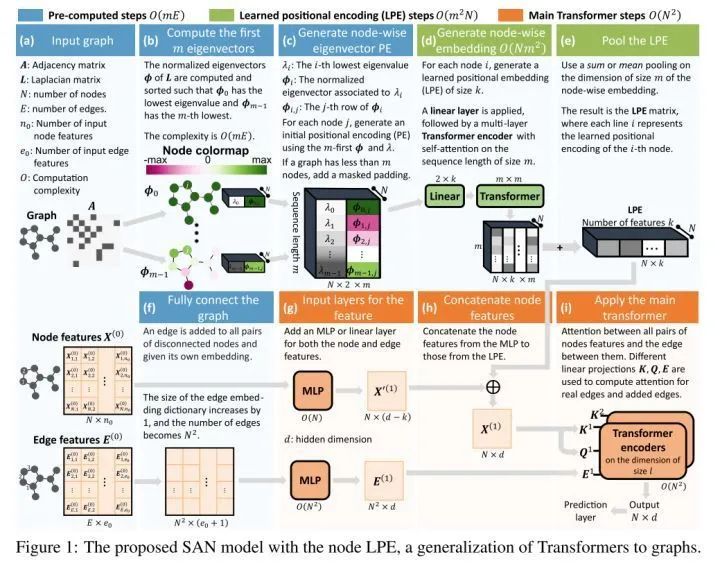
[NIPS 2021] (Graphormer) Do Transformers Really Perform Bad for Graph Representation?
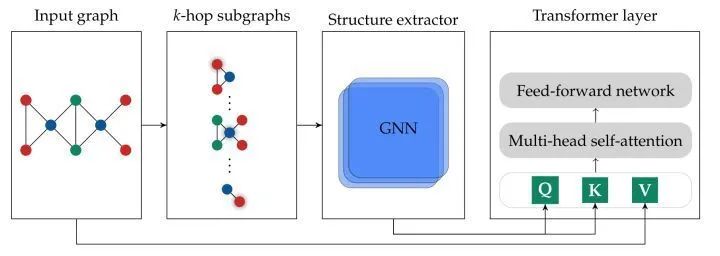
[ICML 2022] (SAT) Structure-Aware Transformer for Graph Representation Learning
这篇论文和GraphTrans比较类似。也是先通过GNN得到新的节点表征,然后再输入到GT中。只是这篇论文对抽取结构信息的方式进行了更抽象化的定义(但是出于便利性,还是使用了GNN)。还有一点不同就是这篇论文还使用了PE(RWPE)。
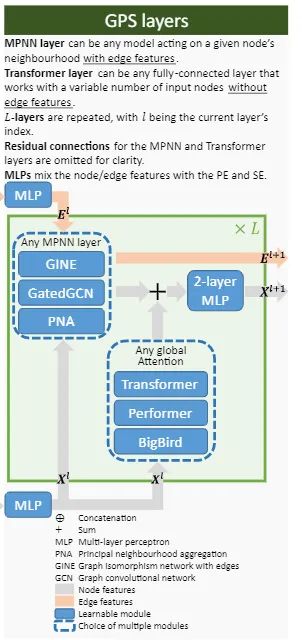
[NIPS 2022 Under Review] (GraphGPS) Recipe for a General, Powerful, Scalable Graph Transformer
-
positional/structural encoding,
-
local message-passing mechanism,
-
global attention mechanism。

-
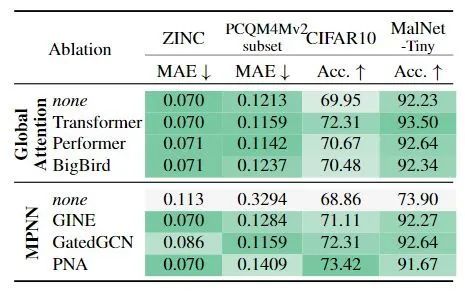
使用不同的Transformer,MPNN:可以发现不使用MPNN掉点很多,使用Transformer可以带来性能提升。
-
使用不同的PE/SE: 在低计算成本下,使用RWSE效果最佳。如果不介意计算开销可以使用效果更好的 。
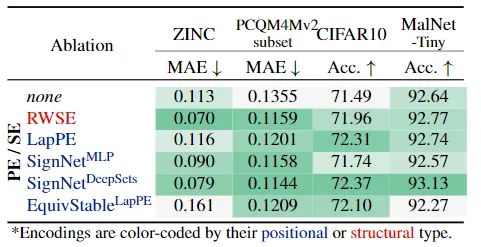
-
Benchmarking GPS
-
Benchmarking GNNs
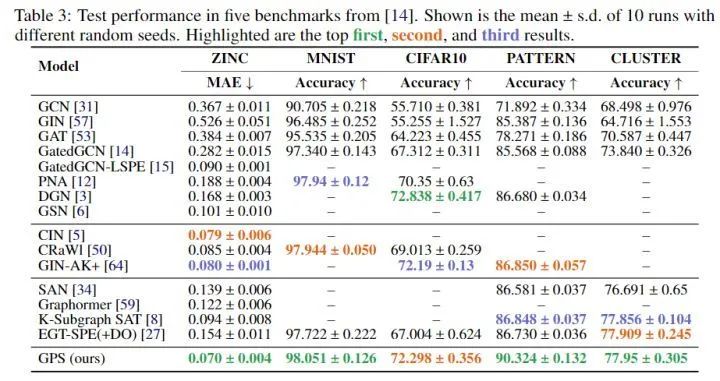
-
Open Graph Benchmark
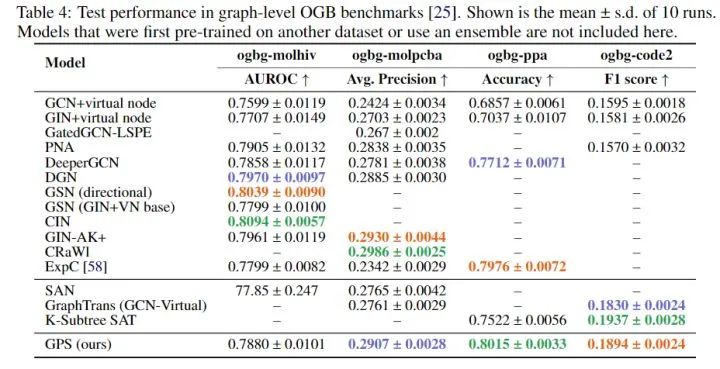
-
OGB-LSC PCQM4Mv2
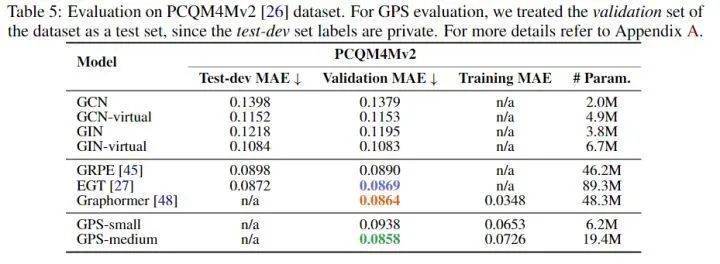
方法汇总
注:这篇文章主要汇总的是同质图上的graph transformers,目前也有一些异质图上graph transformers的工作,感兴趣的读者自行查阅哈。
-
图上不同的transformers的主要区别在于(1)如何设计PE,(2)如何利用结构信息(结合GNN或者利用结构信息去修正attention score, etc)。
-
现有的方法基本都针对small graphs(最多几百个节点),Graph-BERT虽然针对节点分类任务,但是首先会通过sampling得到子图,这会损害性能(比GAT多了很多参数,但性能是差不多的),能否设计一种针对大图的transformer还是一个比较难的问题。
代码参考
-
GRAPH-BERT: Only Attention is Needed for Learning Graph Representations (https://github.com/jwzhanggy/Graph-Bert)
-
(GROVER) Self-Supervised Graph Transformer on Large-Scale Molecular Data (https://github.com/tencent-ailab/grover)
-
(GT) A Generalization of Transformer Networks to Graphs (https://github.com/graphdeeplearning/graphtransformer)
-
GraphiT: Encoding Graph Structure in Transformers [Code is unavailable]
-
(GraphTrans) Representing Long-Range Context for Graph Neural Networks with Global Attention (https://github.com/ucbrise/graphtrans)
-
(SAN) Rethinking Graph Transformers with Spectral Attention [Code is unavailable]
-
(Graphormer) Do Transformers Really Perform Bad for Graph Representation?(https://github.com/microsoft/Graphormer)
-
(SAT) Structure-Aware Transformer for Graph Representation Learning [Code is unavailable]
-
(GraphGPS) Recipe for a General, Powerful, Scalable Graph Transformer(https://github.com/rampasek/GraphGPS)
其他资料
-
Graph Transformer综述(https://arxiv.org/abs/2202.08455);Code(https://github.com/qwerfdsaplking/Graph-Trans)
-
Tutorial: A Bird's-Eye Tutorial of Graph Attention Architectures (https://arxiv.org/pdf/2206.02849.pdf)
-
Dataset: Long Range Graph Benchmark (https://arxiv.org/pdf/2206.08164.pdf);Code(https://github.com/vijaydwivedi75/lrgb)
简介:GNN一般只能捕获k-hop的邻居,而可能无法捕获长距离依赖信息, Transformer可以解决这一问题。该benmark共包含五个数据集(PascalVOC-SP, COCO-SP, PCQM-Contact, Peptides-func and Peptides-struct),需要模型能捕获长距离依赖才能取得比较好的效果,该数据集主要用来验证模型捕获long range interactions的能力。
-
[KDD 2022] Global Self-Attention as a Replacement for Graph Convolution (https://arxiv.org/pdf/2108.03348.pdf)
-
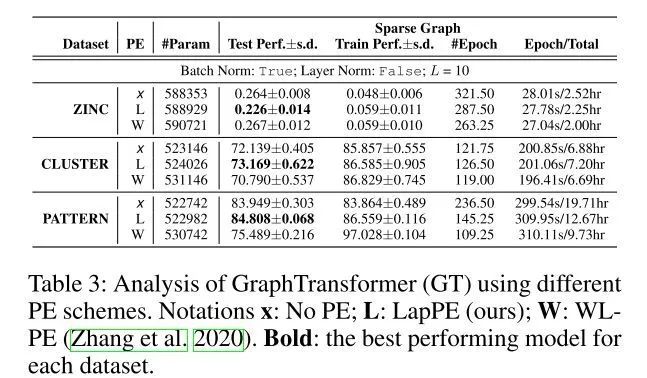
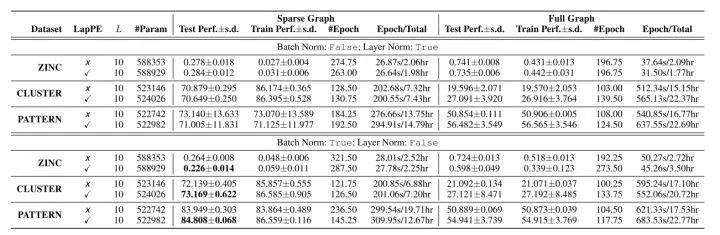
[ICOMV 2022] Experimental analysis of position embedding in graph transformer networks (https://www.spiedigitallibrary.org/conference-proceedings-of-spie/12173/121731O/Experimental-analysis-of-position-embedding-in-graph-transformer-networks/10.1117/12.2634427.short)
-
[ICLR Workshop MLDD] GRPE: Relative Positional Encoding for Graph Transformer (https://arxiv.org/abs/2201.12787);[Code] (https://github.com/lenscloth/GRPE)
-
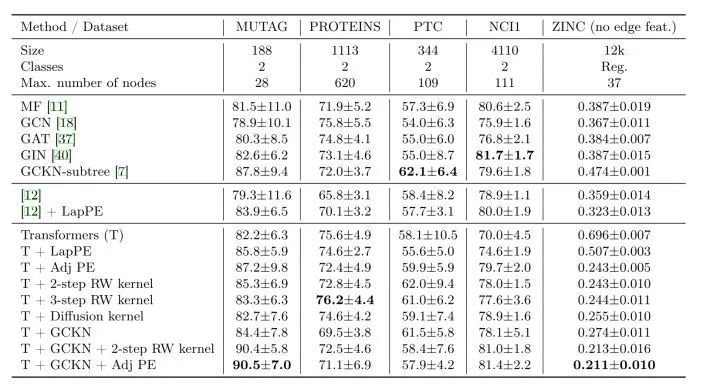
[Arxiv 2022,05] Your Transformer May Not be as Powerful as You Expect (https://arxiv.org/pdf/2205.13401.pdf);[Code] (https://github.com/lenscloth/GRPE)
-
[Arxiv 2022,06] NAGphormer: Neighborhood Aggregation Graph Transformer for Node Classification in Large Graphs (https://arxiv.org/abs/2206.04910)
公众号后台回复“目标检测综述”获取目标检测(2001-2021)综述PDF~

“
点击阅读原文进入CV社区
收获更多技术干货
