论文浅尝 | 异构图 Transformer
笔记整理:许泽众,浙江大学博士在读
论文链接:https://arxiv.org/abs/2003.01332
本文主要提出一种处理异构图的方法,所谓异构图(Heterogeneous graph)是指在一个图中会出现不同类型的边和节点的图。早期对于图的处理图的方法一般集中于同构图的处理。近年来开始关注对异构图的处理,但是一般都具有以下缺点:
1.大多涉及到为每种类型的异构图设计元路径(meta-path),但是这种元路径需要手工定义,这不仅需要领域知识,同时降低了效率;2.或者假设不同类型的节点/边共享相同的特征和表示空间,这显然是不合适的;或者单独为不同节点类型或边类型保留各自单独的非共享权重,这忽略了异构图之间的交互性;3.大多忽略了每一个(异构)图的动态特性(个人觉得这一点和之前的两点不是在解决同一个问题,应该知只是为了丰富文章内容);4.无法对Web规模的异构图进行建模。
为了处理异构图,文章的核心思想是将每条边的模型参数分解为三个矩阵相乘。其分解根据每条边的三元组 <初始节点类型,边类型,目标节点类型>来定义。这就是文中所提的元关系(meta-relation)。整体的计算参照transformer。以下图为例:
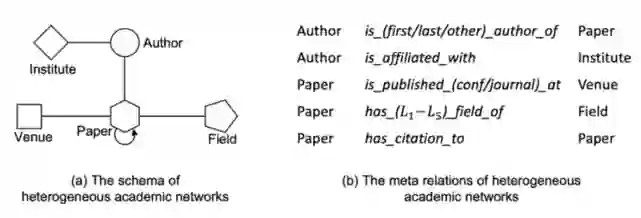
对于左图这样的异构图,可以定义出不同的元关系,每个meta-relation由三部分组成。文中提出相比于R-GCN,HGT的优势在于因为使用了三部分来定义元关系,这使得模型对于出现频次较低的关系的学习能力更强(因为另外两部分出现的频次可能不低)。
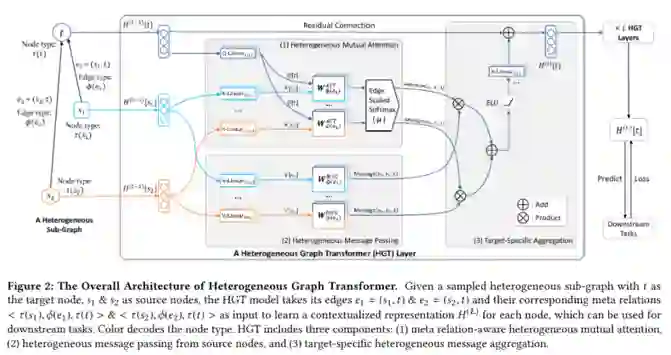
整个模型的框架可以分为三部分:Heterogeneous Mutual Attention,Heterogeneous Message Passing 和 Target-Specific Aggregation。分别用来计算attention,传递信息,信息聚合。
第一部分
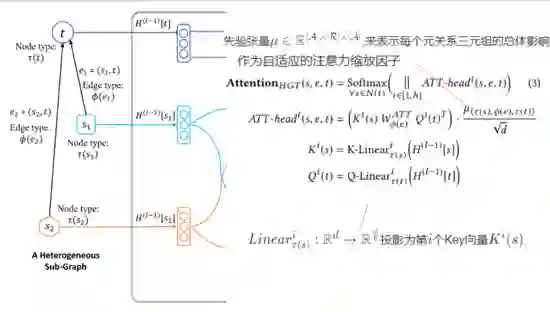
受transformer的启发,将目标节点映射为query,源节点映射为Key。
与传统Transformer不同的点在于:HGT中每个元关系都有一组不同的投影权重W,传统Transformer是所有单词使用同一组权重。
ATT-head表示第i个注意力头;K(s) 代表源节点s投影成的第i个Key向量;Q(t) 代表目标节点t投影成第i个Query向量;μ(·) 表示每个关系三元组的一般意义,作为对注意力自适应缩放;
Attention(·) 的操作主要是把h个 ATT-head 连接,得到每个节点对(s,t)的注意力向量;从本质上说,该操作就是对于每个目标节点t,从邻接节点N(t)收集的注意力向量,再进行一次softmax得到概率分布。
第二部分
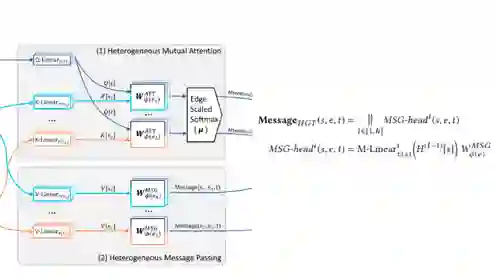
与第一步类似,这一步也将元关系融入信息传递过程来缓解不同类型节点和边的分布差异。
第三部分
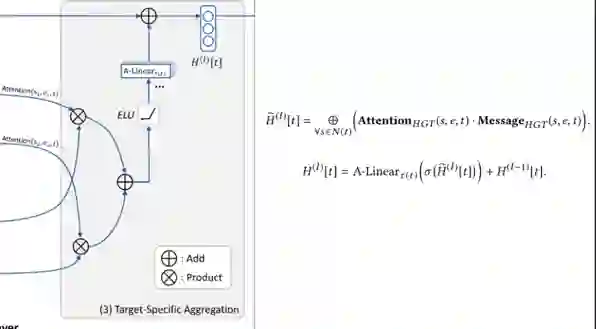
最后一部分依据前两部分的计算结果将表示更新。
文章的第二部分主要是提出相对时间编码(RTE)技术处理动态图。
传统的方法是为每个小时间片(time slot)构建图,但这种方法会丢失大量的不同时间片间的结构依赖信息。
因此,受Transformer的位置编码(position embedding)启发,作者提出RTE机制,建模异质图上的动态依赖关系。
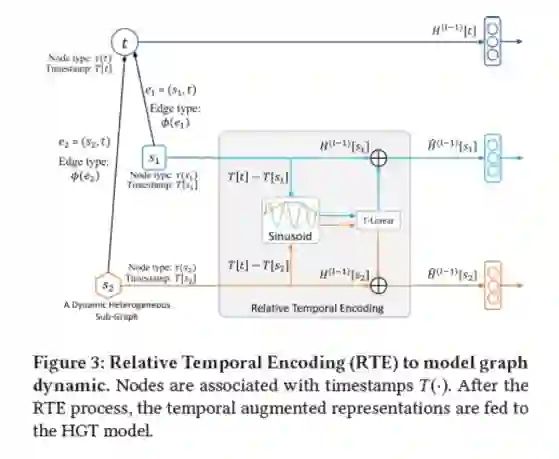
主要思想就是将时间差的信息编码到表示中从而引入时间对表示的影响。这里有一点在于train的时候见过的时间差不能覆盖所有可能的时间差,所以作者引入以下偏置函数将时间差泛化到可见范围。
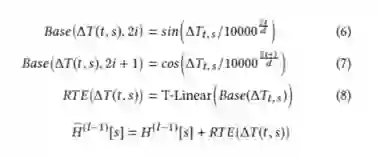
为了处理web规模的数据,设计了针对异构图的采样算法 HGSampling。它的主要思想是样本异构子图中不同类型的节点以相同的比例,并利用重要性采样降低采样中的信息损失。
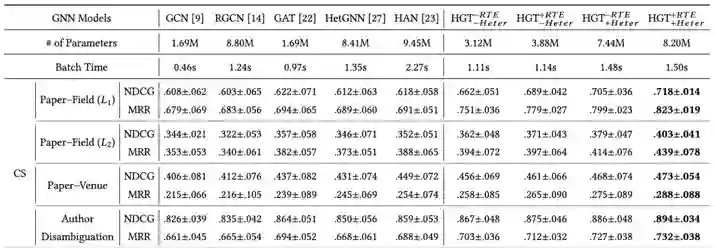
本文在其之前举例的开放学术图谱上进行实验:

但是这里值得注意的是,在对各种entity进行embedding的初始化的时候,实际上添加了相当多的信息,例如对field、venue等节点,就采用了自己argue的metapath2vec模型来进行初始化,所以实验结果的有效性应该也与这种设定有较强的关系。以下是部分实验结果:
同时还给出了一个根据计算的attention自动构建的meta-path的样例:
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。




