作者 | 黄 锋
审核 | 付海涛

今天给大家介绍清华大学计算机科学与技术系唐杰教授课题组发表于KDD 2022上的论文“GraphMAE: Self-Supervised Masked Graph Autoencoders”。这篇论文将掩码自编码器MAE引入到graph领域中,在涉及三个图学习任务的21个数据集上执行了大量的实验,实验结果表明在图自编码器上一点简单的改进能够产生超越最近的对比式和生成式自监督的SOTA性能。
引言
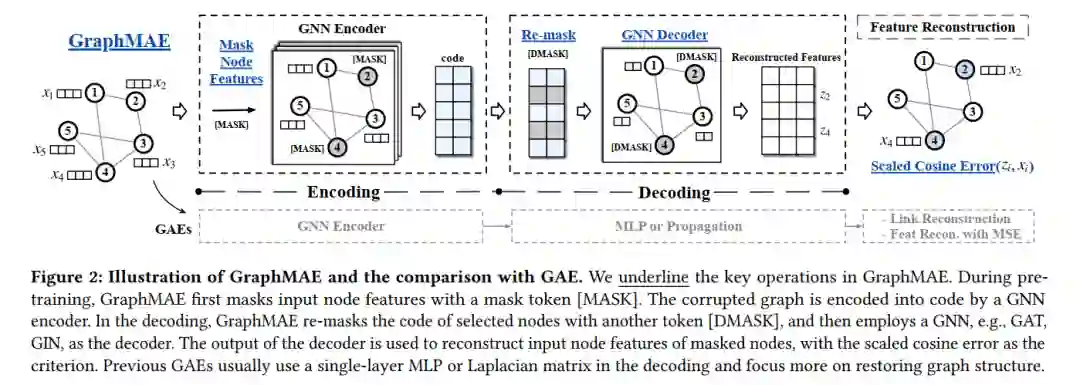
生成式自监督模型在NLP和CV领域得到广泛应用,而在graph领域对比学习占据主导地位,不论是节点分类还是图分类任务,生成式自监督的性能都被对比学习甩“几条街”。虽然如此,对比学习却有着致命缺陷,它要么过度依赖于数据增广,要么需要使用负采样、动量更新或指数滑动平均等策略来避免训练时陷入平凡解。而生成式自监督,特别是图自编码器通常目标是重建图自身的节点特征或结构信息,则会完全规避对比学习的局限。本文发现利用图自编码器,稍加改进,仅仅重建节点特征便能够获得优越的性能。GraphMAE的改进如下图所示:

概括地讲,改进主要是四点:1,掩码特征重建,不重建边;2,不同于大多数图自编码器使用的均方误差,GraphMAE使用缩放余弦误差作为损失函数;3,将编码器输出的嵌入重新掩码后再输入到解码器中;4,比起大多数图自编码器的解码器用多层感知机,GraphMAE的解码器使用图神经网络。 GraphMAE在无监督节点分类、无监督图分类以及在分子性质预测上的迁移学习三个任务共21个数据集上取得了与对比学习差不多,甚至是更好的效果。
方法
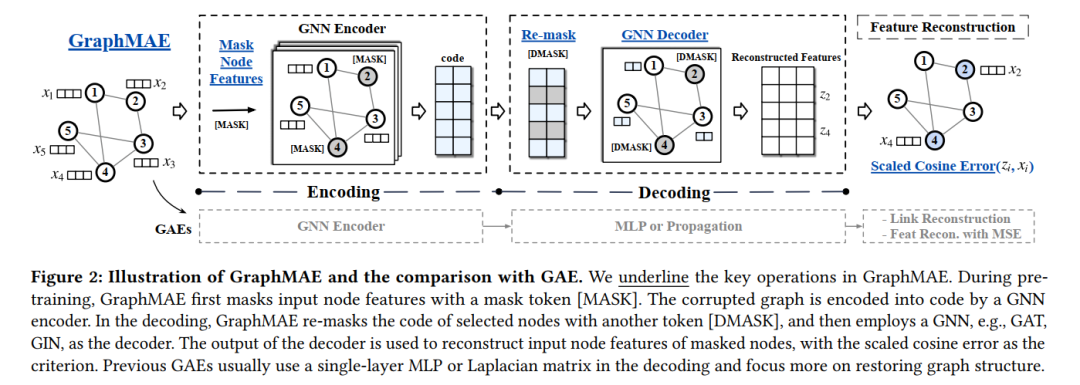
掩码特征
给定一个属性图,输入到编码器前对进行类似BERT中的掩码操作,具体来说,GraphMAE是随机选取一个节点子集,将这些节点的特征替换成一个可学习的向量:
对编码重掩码
设经过编码器得到的编码,继续对先前选取的那部分节点重新掩码,即替换为: 使用图神经网络作为解码器,希望其能从未掩码的部分编码恢复成节点特征。
缩放余弦误差
不同于大多数图自编码器模型使用的均方误差,GraphMAE使用缩放余弦误差,假设由编码器恢复的节点特征为,缩放余弦误差定义为:
实验结果
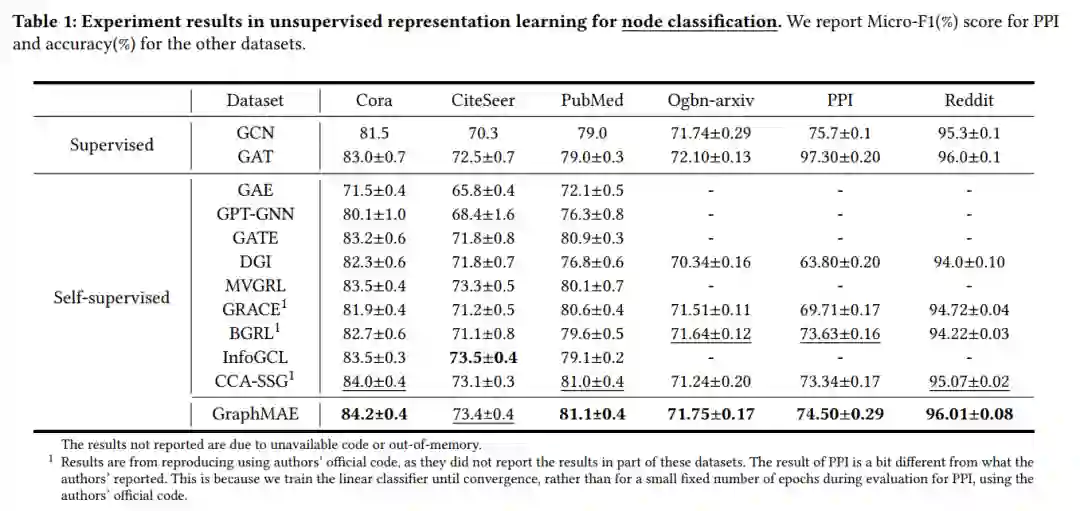
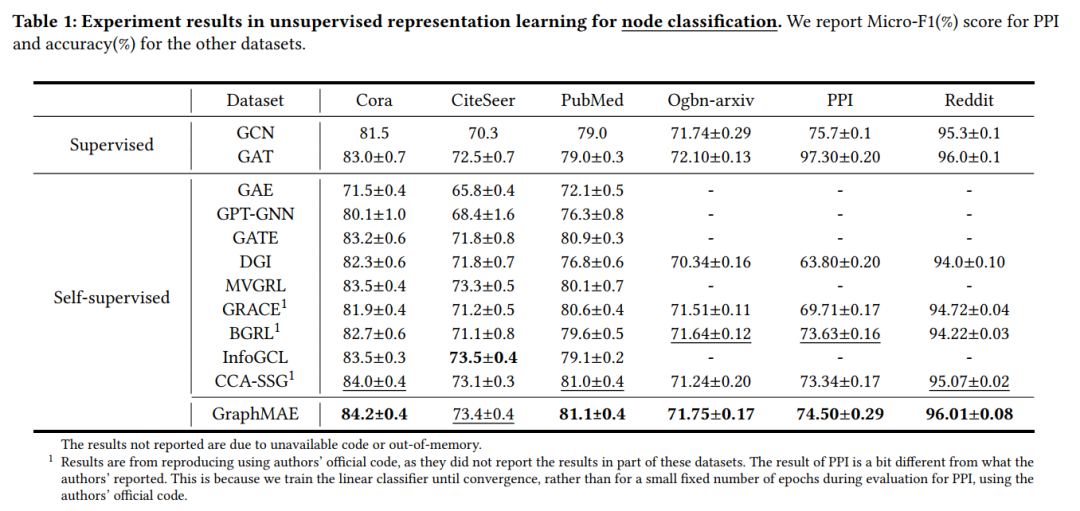
三种任务:1)无监督节点分类;2)无监督图分类;3)分子性质预测的迁移学习 下表是节点分类任务上的结果。首先是无监督的学习,接着固定编码器参数得到节点的嵌入,用节点嵌入训练一个线性分类器,列出20次随机初始化的平均结果。编码器和解码器都用的是标准的图注意力网络。更多细节参看原文。
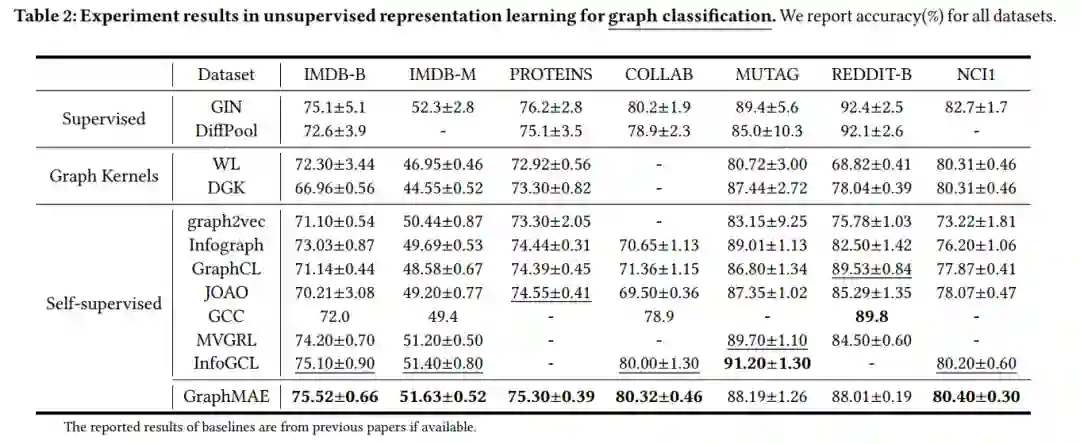
下表是图分类任务上的结果。首先无监督训练,得到节点嵌入后经过一个无参数的池化操作得到图级表达,接着训练LIBSVM作为分类器,列出5次十折交叉验证的平均结果。编码器和解码器都是用的图同构网络。更多细节参看原文。

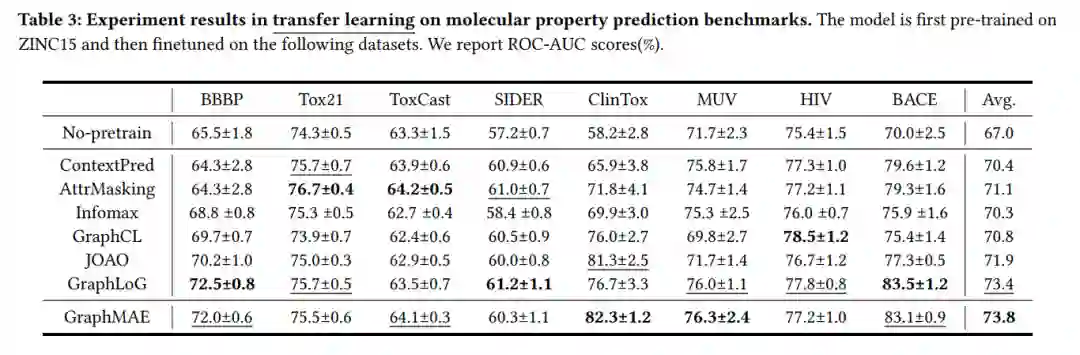
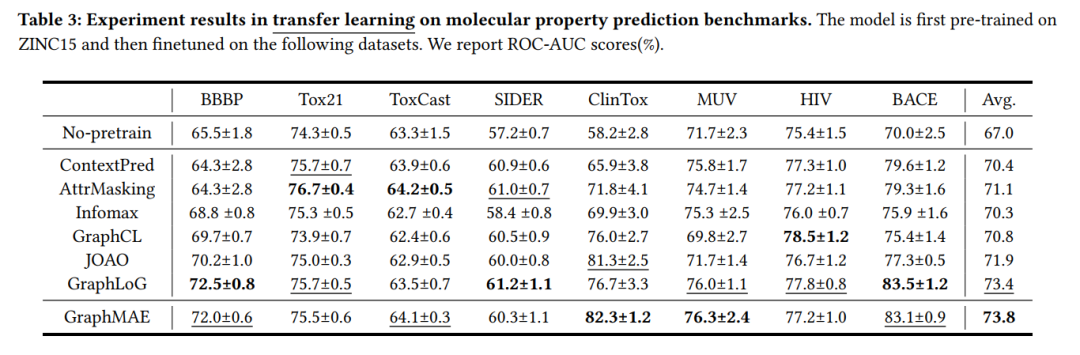
下表是分子性质预测的结果。首先在大数据集上无监督训练,接着在小数据上微调。更多细节参看原文。
参考文献
文章地址
https://arxiv.org/abs/2205.10803