Recsys2021 | 基于Transformer的会话推荐
这一回主要讲解Transformers4Rec论文主体提出的方法。

本文提出了一整套序列推荐建模的pipeline,包括了数据预处理/特征工程模块;模型训练和评估模块和Transformers元架构模块等。几个亮点可以提前预览下,
1.数据预处理模块引入了NVIDIA开源的Tabular[1]库,能够显著降低从原始数据到模型输入之间的转换时间,提高训练和推理性能。
2.模型训练与评估模块主要在HuggingFace库基础上做适配序列推荐的定制。
3.Transformers元架构模块主要介绍了:
-
输入特征如何做表征(例如:连续值的soft one-hot嵌入方法); -
嵌入绑定(Tying Embeddings)技巧能大幅提升指标,通过嵌入绑定,能巧妙地实现类似推荐系统中的 user/item矩阵分解的效果。 -
融合连续型特征时,在原始特征基础上使用 layer normalization后再融合,指标也会大幅提升。 -
各种各样的 Transformers架构可以定制使用,比如原始的Transformers,XLNets中针对 长序列的Transformers-XL等。对序列建模影响挺大。
4.Transformers在序列推荐中的应用,如何才能达到最优的性能?
-
序列推荐的 训练方法很重要。介绍了如何将NLP中预训练的方法用到序列推荐中,包括 CLM, MLM, PLM, RTD等等,和传统的序列推荐训练方法有很大的区别。 -
不同的 Transformers架构影响也挺大。例如:BERT和XLNets中用到的Transformers架构表现存在差异。 -
介绍Transformers架构 如何建模辅助信息最合适。
5.作者用Transformers4Rec工具赢了两个顶会会话推荐比赛的Top名次 (check了官网的Leaderboards),分别是,
-
Top1, WSDM WebTour Workshop Challenge 2021, organized by Booking.com [5].。 -
Top2, SIGIR eCommerce Workshop Data Challenge 2021, organized by Coveo [6]。
这两个比赛都有对应的方案论文放出来,感兴趣的可以结合代码深入读读他们的方案论文,应该会收获更大。
ps. 源码核心demo入口:tests/torch/model/test_model.py,可以看model.fit()看整个训练过程。初读下来,我只能说代码能力是真强,API封装的很好,开箱即用。有机会我再分享分享。
1. Motivation
上一篇文章介绍过,近年来序列/会话推荐上的进展很多都源自于NLP模型和预训练技术的发展,可以说推荐系统是在NLP的肩膀上前进的。尤其是Transformer架构,在BERT等预训练模型中广泛应用,也在序列推荐中初露端倪。然而,推荐系统的发展实际上是滞后于NLP的,很大程度上是缺乏一个类似HuggingFace的统一轮子,研究者想在此基础上做迭代实际上相比于NLP会困难不少。
为了弥补这种发展鸿沟,作者开源了一个基于HuggingFace开源库[4]的序列推荐包Transformers4Rec,目的是希望推荐系统社区能够更快地follow到NLP社区在Transformers中的进展,并在序列/会话推荐任务中实现开箱即用。
那么这个库除了API层面的开发以外,还有什么优势呢?为了展现这个库的强大之处,作者在这篇论文中集中展现了:
-
提出了一整套 序列推荐建模的pipeline,包括了数据预处理/特征工程模块;模型训练和评估模块以及Transformers元架构定制和设计模块。 -
Transformers在 序列推荐中的应用, 如何才能达到最优的性能? -
作者用 Transformers4Rec工具赢了WSDM21和SIGIR21两个 顶会会话推荐比赛的top名次。
完整的代码开源在了github:https://github.com/NVIDIA-Merlin/Transformers4Rec/
下面的第一部分主要介绍pipeline;第二实验部分主要就是介绍如何让Transformers在序列推荐场景中大放光彩。
2. Transformers4Rec的Pipeline
一种端到端的推荐系统框架,包括:数据预处理、模型训练和评估。整体上,
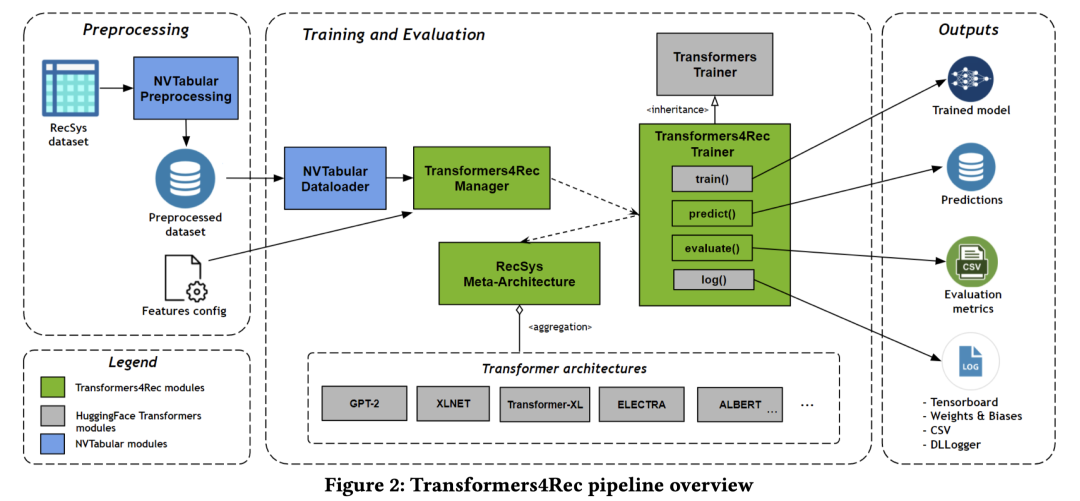
-
左图原始输入数据经过 NVTabular处理后转化为模型的输入,这里头还涉及到 特征工程。输入字段可通过可配置的文件来指定。 -
中间的 训练和评估模块加载数据并调用了底部的Transformers模型(核心),来做前向传播和后向传播等。具体的,重载了HuggingFace的trainer类,在子类中实现序列推荐的训练,评估和预测。训练方法有多种多样,借鉴预训练模型的方法;评估指标主要是推荐系统中常用的排序指标。 -
最后右侧输出训练好的模型,预测结果,评估指标、训练过程监控等等。
2.1 数据预处理和特征工程模块
数据预处理通常是线上推荐系统推理时的常见瓶颈。即:从原始数据到模型输入之间,存在着数据预处理和特征工程步骤,通常是比较耗时的。本文采用了NVIDIA开源的Tabular[1]库,一种面向深度推荐系统中表格型数据的预处理和特征工程库,能够实现在GPU上加速,无缝衔接tensorflow和pytorch。在现有的tensorflow pipeline上提速9倍,pytorch pipeline上提速5倍。
Transformers4Rec集成了Tabular,输入原始数据,输出结构化、可查询的Parquet数据格式。然后使用特定的NVTabular DataLoader将Parquet格式的数据文件直接读进GPU显存中,使得模型训练和评估更快。
为了描述输入特征,Transformers4Rec也采用了一个可配置的文件来配置模型的输入特征,特征类型(稠密/离散),特征元数据(size等)等。
文中提到的特征工程技巧也是挺有意思的,主要在实验部分,我先搬上来。比如频次特征提到用GaussRank来预处理,Kaggle常用技巧[4];对于时间特征用cosine或者sine周期性函数等。
2.2 模型训练和评估模块
HuggingFace的Transformers库用了自己优化后的训练和评估pipeline到NLP任务中,组织成Trainer类。Transformers4Rec继承了这个类,并重载了predict和evaluate方法,使之适配推荐任务。
Transformers4Rec的元架构Recsys Meta-Architecture是个高可配置的组件,支持如下功能:构建特征处理的计算图;序列masking方法;Transformers结构的定制;预测头的定制以及损失函数的定制。
评估组件则采用了传统的Top-N排序指标,如NDCG@N,Recall@N,Precision@N,MAP@N等。
可以输出的产物包括:训练好的模型,预测结果,评估指标和log文件等。
同时,Transformers4Rec支持增量训练和增量评估流程,和线上环境中的流式训练相吻合,比如以一定的频率,1天训练1次或1小时训练1次,每次加载此前训练好的模型,在新的流式数据上进行fine-tuned,再实时部署和推理。
2.3 Transformers4Rec的元架构模块
前面介绍的都是皮/包装,最关键的还是Transformers核心元架构。如何快速对模型进行深度的定制和改进是最关键的。整体上:
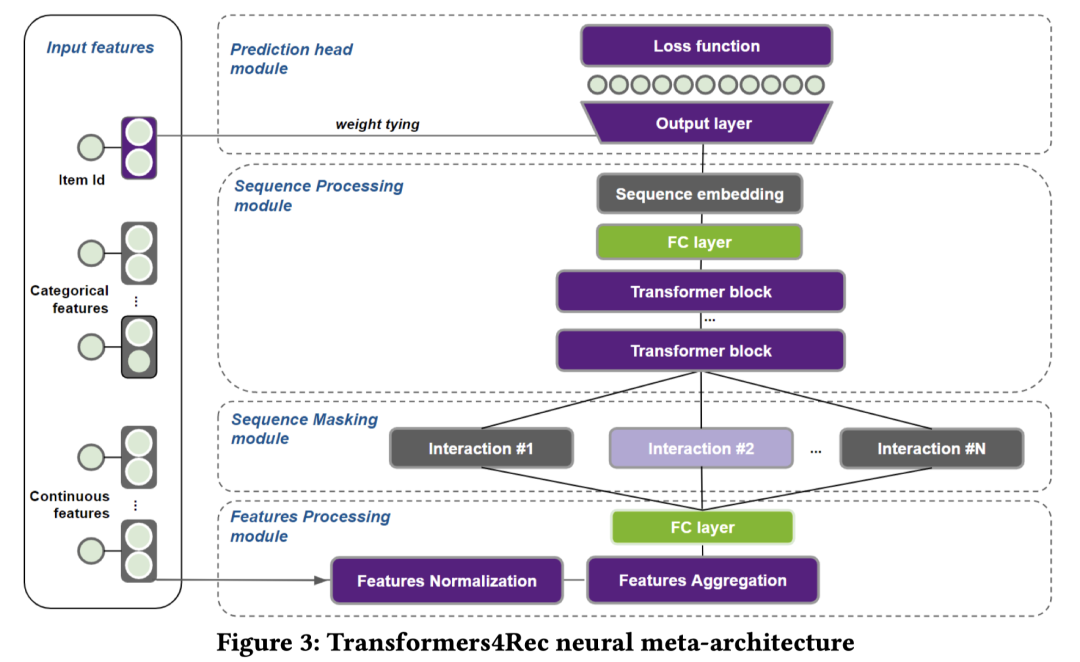
-
Input Features:左侧的特征做嵌入表征,包括离散值和连续值的表征。 -
Features Processing Module:右侧底部对特征做Normalization操作,通过实验部分发现实际上是对连续值表征做了Layer Normalization,然后对离散/连续嵌入做特征融合,形成序列单个step的输入表征。 -
Sequence Masking Module:对序列做mask操作,主要是配合模型训练方法,比如RTD训练方式,就得替换某个item;MLM训练方法,就要随机mask某个item。 -
Sequence Processing Module:核心模型代码,序列建模方法,如何用Transformers进行序列建模。 -
Prediction Head Module:预测头模块,映射到整个 item空间,用到了weight tying这种重要技巧。推理时做next-item prediction,训练时根据训练方法CLM, MLM, PLM, RTD等做训练。
2.3.1 输入特征表征子模块:Input Feature Representation
这个模块主要负责单个特征的嵌入表征。NLP模型通常用words或sub-words来作为token ids。同样的,在推荐系统中,item id是表示交互行为的最重要特征。与此同时,还有一些其它额外的item元特征和用户上下文特征也很重要。具体的,对应图3的左侧部分:
-
类别型特征直接做嵌入。
-
连续型特征可以用一个实数常量表示,或常量的线性变换,或soft方式的one-hot表征。对于soft的one-hot表征,形式化地,假设连续型输入特征为 ,先做一个线性变换,得到:
其中, , ,即将特征映射到 维的向量。然后过一个softmax激活得到1个 维的概率分布向量:
再用该概率分布对Embedding Table 做加权求和得到soft方式的one-hot表征 ,即:
上述表征会经过归一化算子Features Normalization(文中没有具体介绍细节)后输入到特征融合模块。
2.3.2 输入特征融合子模块:Input Feature Aggregation
这个模块主要负责序列特征在单个step下,不同输入特征的融合,如item id和item的side information。和NLP中1个step通过只用1个word/token id来表示不太一样,推荐系统每个step下的item表征,除了item id之外,还有其它的side information。该模块会对单个step下的不同输入特征的表征向量做融合,形成单个step的整体表征向量。
首先每个序列 由 个items构成,则item id的序列表示为: 。同样的第 个特征构成的序列为 ,则所有的 个特征构成的序列集合表示为:,
支持两种的特征融合方式:
-
基于拼接的融合:对于序列的第 个step表征,item id的表征和其它特征的表征拼接在一起输入。
-
基于Element-wise的融合:,每个item的side information向量先全部相加,加上一个全1向量后,和item id向量做element-wise乘法。
这个式子的解释如下:由于每个feature向量的初始化参数服从均值为0的高斯分布,则element-wise的第二项服从均值为1的高斯分布。那么和item id向量做element-wise乘法时,充当着对item id的向量做mask或attention的角色。
2.3.3 嵌入绑定技巧:Tying Embeddings
【炼丹经验】NLP中会经常用到输入层向量和输出层向量共享一个嵌入矩阵,也即:二者绑定在一起。这主要是因为对于语言模型,输入输出都是词,二者应该处于同一向量空间。这怎么理解?我们以最原始的CBOW的word2vec为例:
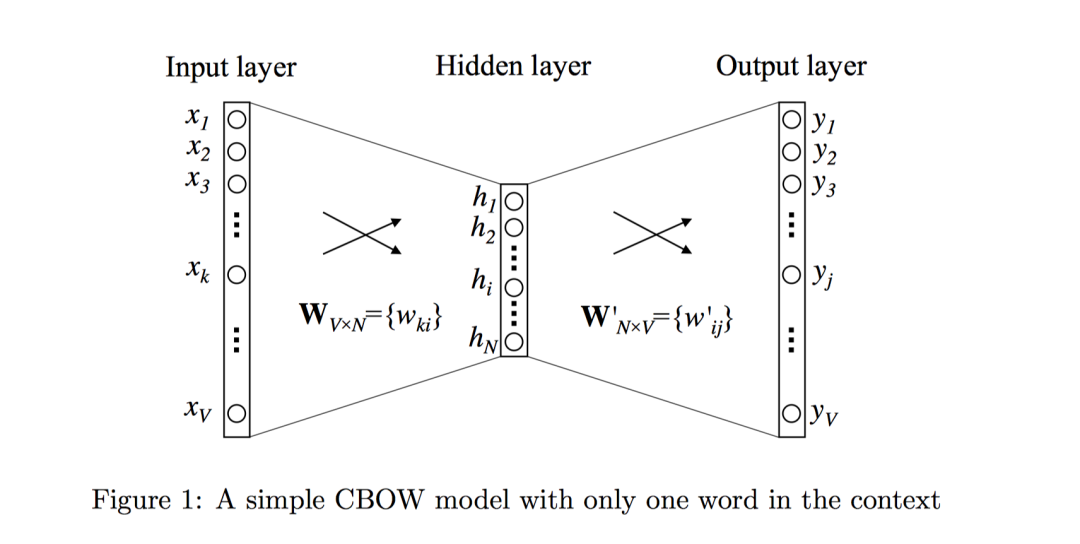
其实就是原始one-hot(V维)的word会经过1个 做嵌入映射到 维;在输出层要过一个softmax全连接层 并输出词的概率分布,前一个 可以等价的认为是输入word的嵌入矩阵,后一个 是输出word的嵌入矩阵。正常情况下两个矩阵是不一样的,但是为了保证输入词和输出词在同一个向量空间,同时能节约空间,这两个矩阵通常绑定在一起,用一个同一个嵌入矩阵来表示就行了。
反过来对于序列推荐而言,输入的特征同样需要做嵌入;预测下一次交互行为,同样需要在输出层映射到item空间。二者同样可以共享。通过嵌入绑定操作,
可以大幅度减少参数的大小,同时也是一种正则化手段,特别是长尾的item嵌入,通过输出层的参数共享,能够得到更好的更新。
序列表征层的输出实际上代表了user或session最终的表征向量;而输入层表征代表了item的表征。通过这种嵌入绑定的方式,输出层的矩阵乘法操作等价于user向量和item向量做乘法,也即提供了1种item表征和user表征做矩阵分解的操作。非常巧妙!怎么理解呢?如下图所示:sequence embedding即为user表征,原本接一个全连接层输出next prediction分布,现在全连接层用item embedding来表示,就相当于user embedding和item embedding做了个矩阵乘法。
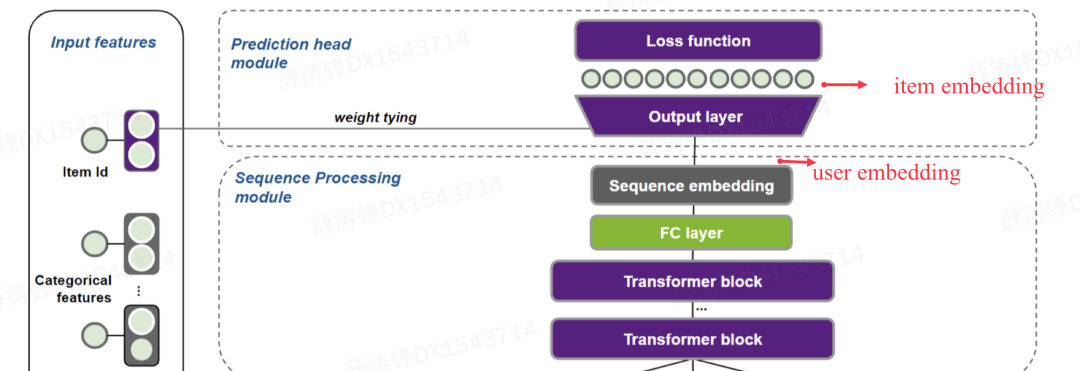
2.3.4 其它特点
-
正则化:Regularization,支持多种多样的正则化策略:dropout,weight decay,softmax temperature,layer normalization,Stochastic Shared Embeddings,Label Smoothing等。
-
损失函数:Loss Functions,支持许多损失函数,交叉熵;pairwise损失:BPR, TOP1, BPR-max, TOP1-max等。
-
拓展性:Extensibility可以允许多种多样的序列输入,每种序列可以单独用Transformer处理后再融合起来(或者像前文所述先融合后,再做序列表征)。也支持多任务学习,通过加预测头以及单独损失函数的方式即可实现。
3.实验
主要想看不同的Transformers架构以及不同的训练方法对于序列推荐的影响。
3.1 实验设定
数据集包括两类:
-
电商领域 -
REES46 eCommerce, 大规模数据; -
YOOCHOOSE eCommerce,RecSys Challenge 2015的数据集。 -
新闻领域 -
G1 news,巴西最著名的媒体公司。 -
ADRESSA news。
新闻数据集更长尾。数据预处理部分,连续重复的交互会删除掉,忽略长度为1的session。根据时间窗口来划分sessions,电商数据1天为区间长度,即1天为一个时间窗口;新闻数据1个小时为一个时间窗口(时效性要求很高,窗口尽量小)。
数据划分:划分为T个窗口,每个窗口里会有很多sessions。对每个 , ,都会用前面所有窗口内的sessions数据做训练集 ,在 的sessions测试集上做预测。而每个窗口 下,会把所有的sessions做划分,划分为5/5开的训练集和验证集,验证集主要用于调参,测试集看指标。
最后放出来的指标是五组相互独立、随机种子不同的实验的平均结果。而每个指标计算时,会算所有时间窗口下的平均值,即:Average over Time (AoT),主要通过增量训练实现的,这和流式更新序列模型的真实情况比较吻合。
指标:NDCG@20,HitRate@20。
3.2 对比实验
-
第一类Session-based的K近邻搜索:如STAN,SKNN,V-SkNN和VSTAN,这类方法主要利用了跨序列的协同信息,先计算session与session之间的相似性,再推荐和目标session相似的其它session中的item,来作为推荐结果,有点类似Item-CF。
-
第二类神经网络方法:GRU4Rec,NARM,STAMP和SR-GNN。主要是基于序列本身做建模。但是做实验只选了GRU4Rec。
先介绍下序列推荐的几种训练方法:
-
FT是full training的缩写,即:要预测 窗口时用前面所有的窗口 来训练,常用,GRU4REC等就是这种。 -
SWT为sliding window training的缩写,即要预测 窗口时用最近的w个窗口数据来训练 ,也是常用方法,忽视掉久远的数据。 -
CLM为Causal LM语言模型训练方法,预测下一次交互,最大化整个序列的概率,传统语言模型建模常用。 -
MLM为Masked LM语言模型训练方法,每个训练步都随机掩盖住序列中的某个item,再预测被mask的item。BERT中用到的方法, -
RTD为Replacement Token Detection,随机替换掉某个item,再让模型预测序列的每个item是否被替换了,ELECTRA中用的方法。 -
PLM为Permutation LM语言模型训练方法,对输入做排列组合并做语言模型建模,XLNet中用到的方法。
上述大部分是NLP中的几种预训练方法,可以迁移到序列推荐场景下,作为序列推荐的训练方法。
实验主要关注几大问题:
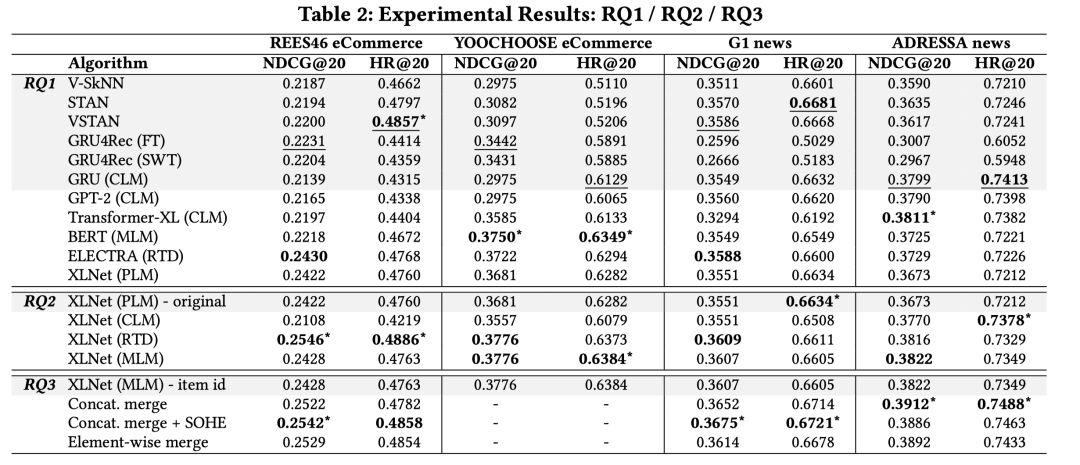
问题1:基于Transformer的架构在会话推荐这种短序列场景表现如何? 关注表格中的第一栏。
-
基于Session的K近邻搜索方法效果很不错,尤其在HitRate@20指标上。 -
GRU4Rec在NDCG@20上则表现的最好, -
Transformers架构的各种变体在NDCG@20上普遍表现不错,在电商数据集上优势比较大,而在新闻数据集上优势比较小。这可能是因为电商数据集的序列更长,需要更复杂的模型来建模。还要注意的, 没有任何一个单一的Transformers模型能够在所有数据集上都胜出,说明 可能还有调优的空间。
问题2:不同的训练方法对Transformers在序列推荐中的表现影响如何?
在问题1的基础上,深入看看Transformers在什么样的架构和训练方法下最有效。主要以XLNet对应的Transformer-XL架构为例。可以从表格中看出,RTD>MLM>CLM>PLM。RTD效果是最好的。几乎在每个数据集上,RTD都比其它的方法好。
问题3:Transformers架构如何建模辅助信息最合适?
主要对比了前文输入特征融合模块提到的方法:
-
拼接融合:离散特征做embedding,连续特征直接用归一化的原始值。全部拼接在一起。 -
拼接融合 + 连续特征做Soft One-hot Embedding(见前文输入特征表征模块) -
Element-wise融合,见前文输入特征融合模块。
【炼丹经验】在融合连续型特征时,作者强调先在原始特征基础上使用layer normalization后再融合,指标会提升很多。
使用辅助信息都是有提升的,第二种方式,拼接融合 + 连续特征做Soft One-hot Embedding的效果最好。
总结
这篇文章的创新点不是非常大,主要还是工程和开源亮点。提出了一个面向序列推荐场景的Transformers库,能够很方便的进行Transformers模型的定制,同时还分享了很多优化点和炼丹经验,个人印象比较深刻的一些点,比如:
-
连续值做 soft one-hot嵌入表征。 -
嵌入绑定 Tying Embedding大幅提升指标,能够巧妙地实现类似user/item矩阵分解的效果。 -
如何在Transformers中更好地 建模辅助信息,融合连续型特征的时候,接layer normalization对于效果影响很大。 -
将 NLP预训练的方法CLM,MLM,PLM,RTD等应用在 序列推荐场景中,和传统的序列推荐训练方法差异很大,也是 值得借鉴。
作者还亲自使用Transformers4Rec赢了两个顶会WSDM21和SIGIR21的序列推荐比赛的top名次,说明Transformers确实在序列推荐场景中还是非常强大的。笔者也浏览了下代码,确实封装设计的很不错,开箱即用,方便定制,持续关注中!后续有机会会去拜读并分享下源码以及两个比赛冠军方案。下期分享见!
参考
[1] 一种面向深度推荐系统中表格型数据的预处理和特征工程库:https://github.com/NVIDIA-Merlin/NVTabular
[2] Hidasi B, Karatzoglou A. Recurrent neural networks with top-k gains for session-based recommendations[C]//Proceedings of the 27th ACM international conference on information and knowledge management. 2018: 843-852.
[3] Liwei Wu, Shuqing Li, Cho-Jui Hsieh, and James L. Sharpnack. 2019. Stochastic Shared Embeddings: Data-driven Regularization of Embedding Layers. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett (Eds.). 24–34. https://proceedings.neurips.cc/paper/2019/hash/ 37693cfc748049e45d87b8c7d8b9aacd-Abstract.html
[4] Guass Rank:https://github.com/aldente0630/gauss_rank_scaler
[5] Benedikt Schifferer, Chris Deotte, Jean-Franćois Puget, Gabriel de Souza Pereira Moreira, Gilberto Titericz, Jiwei Liu, and Ronay Ak. 2021. Using Deep Learning to Win the Booking.com WSDM WebTour21 Challenge on Sequential Recommendations (to be published). https://www.bookingchallenge.com/. In Proceedings of the ACM WSDM Workshop on Web Tourism (WSDM WebTour’21).
[6] Gabriel de Souza Pereira Moreira, Sara Rabhi, Ronay Ak, Md Yasin Kabir, and Even Oldridge. 2021. Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation. In Proceedings of the Fifth SIGIR eCommerce Workshop 2021.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于微信公众号试行乱序推送,您可能不能准时收到机器学习与推荐算法的推送。为第一时间收到干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不能准时收到机器学习与推荐算法的推送。为第一时间收到干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


