【ICCV17论文笔记】循环注意力区域实现图像多标签分类
最近看的一篇论文是中山大学的一篇ICCV 2017论文,这篇论文主要介绍了在针对多标签图片,如何识别attention region ,并且定位到感兴趣的区域,并且输出针对类别标签的各个分数。
接下来我们尽可能顺着作者的行文思路先把整体的概念梳理一遍。
对于原文的解读,是把文章理解以后说成自己的话,肯定不会逐字逐句的解读,在解读时候我也加上了一些自己的理解。
论文题目:
【ICCV17】Multi-label Image Recognition by Recurrently Discovering Attentional Region
论文地址:https://arxiv.org/pdf/1711.02816.pdf
笔者:我一直在想我写论文笔记的目的,这篇笔记大概写了近5个小时吧。是第三遍看论文的时候才会写论文笔记(第一遍在PDF随笔 mark,第二遍手写笔记),我想对于我来说更多的是又重新加深一遍理解吧。
我希望我自己能保持下去,这次增加了论文拷问板块(文末),这对我来说很有作用。让我能够带着问题去思考。
我毕竟还是一个new CVer。一些思想上的不成熟,逻辑上的混乱,还请大佬们指出 。我一定虚心学习改正。联系邮箱:makaay@sjtu.edu.cn
Abstract
首先作者提出一个创新的结构用来解决多标签图片的识别问题。这对于视觉理解来说是一个基础并且实际的问题,但是呢,现在的常用的解决办法都是从是额外的产生假定区域(笔者:比如faster rcnn 提出的RPN区域),这样很容易导致的问题:计算的冗余性以及低性能的表现。而在这篇文字中,作者主要通过 循环可记忆model 来实现视觉上的可解释性和多标签图片分类上的标签相互联系的解释。当然,他们最主要的结构就是使用一个空间转换层(ST)来得到感兴趣的区域,并且通过LSTM来得到语义标签的分类,以及通过LSTM来得到相应的空间层转换的参数。经过验证,作者他们的模型在MSCOCO以及VOC 07上都取得了十分有效果的表现。
1.Introduction
有效的识别多标签的分类是一个很实际的问题。现在单标签分类(笔者: 每张图片对应一张标签)有时候会面临着由于视角,尺度,遮挡,光照等因素所造成的类间差。更不用说现在多标签分类的所面临的问题了。多标签的图片的多个类别的精确识别经常需要能够更加深层次的理解图片,就比如说语义标签和区域之间是如何联系的,以及他们依赖性。
接下里作者就大概介绍了下现在CNN所取得进展。然后那些传统的hypothesis region 的方法他们的缺点就是:大量计算,并且忽略了上下文之间的联系,以及标签之间的相互依赖联系(笔者:这里解释下,就比如出现了鸟,很大一部分会出现树木,或者天空,他们都是有一定的联系关系的,这就不可避免的要使用lstm)。虽然王(16年cvpr文章,这个后面我也会具体读一下的)在16年提出了CNN-RNN的方案用来解决标签之间的关系的问题。但是却忽视了标签和区域之间的联系,并且缺少探索空间背景。所以作者的对比目标就出来了,提出一个端到端的网络,然后能够得到基于语义标签的注意力区域,并且能够从一个全局的视角捕捉到上下文的标签的依赖性,并且他们的模型并不需要输出假定框。

作者接下来就说明了他们的空间转换层是用来提取相关的region,然后使用lstm来获得相应的语义标签分数以及相应的上下文信息。
作者他们的本文工作主要有三点:
第一点就是他们提出一个方法能够自己识别有语义信息的region ,然后呢,能够发现他们之间的相互联系通过LSTM。
他们在空间转换层设置了三个限制,使得region的选取能够更加的优化和顺畅,这样的话,后面的LSTM的效果也会变得很好。
他们做了大量的对比试验,发现他们的模型在打的数据集上依然表现的很好。
2.Related Works
依然是先介绍下图片分类的相关工作,例行结构。
然后说明上述所有提到的方法都没有解决区域和标签之类的问题,并且容易受到复杂背景的影响。
然后又提了几个论文,虽然解决了区域和标签的问题,但是又产生了效率的问题。并且没有办法形成端到端的结构,没法直接进行训练。
注意力区域是由sT模型产生。
3.Model
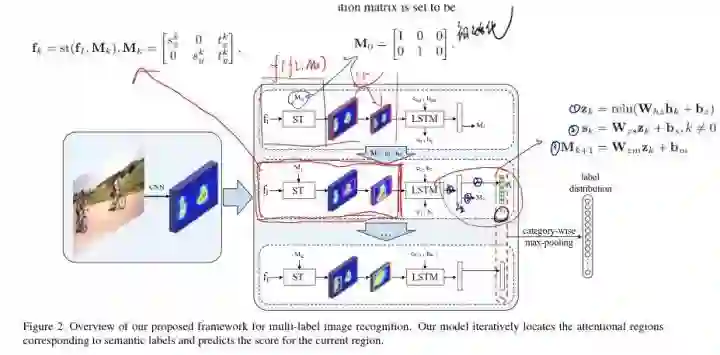
接下来重点介绍下模型:下图是模型的整体描述,我已经把他基本用到的公式都已经重点贴了上去,使整个模型能够更加的方便易懂。
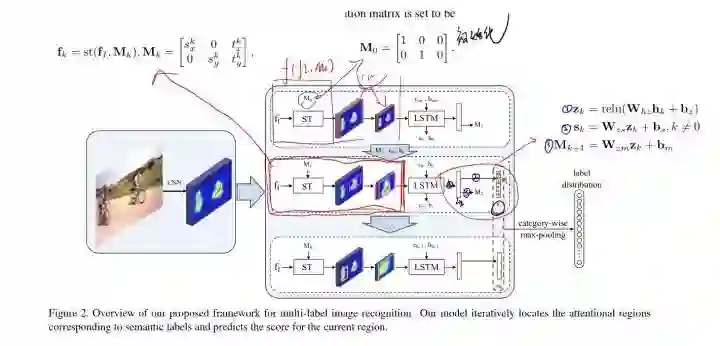
我们从图上也可以看出,最开始的图片经过cnn,这里的cnn使用的是VGG16,需要强调的是,这里输入是没有图片相关信息的。经过cnn 以后,我们能够得到卷积的feature map ,把它定义为fi,然后把得到的feature map送入到循环注意力记忆模块,(这个模块由图中可以看出是由一个空间转换层ST和LSTM组成的),然后,ST会定位一个attentional region ,来作为lstm的输入,而lstm也会针对这个区域预测具体的类别分数并且重新更新ST的参数,最后呢,从这些感兴趣区域得到的分数在经过融合,就会得到相应的类别分类。
3.1.空间转换层用于区域定位
作者在这里简单的介绍了下空间转换层的用法。空间转换层是一个基于样本的鉴别模块,能够在空间上把输入映射转换成输出映射(对应着输入映射的一个小块分区)。而且呢,ST模块能够很方便的在网络中进行训练,并且进行反向传播。在作者的模型中,ST模块被放入循环记忆模块用于attention region区域的定位。
一般的,空间转换层所输出的attention region 的特征被记住fk。这里需要一个空间转换矩阵 M(最开始的时候这个参数是我们给定的,而接下的时候是慢慢去学习的,这个在上面的图中也有具体的展示),现在我们有了fk的坐标,所以就能得到在fi中的坐标网格了。 然后呢,包含attention region的fk就能够通过双线性插值来产生了。如下图所示。
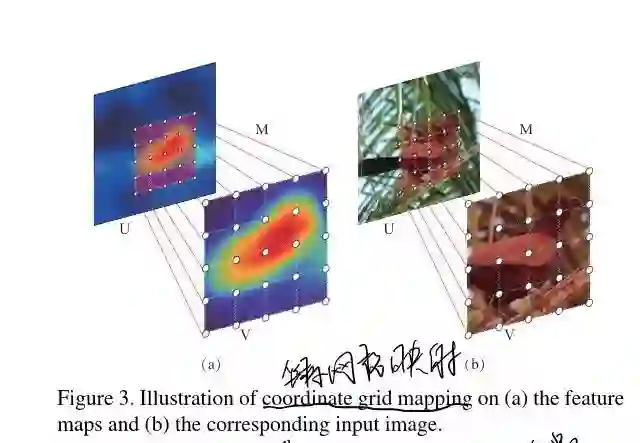
而为了定位region,我们常常来给转换矩阵加限制,使得只有能进行缩放,平移等操作。
这里解释下,这个空间转换矩阵通过改变参数能够实现一些变换上的操作,所以我们就可以通过学习这个参数来使得原图来发生一定的变化,最后得到我想要的attention region。
在论文《Spatial transformer networks》中,用公式证明了进行复制、平移、缩放操作,只需要一个映射矩阵M[2,3]。
一个有趣的例子:
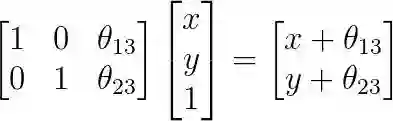
平移
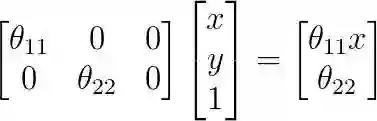
缩放
这个空间转换矩阵为:

这里我的理解就是我得到我的feature map 以后,我们学习M矩阵的参数,这样的话,我们就能从原来的大feature map 得到我感兴趣的feature map .然后就可以吧我感兴趣的feature Map送到LSTM 中,这样的话就可以节省很多的计算,但同时也提高了模型的稳定性。
3.2循环注意力记忆模块
这里就是把空间转换层和LSTM进行了连接。
我们这里很容易明白,我的fk 是关于fi和M 的一个函数:

这里作者还强调了一点,就是他们的空间转换操作是来自于feature map 以后进行的,这样的话就可以剩下很多的计算过程。我觉得这点在一两年前都已经想到了,就比如目标检测的那些,都是在经过cnn 以后的feature Map上来进行的rpn 的相关操作。
接下来就是LSTM的常规操作了,这里就不在具体的说明了。

当然:这里为什么使用LSTM,作者也给出了具体的原因。
从我自己的理解,就是因为语义标签之间是有相互联系的,不可能成为一个孤立的存在。并且,作者他们也解释了,他们希望LSTM找到所有的的有用信息并且进行有效的分类,而lstm 会记下之前的attention region 对于接下来的region的寻找也是能够提供多样性和互补性的。(毕竟LSTM会输出空间转换M的)
而M 的更新规则还是很简单的,就是LSTM的输出经过几个全连接就得到了M .并且也会得到相应分数。这里其实是这样的。我LSTM会输出K个分数向量,而每个向量里面包含了C个类别的分数(向量也就是C维的)。然后我们将这K 个向量融合,我们就得到了相应的最后的一个C维的向量,这就是最后的分类结果。
他们的模型基本就是这个样子。
4.Learning
4.1 Classification-loss
第一步他们讲了分类的loss ,我觉得这里还是很重要的。因为我之前没注意到是这么定义loss s的。他们采用了范数的方式。
下面详细解释下:
假设共有N个训练样本,而且每个样本中包含C个标签,当然并不是每张图都有这C 个标签,而是使用one hot 的方式来表示C个类别中,在这一张图片中都有那些在图片中存在的。
而他们定义losss的方式,是采用1-范数的形式。比如 ground truth ,是
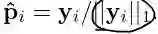
,这里的Yi就是label vector。用几乎同样的定义,我们也可以定义我们的预测向量为这种形式:
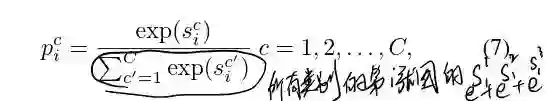
最后就可以定义定义我们的loss是:
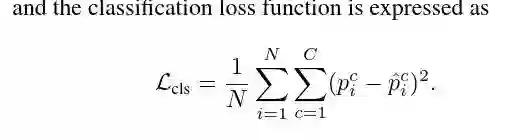
4.2 attention region constraint
这里是关于attention region的限制部分,因为作者需要这里的准确度要高,而正常来说,ST模块并不能实现作者的一些要求,而且会产生一些问题,比如产生大量的计算,并且忽视了细小的物体,并且得到的区域只能是垂直或者水平的。
然后作者针对这些问题对M矩阵加了三条限制,分别是anchor,scale,positive constraint.使得region的区域选择尽可能稳定。
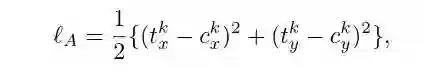
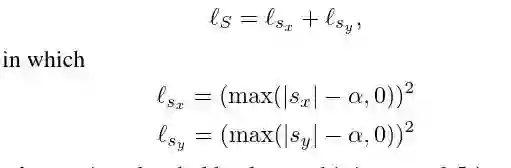
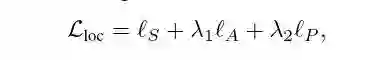
这样的话,我们整体的loss 就是一个端到端的loss,能够进行反向传播。
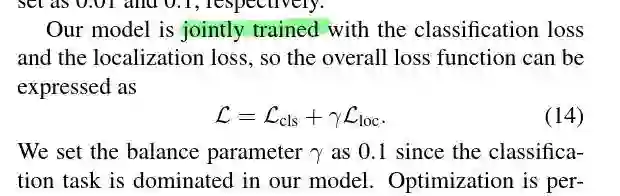
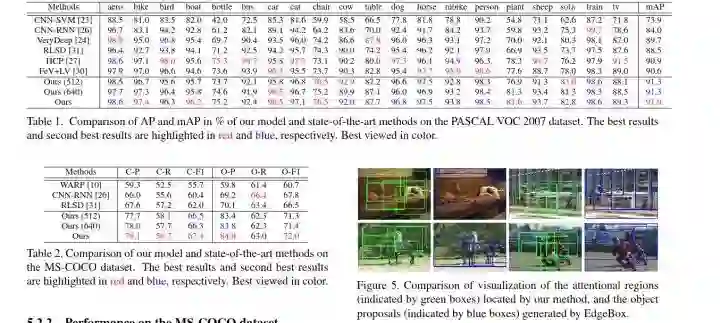
5.实验
后面就是作者做的一些对比实验。很详细的实验,很值得学习/
最后是一点对自己的拷问:
看完了一篇论文,总会有一些自己的思考。
解决了什么问题?
解决了多标签分类的问题吧
提出了怎样的方法?
选取注意力区域,然后使用LSTM进行记忆相关注意力区域,得到的隐含层输出融合得到分类结果
为什么会提出这个方法?
最开始的时候人们的attention region 很多时候都是由假设框所得到的,而现在可以采用空间转换的方法,并且标签之间都是存在相互关联性的。自然是使用LSTM会更好。
设计了怎样的模型?
img-cnn-ST-LSTM
这篇文章的关键点是什么?
我觉得是对注意力区域的改进吧,并且使用了LSTM来记忆之前的标签信息
贡献是什么?
对于我来说,这种思路可以用到我现在的研究方向上,是一个很好的对比试验方法。
这个模型为什么能work?
端到端的模型
和image——caption的注意力区域有什么区别。
我觉得对于image_cption的注意力模块来说 (XU.2015/show attend and tell ):图像的文字描述经过LSTM以后得到的隐含层和feature map 进行结合,得到每个feature map的权重,在和feature map 加权就得到了最重要的一张特征。在送到LSTM中。
而本文是通过对一个矩阵参数的学习,来使得在原图上找到相关的attention region 。再把这个区域送到LSTM.因为我没看过他们的代码。我感觉好像一样。因为我觉得img_caption的attention模块也是关于一个(feature map ,LSTM的输出H)的函数。
如果有哪里看到不够对的,还烦请各路大神指出,我一定虚心学习。
来源:知乎专栏 Lab NIP
作者: 知乎用户:makaay,
联系方式:知乎私信 或者 makaay@sjtu.edu.cn
专知已获得作者授权。
https://zhuanlan.zhihu.com/p/35799767
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知




