标签间相关性在多标签分类问题中的应用
一
多标签问题的简单解决思路
利用神经网络,我们可以很轻松处理一个多标签问题。如标题图所示,为前馈神经网络添加适当数量的隐含层,同时在输出层使用某个阈值判断标签分类结果即为一种基础的解决思路。
上述是一种简单的从多分类问题拓展到多标签问题的解决思路,这样的思路中,我们可以用输出结果[0.1, 0.9, 0.8, 0.2, 0.85]表示该输入属于标签2、3和5(假设阈值为0.5,标签从1开始计数)。
二
存在的问题
上述思路存在的问题之一是没有考虑标签间的相关性,而这种相关性可能能够提高特定问题上模型的效果。例如,在对文章进行分类的时候,我们经常能够看到标签神经网络和深度学习一起出现,而神经网络和区块链一起出现的几率就会降低一些,我们基本可以从中得知,标签为"神经网络"的文章具有较大的可能也可以具有"深度学习"标签,这便是标签间相关性对多标签问题模型的促进效果。
三
解决思路
如今我们希望在多标签分类问题中考虑标签间的相关性,因此我阅读了较新的相关文献,对这些文献进行了总结。
3.1 COLING2018《SGM: Sequence Generation Model for Multi-label Classification》
来源链接:https://arxiv.org/abs/1806.04822
这篇论文是COLING2018 Best papers(Best error analysis & Best evaluation),其误差分析和评估方面做的比较好,论文主要的贡献是:
1. 把多标签分类问题当做序列生成问题,进而考虑标签间相关性
2. 在序列生成模型的decode部分进行了改造,不但考虑了标签间相关性,还自动获取了输入文本的关键信息(Attention机制)
3. 本论文提出的方法效果极好,指标比baseline提升很多。在关系表示上也具有非常好的效果。
模型如下图所示:
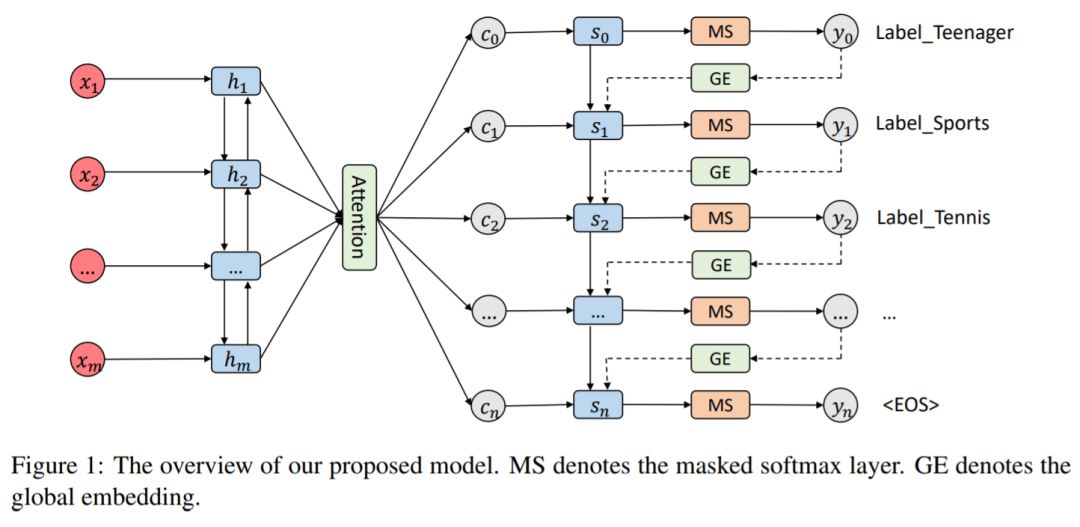
我试着将自己代入作者,梳理了作者的思考思路:
Seq2Seq模型的输入和输出均为序列,且能够学习到输入和输出序列的相关性。对于文本的多标签分类问题,这似乎是个很合适的选择。
然而,直接套用会存在一些能够想到的问题,因此作者一步步来解决这些问题:
1、多标签分类的输出显然是不能重复的,于是作者在最终
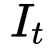
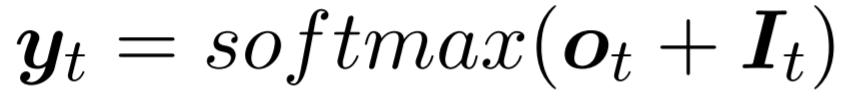

2、Seq2Seq中某时刻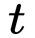
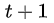
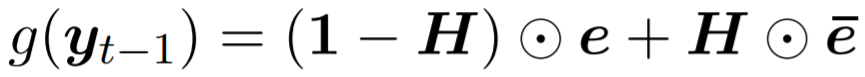
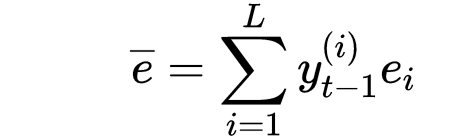
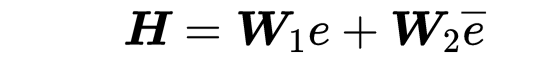
其中



3、考虑到出现此处更多的标签在标签相关性训练中具有更强的作用,在训练时把标签按照其出现次数进行从高到低排序作为输出序列。出现次数更多的标签可以出现LSTM的前面,进而更好地指导整个标签的输出。
4、 此外,作者在使用Seq2Seq时,在Encode部分加入双向LSTM,在Decode部分加入了目前很常用的Attention机制。这些已经是大家耳熟能详的组件了,目前在Seq2Seq模型中也很常用。
3.2《Deep Learning with a Rethinking Structure for Multi-label Classification》
来源链接:https://arxiv.org/abs/1802.01697
有了上篇文章的铺垫,这篇文章思路显得容易理解很多。之前我们提到,直接将RNN用于标签的序列生成存在上述提到的一些问题。作者这里使用了名为rethinking的decode组件:
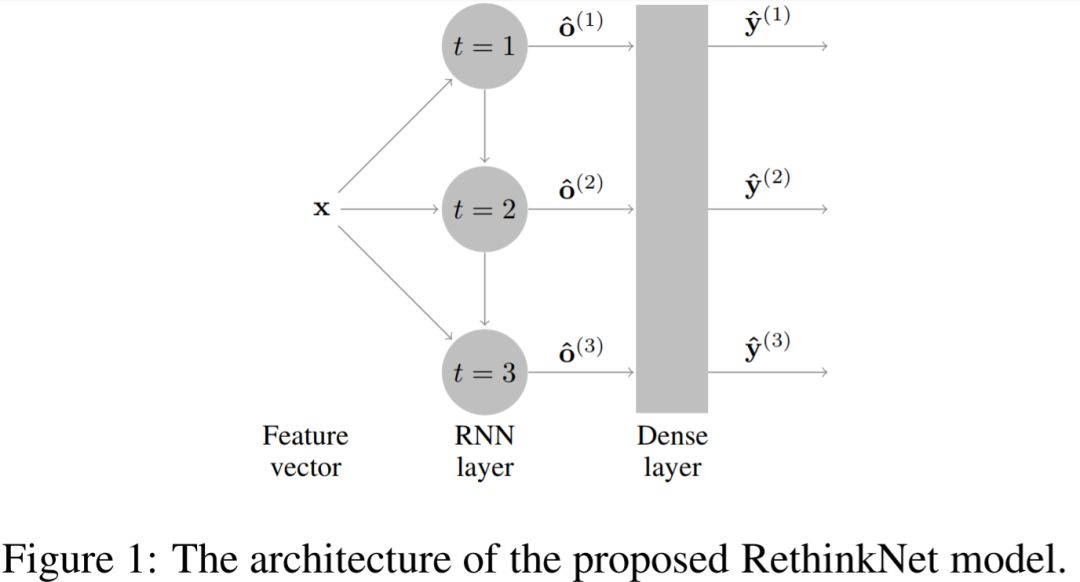
这里主要分为两层:RNN + Dense。
在RNN层中,使用一种名为SRN的简化版RNN:
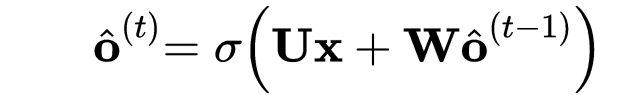
该层主要学习了标签间的相关性,
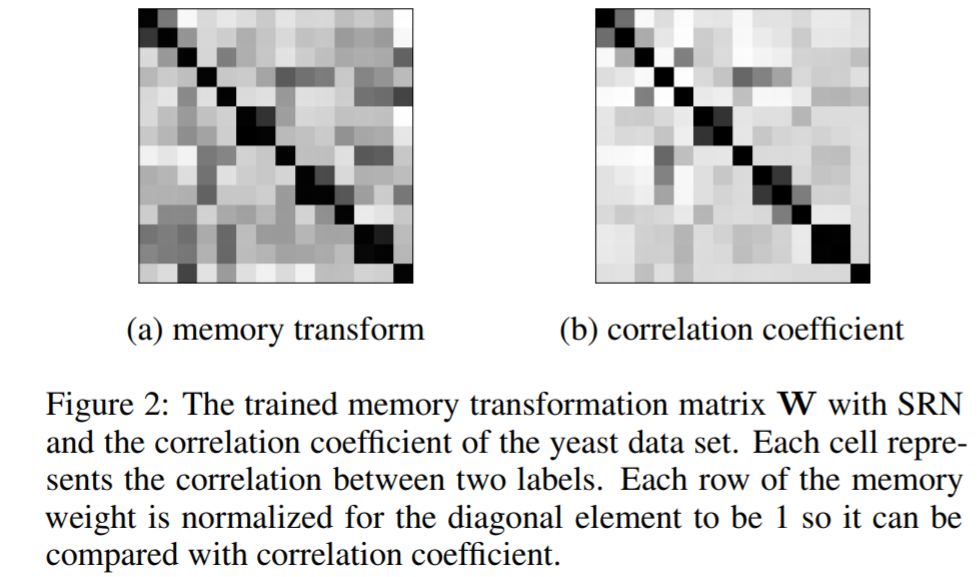
经过了Dense层,

总的来说,这篇论文主要提出了上述名为rethinking的组件,让RNN应用在了多标签分类问题上。
-----END-----
@Octocat
版权声明
本文版权归《Octocat》,转载请自行联系。


点击文末阅读原文 或 扫描上方二维码报名
历史文章推荐
AI综述专栏 | 多模态机器学习综述
深度学习中不得不学的Graph Embedding方法
旷视研究院新出8000点人脸关键点,堪比电影级表情捕捉
何恺明团队最新研究:3D目标检测新框架VoteNet,直接处理点云数据,刷新最高精度
打开阿兹海默之门:华裔张复伦利用RNN成功解码脑电波,合成语音 | Nature
图嵌入(Graph embedding)综述
半天2k赞火爆推特!李飞飞高徒发布33条神经网络训练秘技
再也不用担心我的公式写不出来了:一款公式输入神器实测
【深度学习】一文看尽深度学习各领域最新突破
2019 年 12 个深度学习最佳书籍清单!值得收藏
你正在看吗?👇


