大会 | AAAI论文:基于强化学习循环查找受关注区域的多标签图像识别

AI 科技评论按:近日,中山大学-商汤科技联合发表 AAAI2018 论文 「Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition」提出了一个新的框架 RARL,即基于强化学习循环发现关注区域,用于解决多标签图像的识别任务。相比于目前存在的其他方法,该方法在识别精度和效率上都取得极大的提升。本文将详细介绍论文中提出的方法。

多标签图像识别
多标签图像识别是计算机视觉领域一个非常重要且比较难的任务。近年来,有些工作通过结合物体候选框提取的方法,将深度学习应用于多标签图片识别任务,并取得一定的进展。这类方法首先利用现有的物体定位方法(如 Selected search 或者 Edge boxes等)提取一定数量的图片局部区域,然后利用深度网络提取每个局部区域的特征,最后聚合所有的特征以得到最后的预测结果。然而,这类方法引入额外的计算开销,另外,不同局部区域之间的关联也被简化甚至忽略了。不同于这类方法,本文提出一个新的 Recurrent Attentional Reinforcement Learning(RARL)框架,该框架引入视觉注意机制,自动地挖掘语义关联的局部区域,并聚合这些区域的特征取得最后的识别结果。相比于目前多标签图片识别的方法,本文提出的方法具有以下两个优点:
1)本文引入视觉注意机制自动的搜索语义关联的局部区域,不需要依赖于物体候选框提取技术,在多标签识别精度和效率上都有极大的提升。
2)本文利用记忆网络直接对不同局部区域的关联进行建模,这可以有效的利用标签共存的情况,进一步提升多标签图像的识别性能。
RARL框架
RARL 的框架如下图所示。首先,RARL 框架利用一个全卷积网络(如 VGG16 的卷积部分)提取图片特征,并将特征输入一个 LSTM 网络,迭代的搜索语义关联的局部区域,并预测该区域的标签分布。具体而言,在每一次迭代 t,RARL 框架接收到上一次迭代计算得到的位置 lt,计算以该位置为中心的 k 个不同尺度,不同长宽比区域(参考 Faster RCNN anchor 机制),并提取这些区域的特征。LSTM 根据前一次迭代的隐层状态特征 ht-1 以及当前迭代提取的区域特征,预测这些区域的标签分布以及搜索用于下一次迭代的最优位置。最后,RARL 聚合所有区域的预测的标签分布,得到最后的分类结果。
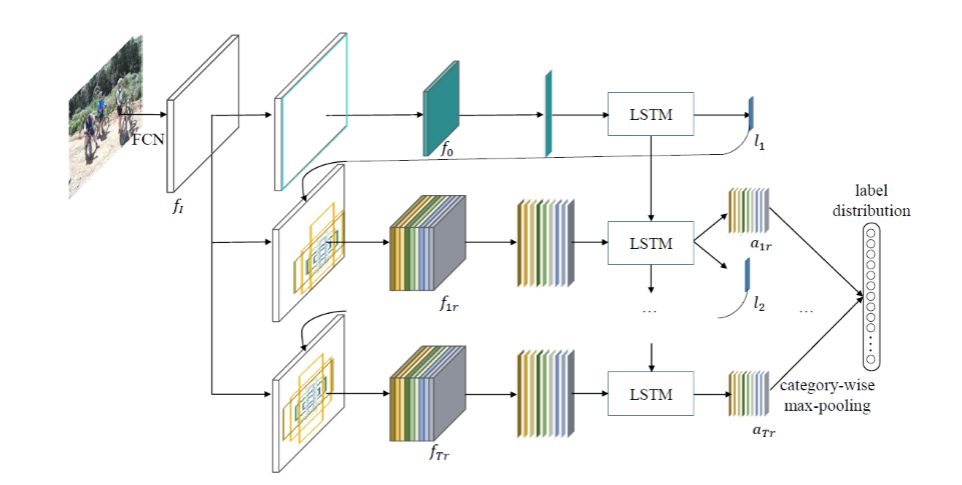
Figure 1:Overview of our proposed framework for multi-label image recognition. The inputimage is first fed to the VGG16 ConvNet and mapped to the feature maps fI. At each iteration t, k regions are yielded at the center location lt estimated from the previous iteration and corresponding fixed-size features are also extracted. An LSTM unit takes these features as well as the hidden state of the previous iteration as input to predict the scores for each region and searches the location for the next iteration. All the predicted scores are fused using the category-wise max-pooling to obtain the final label distribution. The framework is end-to-end trained using merely image-level labels using reinforcement learning techniques.
在训练的过程中,我们把局部区域的迭代搜索形式化为一个序列决策的问题,并引入强化学习技术训练模型。通过这种方法,我们可以仅利用图片类别标签端到端的训练 RARL 模型,不依赖于物体的类别信息。具体的,其状态,动作和奖励机制如下:
状态:当前迭代定位到区域的信息以及 LSTM 上一个时刻的隐层信息。
动作:搜索下一个局部区域的位置以及对当前受关注区域进行分类。
奖励:当没有达到最大迭代次数时候,奖励为 0,当达到最大迭代次数时,奖励是当前分别准确情况,即样本物体类别召回率,即若当前样本存 N 种物体,而预测结果找到了 n(0≤n≤N)种,则该样本的奖励为 n/N。
实验结果
本文在 Pascal Voc 2017 和 Microsoft COCO 两个比较大的数据集上验证了 RARL 框架的有效性。
Pascal Voc 2017 是多标签识别任务最常用的数据集,在该数据集上,我们的方法在 mAP 评测指标上比现有最优的方法(表 1 的 HCP)提高了 1.1%。

Table 1: Comparison results of AP and mAP in % of our model and the previous state of the art methods on the VOC07 dataset. The best results and second best results are highlighted in red and blue,respectively. Best viewed in color.
Microsoft COCO 是一个更大更难的数据集,目前也被广泛用于多标签识别任务的评测,在该上数据上,我们的方法在 C-F1 和 O-F1 评价指标上比目前最好的方法(表 3 的 RLSD 和 CNN-RNN)提升了 4.4%和 3.3%。
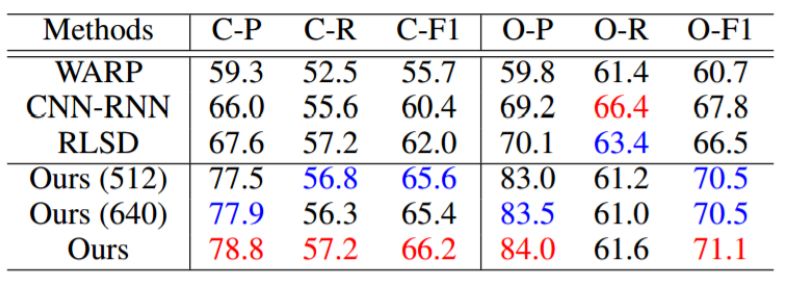
Table 2: Comparison results of our model and the previous state of the art methods on the MS-COCO dataset. The best and second best results are highlighted in red and blue, respectively. Best viewed in color.
在运行效率上,我们的方法在 NVIDIA GeForce GTX TITAN-X GPU 进行评测。我们的方法预测一张图片的结果需要约 350ms。现有的基于物体候选框的方法,比如 HCP,在类似的 GPU 环境下,一张图片需要大概 10s,比我们的方法满了近 30 倍。
相关文献
[1] Tianshui Chen, Zhouxia Wang, Guanbin Li, and Liang Lin, Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition, in AAAI, 2018.
[2] Yunchao Wei, Wei Xia, Min Lin, Junshi Huang, Bingbing Ni, Jian Dong, and Yao Zhao, Hcp:A flexible cnn framework for multi-label image classification, TPAMI, 2016.
[3] HaoYang, Joey Tianyi Zhou, Yu Zhang, Bin-Bin Gao, Jianxin Wu, and Jianfei Cai, Exploit bounding box annotations for multi-label object recognition, in CVPR, 2016.
————— AI 科技评论招人了 —————

————— 给爱学习的你的福利 —————
三大模块,五大应用,手把手快速入门NLP
海外博士讲师,丰富项目经验
算法+实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
点击阅读原文或扫码了解详情
▼▼▼

————————————————————





