
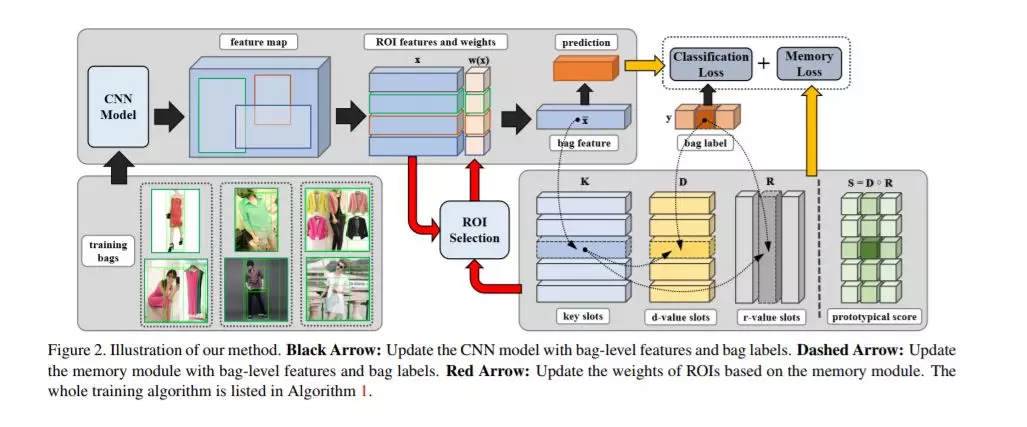
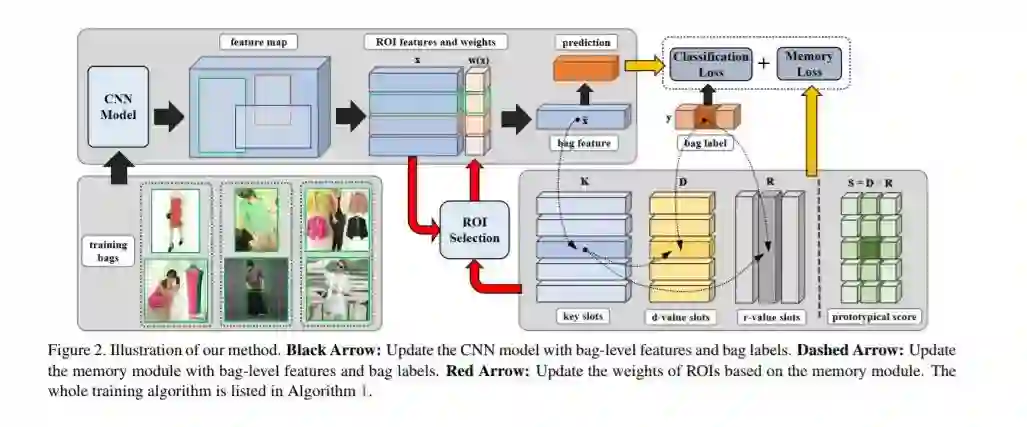
在这篇论文中,研究者利用网络数据研究图像分类任务 (image classification)。他们发现网络图片 (web image) 通常包含两种噪声,即标签噪声 (label noise) 和背景噪声 (background noise)。前者是因为当使用类别名 (category name) 作为关键字来爬取网络图像时,在搜索结果中可能会出现不属于该类别的图片。后者则是因为网络图片的内容与来源非常多样,导致抓取的图片往往包含比标准的图像分类数据集更多的无关背景信息。在下图中的两张图片均用关键字「狗」抓取。左边图片的内容是狗粮而不是狗,属于标签噪声;右边的图像中,草原占据了整个图像的大部分,同时小孩子也占据了比狗更为显著的位置,属于背景噪声。这两种噪声给利用网络数据学习图像分类器带来了很多额外的困难,而现有的方法要么非常依赖于额外的监督信息,要么无法应对背景噪声。论文中提出了一种不需要额外监督信息的方法来同时处理这两种类型的噪声,并在四个基准数据集上的实验证明了方法的有效性。
成为VIP会员查看完整内容
相关内容
专知会员服务
102+阅读 · 2019年11月24日
Arxiv
4+阅读 · 2018年10月15日

相关VIP内容
专知会员服务
102+阅读 · 2019年11月24日
相关资讯