让一位乒乓球爱好者和机器人对打,按照机器人的发展趋势来看,谁输谁赢还真说不准。
机器人拥有灵巧的可操作性、腿部运动灵活、抓握能力出色…… 已被广泛应用于各种挑战任务。但在与人类互动紧密的任务中,机器人的表现又如何呢?就拿乒乓球来说,这需要双方高度配合,并且球的运动非常快速,这对算法提出了重大挑战。
在乒乓球比赛中,首要的就是速度和精度,这对学习算法提出了很高的要求。同时,这项运动具有高度结构化(具有固定的、可预测的环境)和多智能体协作(机器人可以与人类或其他机器人一起对打)两大特点,使其成为研究人机交互和强化学习问题的理想实验平台。
来自谷歌的机器人研究团队已经建立了这样一个平台来研究机器人在多人、动态和交互环境中学习所面临的问题。谷歌为此还专门写了一篇博客,来介绍他们一直在研究的两个项目 Iterative-Sim2Real(i-S2R) 和 GoalsEye。i-S2R 让机器人能够与人类玩家进行超过 300 次的对打,而 GoalsEye 则使机器人能够从业余爱好者那里学习到一些有用的策略(目标条件策略)。
i-S2R 策略让机器人和人类对打,虽然机器人的握拍姿势看起来不太专业,但也不会漏掉一个球:
你来我往,还挺像那么回事,妥妥打出了高质量球的感觉。
而 GoalsEye 策略则能将球返回到桌面指定位置,就和指哪打哪差不多:
在这个项目中,机器人旨在学会与人类合作,即尽可能长时间地与人类进行对打。由于直接针对人类玩家进行训练既乏味又耗时,因此谷歌采用了基于模拟的方法。然而,这又面临一个新的问题,基于模拟的方法很难准确地模拟人类行为、闭环交互任务等。
在 i-S2R 中,谷歌提出了一种在人机交互任务中可以学习人类行为的模型,并在机器人乒乓球平台上对其进行实例化。谷歌已经建立了一个系统,该系统可以与业余人类玩家一起实现高达 340 次击球对打(如下所示)。
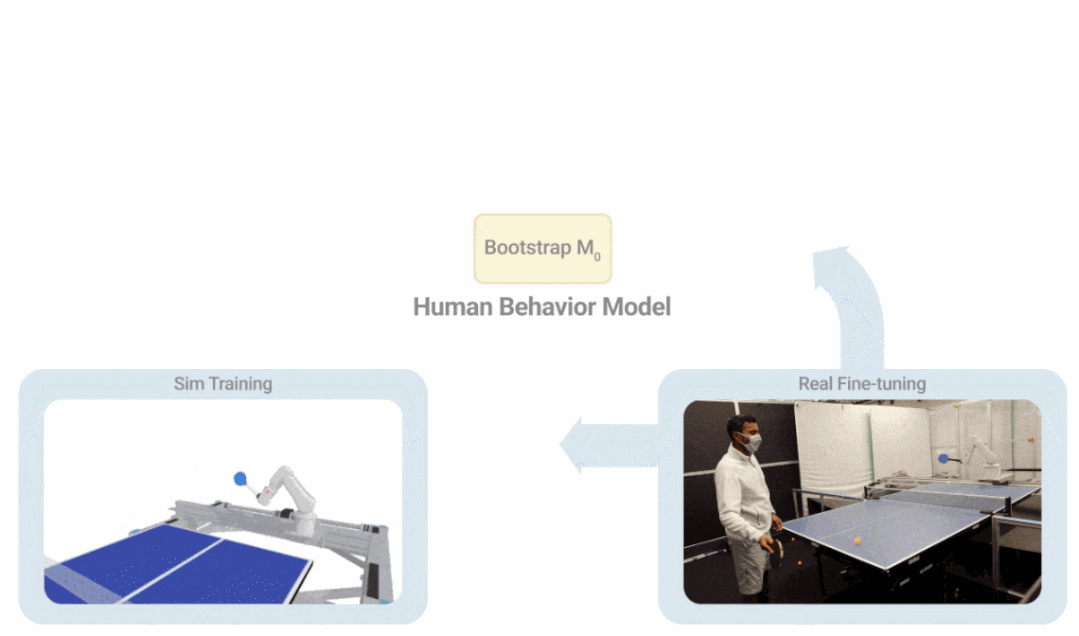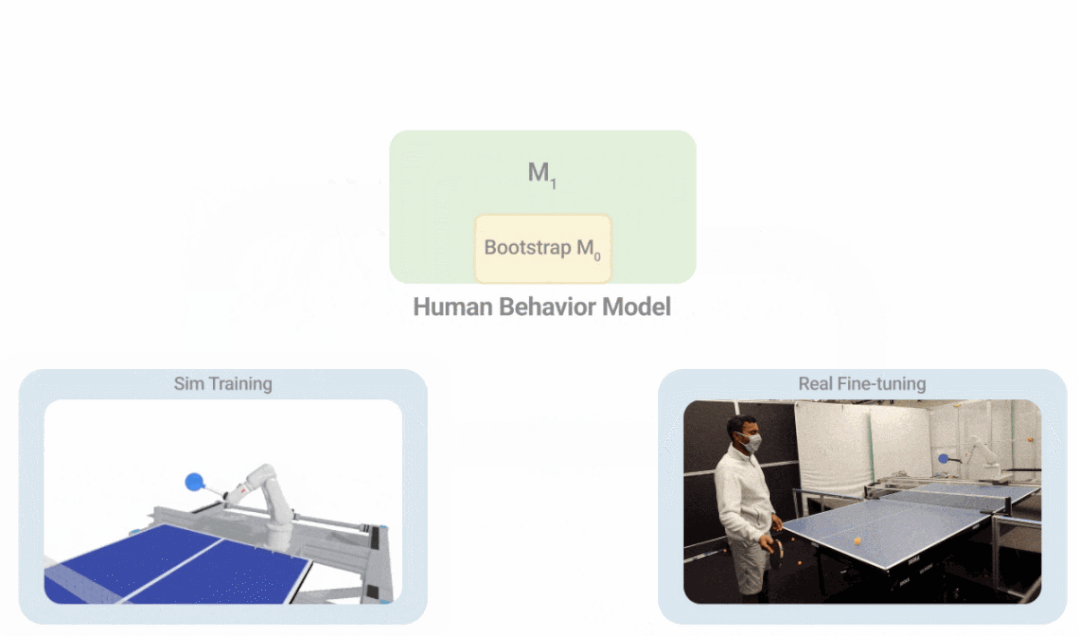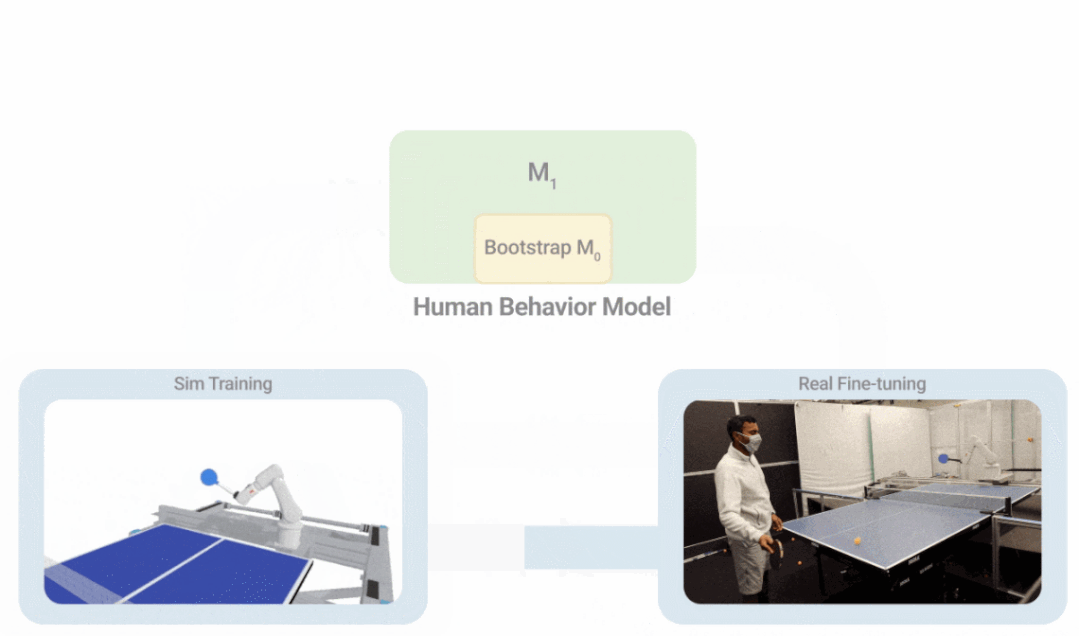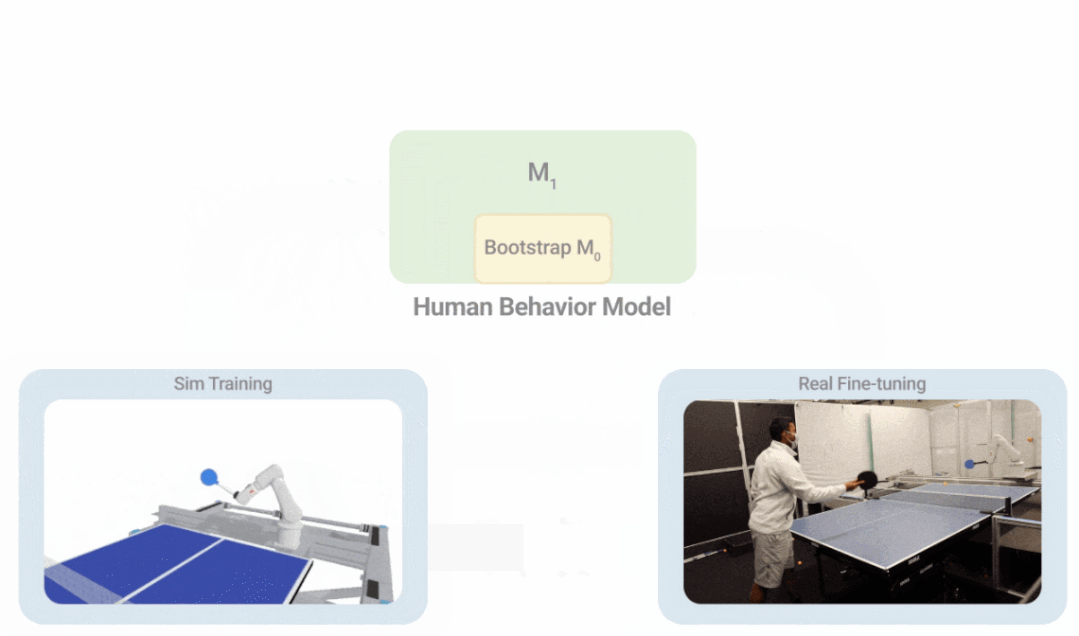
让机器人准确的学习人类行为还面临以下问题:如果一开始就没有足够好的机器人策略,就无法收集关于人类如何与机器人交互的高质量数据。但是如果没有人类行为模型,从一开始就无法获得机器人策略,这个问题有点绕,就像先有鸡还是先有蛋的问题。一种方法是直接在现实世界中训练机器人策略,但这通常很慢,成本高昂,并且会带来与安全相关的挑战,当人参与其中时,这些挑战会进一步加剧。
如下图所示,i-S2R 使用一个简单的人类行为模型作为近似起点,并在模拟训练和现实世界部署之间交替进行。每次迭代中,人类行为模型和策略都会被调整。
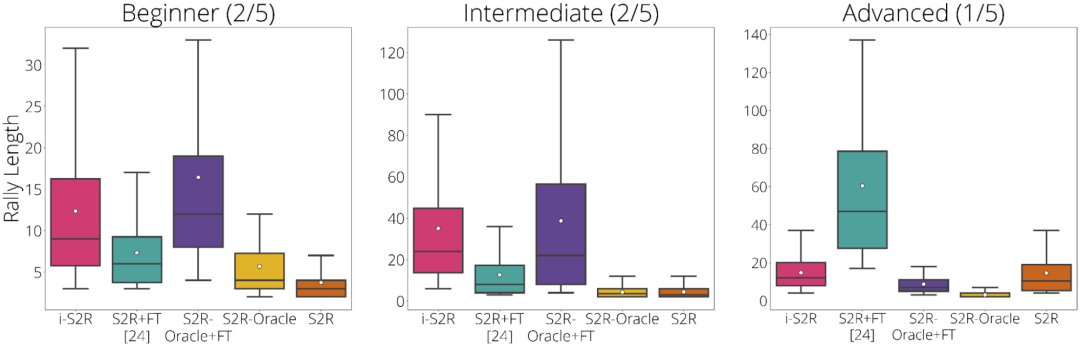
谷歌根据玩家类型对实验结果进行了细分:初学者(占 40% 的玩家)、中级(占 40% 的玩家)和高级(占 20% 的玩家)。由实验结果可得,对于初学者和中级玩家(占 80% 的玩家),i-S2R 的表现都明显优于 S2R+FT(sim-to-real plus fine-tuning)。
在 GoalsEye 中,谷歌还展示了一种方法,该方法结合了行为克隆技术(behavior cloning techniques)来学习精确的目标定位策略。
这里谷歌重点关注乒乓球的精度,他们希望机器人可以将小球精确返回到球台上的任意指定位置,就如下图所展示的指哪打哪。为实现如下效果,他们还采用了 LFP(Learning from Play)、GCSL(Goal-Conditioned Supervised Learning)。
GoalsEye 策略瞄准直径为 20cm 的圆圈(左)。人类玩家可以瞄准同样的目标(右)。
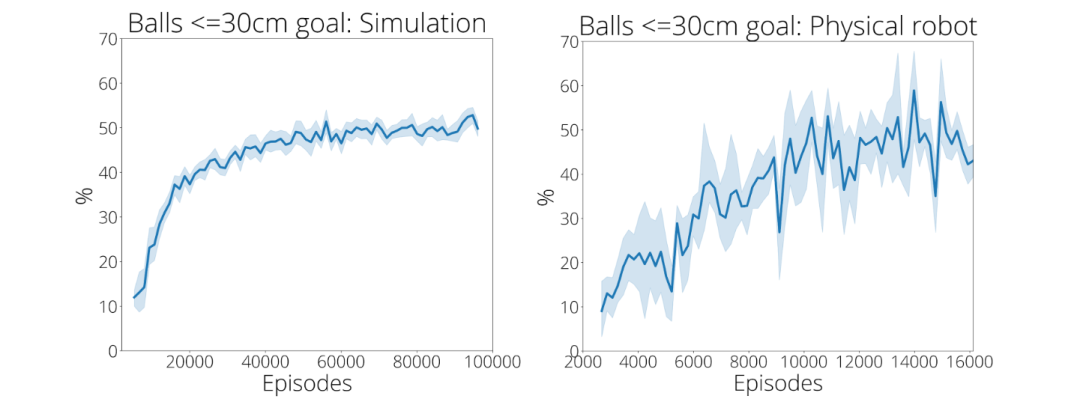
在最初的 2480 次演示中,谷歌的训练策略仅在 9% 的时间内准确地击中半径为 30 厘米的圆形目标。在经过了大约 13500 次演示后,小球达到目标的准确率上升到 43%(右下图)。
-
Iterative-Sim2Real 主页:https://sites.google.com/view/is2r
-
GoalsEye 主页:https://sites.google.com/view/goals-eye
原文链接:https://ai.googleblog.com/
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com