AI能「踢足球」了,但AI机器人还不能
新智元报道
新智元报道
【新智元导读】DeepMind的研究团队,通过计算机模拟数十年足球比赛的情况,训练AI学会了熟练地控制数字人形足球运动员,但还仅限于足球网络游戏,不能用于机器人硬件上。
今年11月,世界杯又要开赛了。
到时候,不管踢不踢,踢得好还是踢得不好,又会有很多人开始聊足球了。
没办法,谁叫足球是世界第一大运动呢。
不过相比于世界杯,科学家对年度机器人杯3D模拟联盟更感兴趣。
不久前,来自英国人工智能公司DeepMind的研究团队,利用一种加速版运动课程,通过计算机模拟数十年足球比赛的情况,训练AI学会了熟练地控制数字人形足球运动员。

相关研究发表在《科学·机器人》杂志上。
论文地址:https://www.science.org/doi/10.1126/scirobotics.abo0235
显然,这已经不是第一次「AI足球运动员」进入大众视野了。
AI足球运动员的进化简史
早在2016年,AlphaGo在围棋上战胜李世石后没多久,Deepmind就开始琢磨让AI踢足球了。
当年6月,DeepMind的研究人员让AI控制一只蚂蚁形状的物体去追逐小球,然后带球直至将其送进球门得分。
根据DeepMind小组负责人David Silver的说法,借助当时谷歌最新开发出异步Actor-Critic算法,即A3C,AI不仅完成了这个项目,而且在整个过程中不需要向他灌输有关力学的知识。
这项实验,让「AI踢足球」迎来了开门红。
到了2019年,DeepMind已经训练了许多「Player」,它们分别由不同训练计划制作而成的,DeepMind从中选择10个双人足球团队。
这10个团队每个都有250亿帧的学习经验,DeepMind收集了它们之间的100万场比赛。
然后DeepMind设置环境,让多个AI一起踢足球赛,并且提前设置了规则,奖励整个「足球队」而不是去鼓励某个「AI球员」的个人成绩,以促成整个球队的进步。
DeepMind用这种方式证明了,AI是可以互相合作的。
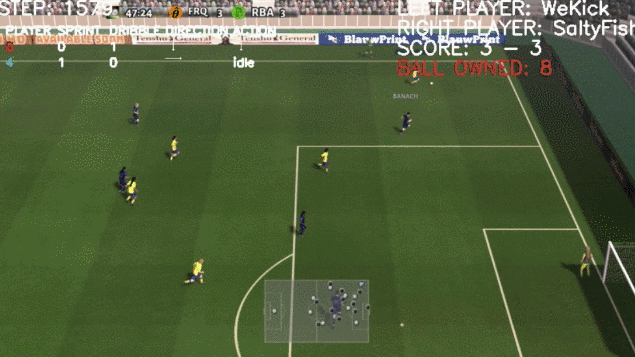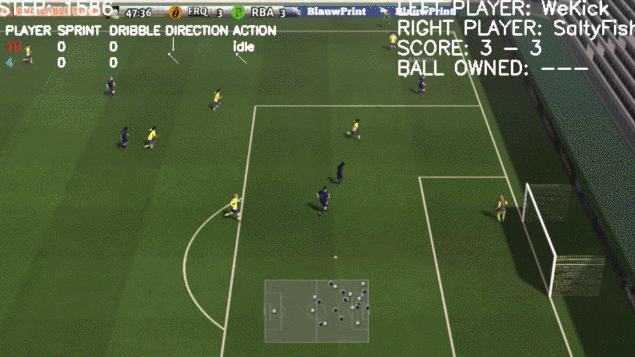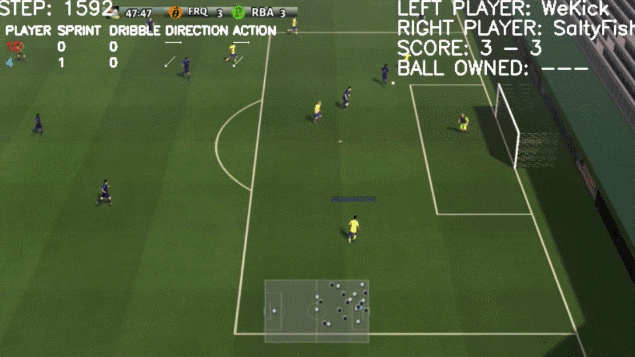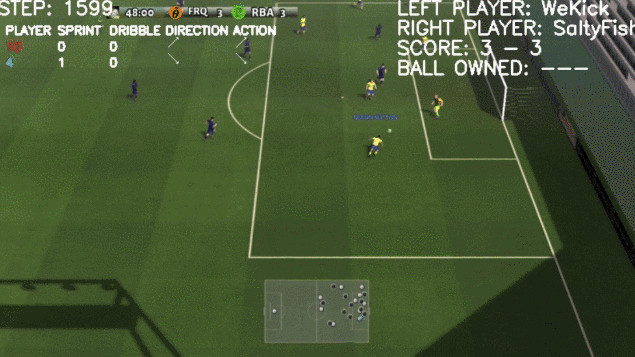
看起来一切顺利,然而到了2020年,DeepMind的AI球员出问题了。
根据脑极体提供的资料,在一场比赛中,一方的足球机器人排成一排向球门发起射击,但机器人守门员却并没有准备防守,而是一屁股倒在地上开始胡乱摆动起了双腿。
你以为这就完了?too naive!
接着,担任前锋的机器人球员跳了一段十分令人困惑的舞蹈,跺跺脚,挥挥手,啪叽一下摔倒在地上。
这一幕让观众极为震惊:见过放水的,没见过这么放水的!
为何会这样呢?
这还要从背后的原理说起。
「AI踢足球」的开始,研究人员就采用了强化学习这条道路。
此前,AlphaGo的学习是基于监督学习,即通过标记好的数据集来进行训练的。
但这种方式对数据的「洁净」程度要求高:一旦数据有问题,AI就会犯错。
与之相比,强化学习是模仿人类的学习模式,AI以「试错」的方式进行学习,对了受奖,错了受罚,从而建立正确的联系。
看起来比传统的监督学习智能了不少,但还是有漏洞。
比如,AI会对奖惩措施产生错误的理解,因而生成奇怪的策略。
OpenAI曾经设计了一个赛艇游戏,AI原本的任务是完成比赛。
研究者设置了两种奖励,一是完成比赛,二是收集环境中的得分。结果就是智能体找到了一片区域,在那里不停地转圈「刷分」,最后自然没能完成比赛,但它的得分反而更高。
这次,AI踢出了什么新花样
虽然AI踢足球出现过翻车现场,但研究人员没有放弃。
文章开头提到,DeepMind的研究团队在训练「AI足球运动员」上有了新突破。
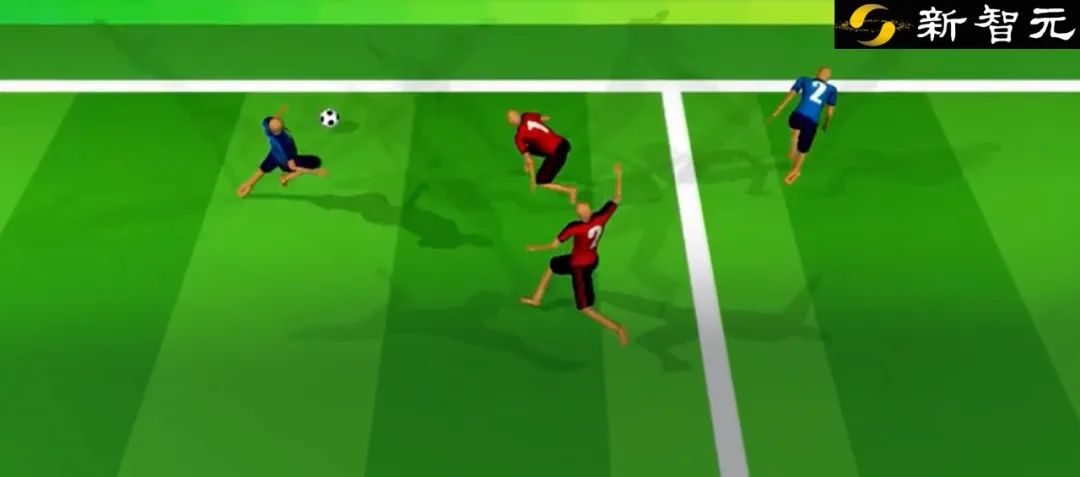
据论文描述,尽管DeepMind团队在此次研究中简化了游戏规则,并将两队球员人数限定在了2-3人,但「AI足球运动员」可以完成带球突破、身体对抗、精准射门等动作。
那研究人员是怎么训练「AI足球运动员」的呢?
简单来说,是将监督学习与强化学习结合起来。
第一步,AI需要观看人类踢足球的视频剪辑,学会自然行走,因为AI开始并不知道要在足球场上做什么。

第二步,AI在强化学习的算法下,练习运球和射门。
这两步,AI大约能在24小时内完成。
第三步,就用用比赛的形式训练,AI机器人进行2对2比赛,这一步需要耗时2到3周,主要是让AI学会团队协作,以及预测传球等更高难度的运动控制。

这次「AI 足球运动员」的表现还是让研究团队觉得比较满意。
DeepMind团队认为,这一研究推动了人工系统向人类水平运动智能向前迈进。
不过,DeepMind团队还是比较清醒,他们知道,这次突破还是有局限性的。
比如,比赛是2v2,而不是现实足球比赛常用的11v11,还不能说明AI可以参加更复杂的足球比赛。
此外,即便是简单的2v2比赛,也没法直接用在机器人硬件上。
换句话说,科学家们还不能研制出可以踢足球的机器人。



