DeepMind祖师带出了AI徒弟,用「传授」而非「训练」教AI寻宝
![]()
新智元报道

新智元报道
编辑:袁榭 好困
【新智元导读】用海量样本、参数「训练」AI,成效再显著,在DeepMind研究者的眼中,也远不如人类之间「传授」经验的方式的速度与能效。

日后你惹出祸来,不把为师说出来就行

给AI「传授」文化
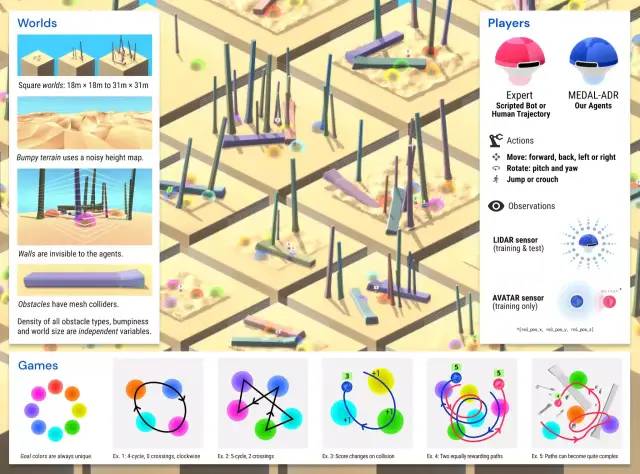


方法实现和结果

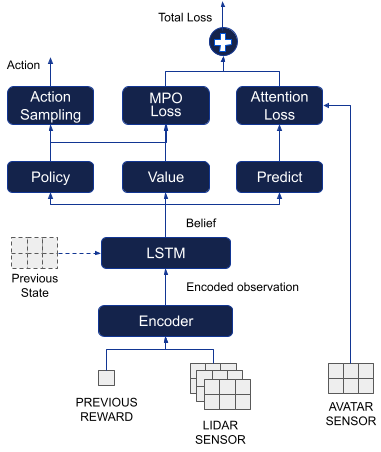
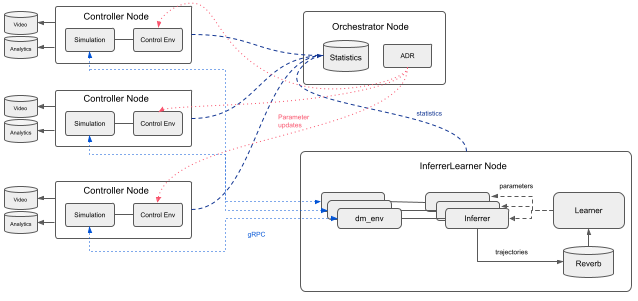
训练架构





泛化:世界空间
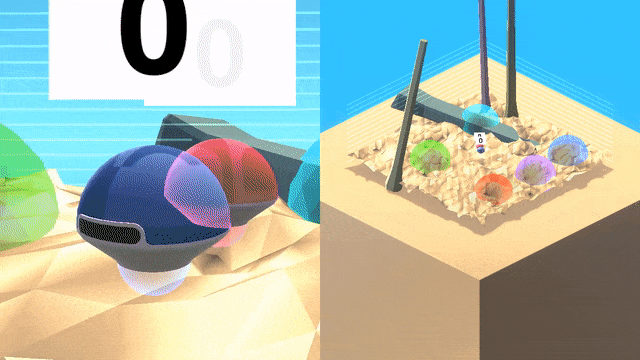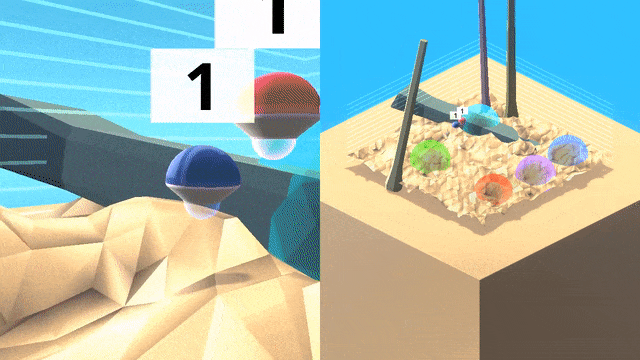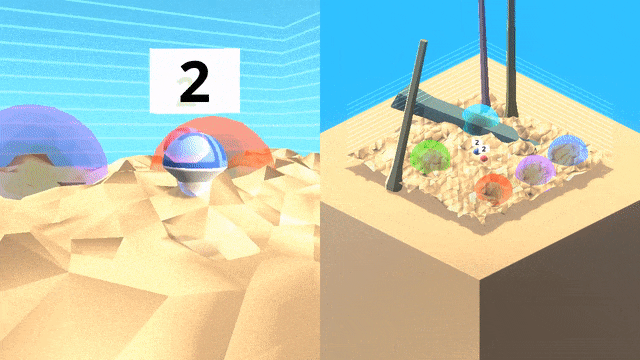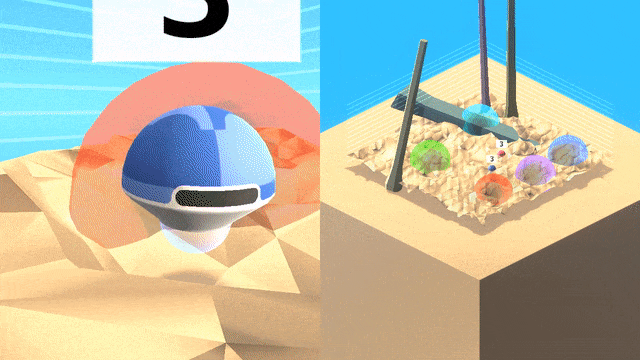
泛化:游戏空间

泛化:专家空间


开发团队
开发团队

参考资料:

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月15日
Arxiv
23+阅读 · 2019年11月5日
Arxiv
10+阅读 · 2018年5月10日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日
Arxiv
23+阅读 · 2019年11月5日
Arxiv
10+阅读 · 2018年5月10日