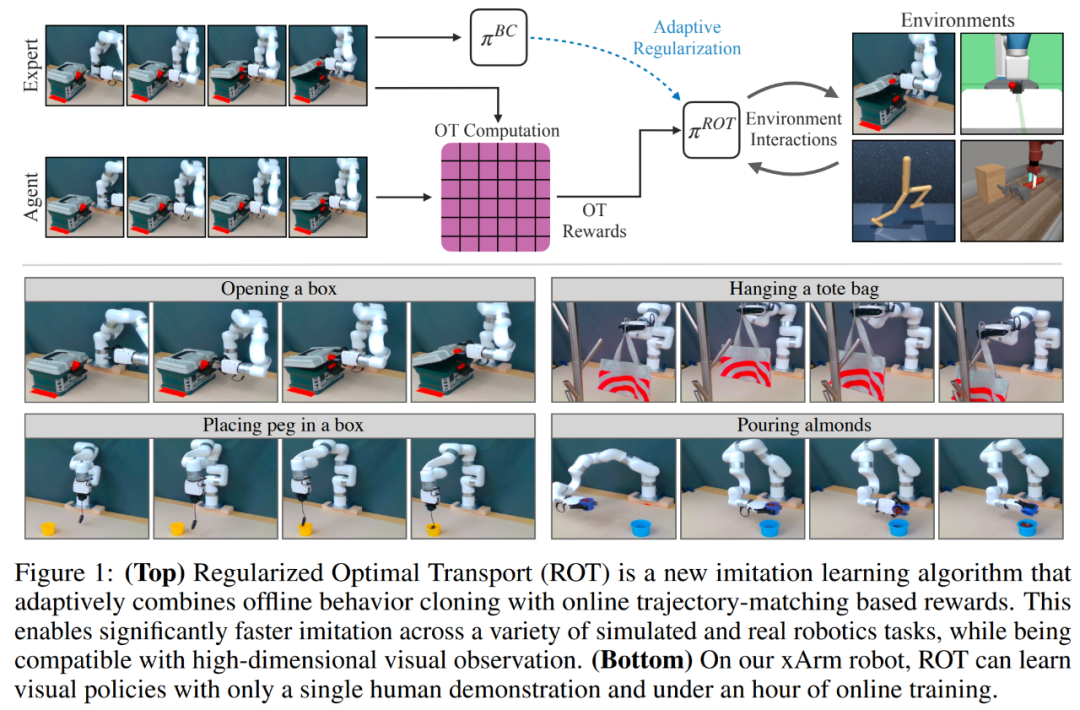
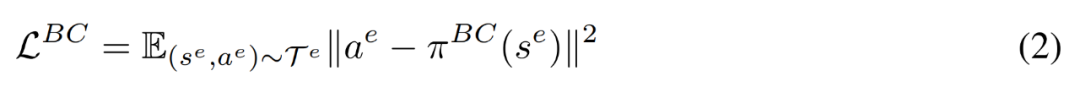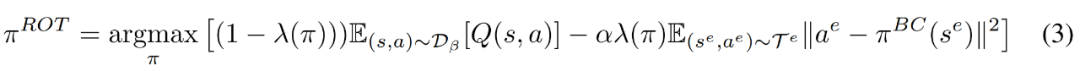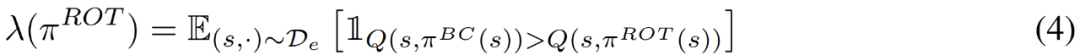本文提出的用于模仿学习的 ROT 算法,无需任何预训练,在 14 项任务中的平均成功率为 90.1%。
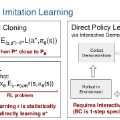
模仿学习(Imitation Learning, IL)具有悠久历史,可以分为两种广泛的范式,分别为
行为克隆(BC)和逆强化学习(IRL)
。BC 使用监督学习来获得一个策略,在演示中给定一个观察的情况下,该策略能够最大化采取演示行动的可能性。这虽然使得训练时不需要在线交互,但在线 rollout 期间存在分布不匹配的情况。
IRL 在通过在线环境 rollout 使用 RL 优化策略前,从演示轨迹中推断潜在的奖励函数。这使得策略即使在任务特定奖励缺失时也能稳健地解决演示任务。尽管很强大,但 IRL 方法存在一个重大的缺陷,它们需要大量的、成本高昂的在线环境交互。
在近日一项工作中,纽约大学的研究者提出了用于模仿学习的 ROT(Regularized Optimal Transport)算法,从概念上来讲,这是一种简单的新方法,ROT 与高维观测兼容,并且与标准 IRL 方法,所需额外超参数最少。
此外,为了解决 IRL 中关于奖励的非平稳性难题,ROT 采用 OT(Optimal Transport)进行奖励计算,这种方式使用非参数轨迹匹配函数。为了减轻智能体探索的挑战,该研究在专家演示中使用 BC 预训练 IRL 行为策略。这减少了模仿智能体从头开始探索的需求。
![]()
论文地址:https://arxiv.org/pdf/2206.15469.pdf
论文主页:https://rot-robot.github.io/
然而,即使使用基于 OT 的奖励计算和预训练策略,该研究也只能获得边际收益。基于先前工作的启发,该研究通过正则化 IRL 策略来稳定在线学习过程,以保持接近预训练 BC 策略。
为了实现这一点,研究者开发了一种新的自适应权重方案,称为 soft Q-filtering,它可以自动设置正则化,即优先考虑在训练开始时紧跟 BC 策略,并优先考虑随后的探索。与先前的策略正则化方案相比,soft Q-filtering 不需要手动指定衰减时间表。
为了证明 ROT 的有效性,研究者在 DM Control、OpenAI Robotics 和 Meta-world 的 20 个模拟任务上进行了大量实验,并在 xArm 上进行了 14 个机器人操作任务(见下图 1)。
![]()
我们先来看下 ROT 的效果,机器人将盒子里的物体倒入另一个盒子,没有漏撒的情况
![]()
![]()
![]()
模仿学习面临的一个挑战是:平衡模仿演示行为的能力,以及演示状态分布之外的状态恢复能力。BC 通过监督学习来模仿演示的动作,而 IRL 专门研究如何从任意状态中恢复策略。ROT 可以将两者优势结合起来。
-
第一阶段,在专家演示数据上使用 BC 目标训练随机初始化策略,然后 BC 预训练策略用作第二阶段的初始化;
-
第二阶段,BC 预训练策略可以访问使用 IRL 目标进行训练的环境。为了加速 IRL 训练,BC 损失被添加到具有自适应权重目标中。
BC 对应于求解方程 2 中的最大似然问题,其中 T^e 指的是专家演示。当由具有固定方差的正态分布参数化方程时,我们可以将目标定义为回归问题,其中给定输入 s^e,π^BC 需要输出 a^e。
![]()
经过训练,π^BC 能够模拟与演示中看到的对应动作。
给定一个预训练 π^BC 模型,在环境中对策略 π^b ≡ π^ROT 进行在线微调。研究者使用 n-step DDPG 方法,这是一种基于确定性 actor-critic 的方法,可在连续控制中提供高模型性能。
用正则化 π^BC 进行微调很容易受到分布偏移的影响,并且直接微调 π^BC 也会导致模型性能不佳(参见第 3 节中的图 2)。为了解决这个问题,研究者基于引导 RL(guided RL) 和离线 RL 方法,通过将π^ROT 与 BC 损失相结合,将π^ROT 的训练规范化,如下方程 3 所示。
![]()
具有 Soft Q-filtering 的自适应正则化。虽然之前的工作使用经过手动调优的 λ(π) 时间表,但研究者提出了一种新的、无需调优的自适应方案。他们通过在从专家 replay 缓冲区 D_e 采样的一批数据中比较当前策略 π^ROT 和预训练策略 π^BC 的性能来完成。
![]()
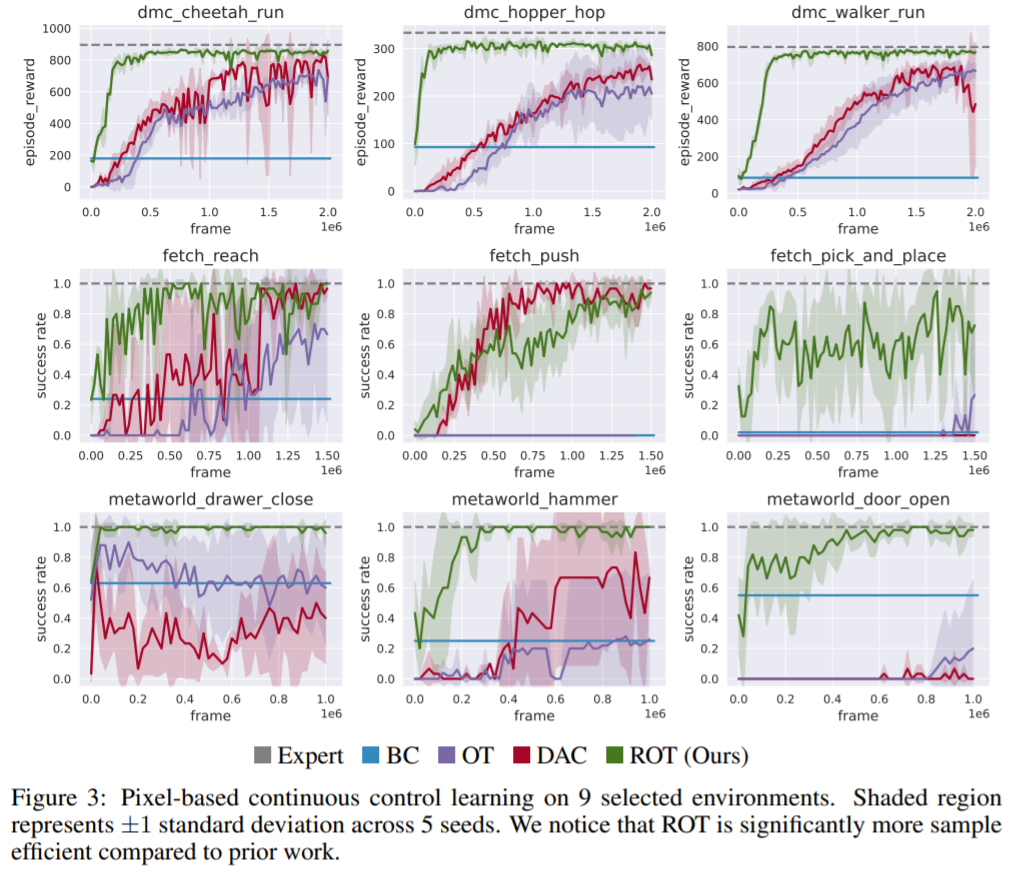
ROT 对于模仿学习的效率如何?ROT 在基于图像的模仿中的表现如下图 3 所示。在除一项任务之外的所有任务中,ROT 的训练速度明显快于之前的工作。
为了达到 90% 的专家性能,ROT 在 DeepMind Control 任务上平均快 8.7 倍,在 OpenAI Robotics 任务上快 2.1 倍,并在 Meta-world 任务上快 8.9 倍。该研究还发现,ROT 的改进在较难的任务上最为明显,位于图 3 的最右边一列。
![]()
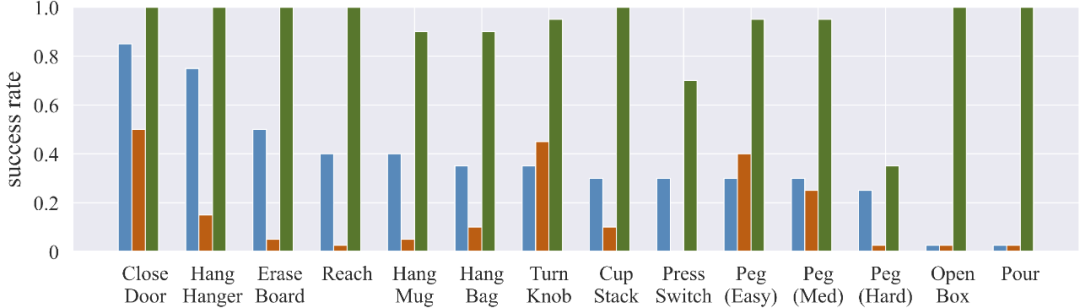
ROT 在现实世界的任务中是如何执行的?研究者在 14 个真实世界的操作任务上进行评估。仅仅通过一次演示和一小时的在线训练,ROT 在 14 项任务中的平均成功率为 90.1%,这明显高于基于行为克隆 (36.1%) 和对抗性 IRL (14.6%) 的方法。
![]()
![]()
![]()
![]()
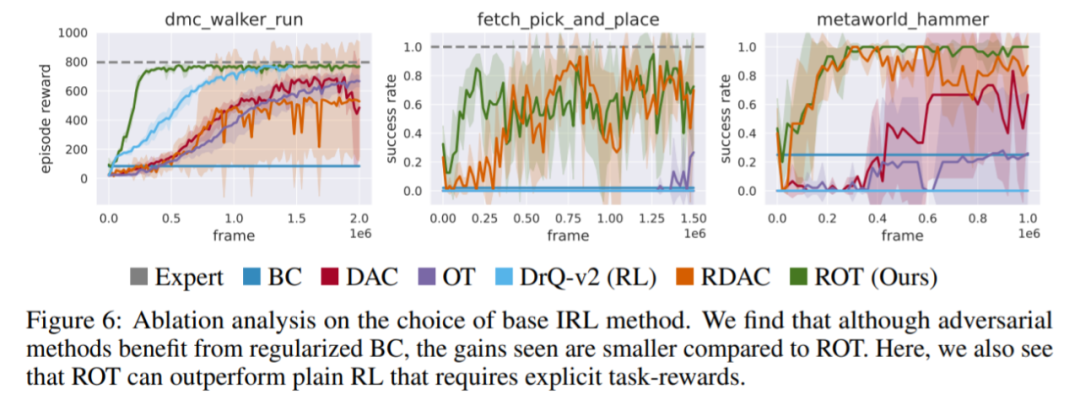
在 ROT 中 IRL 方法的选择有多重要?下图 6 将 ROT 与使用该研究中预训练和自适应 BC 正则化技术 (RDAC) 的对抗性 IRL 方法进行比较。结果发现,soft Q-filtering 方法确实改善了先前 SOTA 对抗 IRL(图 6 中的 RDAC 与 DAC)。然而,基于 OT 的方法 (ROT) 更稳定,并且平均而言会促进更有效的学习。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com