戴着VR头盔教机器人抓握,机器人当场就学会了
机器之心报道
机器人的动作往往略显笨拙,机械感太重。现在,它们可以像人一样灵活了。
近年来,机器人领域涌现出许多有趣的进展,比如机器狗会跳舞,会踢足球,双足机器人搬东西。通常这些机器人都依赖于根据感官输入生成控制策略。尽管这种方法避免了开发状态估计模块、建模对象属性和调整控制器增益方面的挑战,但需要大量的领域专业知识。即使取得了诸多进展,但学习瓶颈让机器人难以执行任意任务,无法实现通用的目标。
实际上还有第三种方法,收集训练数据还可以要求人类教师提供演示,然后训练机器人快速模仿人类的演示。这种模仿方法最近在各种具有挑战性的操作问题中显示出巨大的潜力。然而,这些工作中的大多数都存在一个根本性的限制——为机器人收集高质量的演示数据是很困难的。
基于上述问题,来自纽约大学和 Meta AI 的研究者提出了 HOLO-DEX,这是一个收集演示数据和训练灵巧机器人的新框架。它使用 VR 头显(例如 Quest 2)将人类教师置于身临其境的虚拟世界中。在这个虚拟世界中,教师可以从机器人的眼睛中查看机器人「看到」的场景,并通过内置的姿势检测器控制 Allegro 机械手。
看起来就像是人「手把手」教机器人做动作:

HOLODEX 允许人类通过低延迟的观察反馈系统为机器人无缝提供高质量的演示数据,它有以下三个优点:
与自监督的数据收集方法相比,HOLODEX 基于强大的模仿学习技术,可以在没有奖励机制的情况下快速训练;
与 Sim2Real 方法相比,学得的策略可以直接在真实机器人上执行,因为它们是在真实数据上训练的;
与其他模仿方法相比,HOLODEX 显著减少了对领域专业知识的要求,只需要人们操作 VR 设备。

论文链接:https://arxiv.org/pdf/2210.06463.pdf
项目链接:https://holo-dex.github.io/
代码链接:https://github.com/SridharPandian/Holo-Dex
为了评估 HOLO-DEX 的性能,该研究在六个需要灵巧操作的任务上进行了实验,包括手持物体、单手拧开瓶盖等。该研究发现人类教师使用 HOLO-DEX 可以比单图像遥操作(teleoperation)的先前工作快 1.8 倍。在 4/6 任务上,HOLO-DEX 学习策略的成功率超过了 90%。此外,该研究还发现通过 HOLO-DEX 学得的灵巧策略可以泛化到新的、未见过的目标对象上。

总的来说,该研究的贡献包括:
提供了一种借助 VR 头显让人类教师在混合现实中实现高质量遥操作的方法;
实验表明,HOLO-DEX 收集的演示可用于训练有效且通用的灵巧操作行为;
该研究还对所提方法中的各种决策进行了分析和消融实验,以验证每一个关键设计的效用。
此外,与 HOLO-DEX 相关的混合现实 API、研究收集的演示和训练代码均已开源:https://holo-dex.github.io/
HOLO-DEX 架构概览
如下图 1 所示,HOLO-DEX 分两个阶段运行。在第一阶段,人类教师使用虚拟现实 (VR) 头显向机器人提供演示。这个阶段包括创建一个用于教学的虚拟世界、估计(estimate)教师的手部姿势、将教师的手部姿势重定位到机械手上,最后控制机器人的手部。在第一阶段收集了一些演示之后,HOLO-DEX 的第二阶段学习视觉策略来解决演示的任务。

该研究使用 Meta Quest 2 VR 头显将人类教师置于虚拟世界中,分辨率是 1832 × 1920,刷新率是 72 Hz。这款头显的基础版售价为 399 美元,相对较轻,只有 503 克,这让教师的演示操作更轻松舒适。更重要的是,Quest 2 的 API 接口允许创建自定义的混合现实世界,将机器人系统与 VR 中的诊断面板一起可视化。
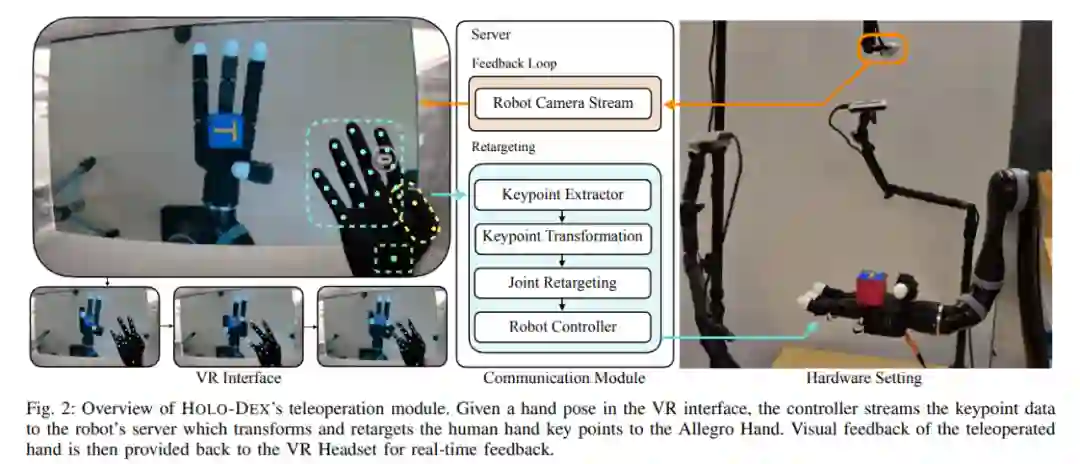

使用 VR 头显估计手部姿势
相比于之前关于灵巧遥操作的工作相比,使用 VR 头显在人类教师的手部姿势估计方面具有三个好处。首先,由于 Quest 2 使用 4 个单色摄像头,其手势估计器比单摄像头估计器强大很多。其次,由于摄像机是内部校准的,因此它们不需要以前的多摄像机遥操作框架中所需的专门校准程序。第三,由于手部姿势估计器是集成到设备中的,因此它能够以 72Hz 的频率传输实时姿势。此前有研究指出,灵巧遥操作的一个重大挑战是以高精度和高频率获取手部姿势,HOLO-DEX 通过使用商业级 VR 头显显著简化了这个问题。
手部姿势重定向
下一步,从 VR 中提取的教师手部姿势需要重定位到机器手上。这首先要计算教师手部各个关节的角度,然后一种直接的重定向方法是「命令」机器人的关节变动到相应的角度。这种方法适用于该研究中除拇指以外的所有手指,但 Allegro 机械手的形态与人类不是完全匹配的,拇指不能完全套用这种方法。
为了解决这个问题,该研究将教师拇指指尖的空间坐标映射到机器人的拇指指尖,然后通过逆运动学求解器计算拇指的关节角度。需要注意的是,由于 Allegro 机械手没有小拇指,该研究也就忽略了教师的小拇指角度。
整个姿势重定向过程不需要任何校准或教师特定的调整来收集演示。但该研究发现可以通过查找从教师拇指到机器人拇指的特定映射来改进拇指重定向。整个过程的计算成本很低,并且可以以 60 Hz 的频率传输所需的机器手姿势。
机器手控制
Allegro Hand 通过 ROS 通信框架进行异步控制。给定重定向程序计算的机器手关节位置,该研究使用 PD 控制器以 300Hz 输出所需扭矩。为了减少稳态误差,该研究使用重力补偿模块来计算偏移扭矩。在延迟测试中,该研究发现当 VR 耳机与机器人手在同一本地网络上时,可以实现低于 100 毫秒的延迟。低延迟和低错误率对于 HOLO-DEX 至关重要,因为这允许人类教师对机器手进行直观的遥操作。
当人类教师控制机器手时,他们可以实时看到机器人的变化(60Hz)。这允许教师纠正机器手的执行错误。在教学过程中,该研究以 5Hz 的频率记录来自三个 RGBD 摄像机的观察数据和机器人的动作信息。由于记录多个摄像机所需的大量数据占用空间和相关带宽,该研究不得不降低记录频率。
使用 HOLO-DEX 数据进行模仿学习
收集数据后就进入了第二阶段,HOLO-DEX 要在数据上训练视觉策略。该研究采用最近邻模仿 (INN) 算法进行学习。在之前的工作中,INN 被证明可以在 Allegro 手上产生基于状态的灵巧策略。HOLO-DEX 更进一步,并证明这些视觉策略可以推广到各种灵巧操作任务中的新对象。
为了选择获得低维嵌入的学习算法,该研究尝试了几种最先进的自监督学习算法,发现 BYOL 提供了最好的最近邻结果,因此选择 BYOL 作为基本的自监督学习方法。
实验结果
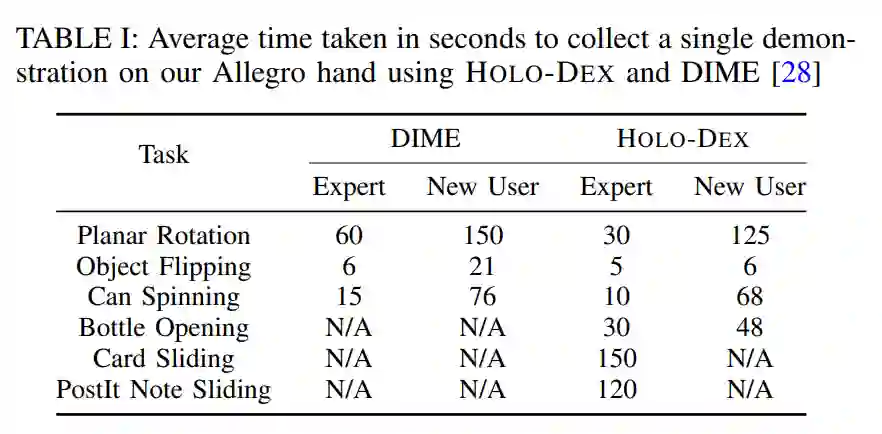
下表 1 展示了 HOLO-DEX 收集成功演示的速度比 DIME 快 1.8 倍。对于需要精确 3D 运动的 3/6 任务,该研究发现单图像遥操作甚至不足以收集单个演示。

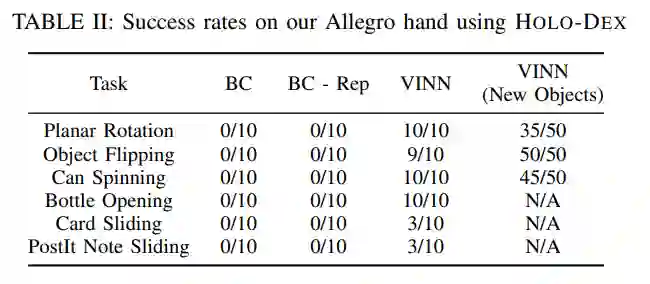
该研究检查了各种模仿学习策略在灵巧任务上的性能,不同策略下每个任务的成功率如下表 2 所示。
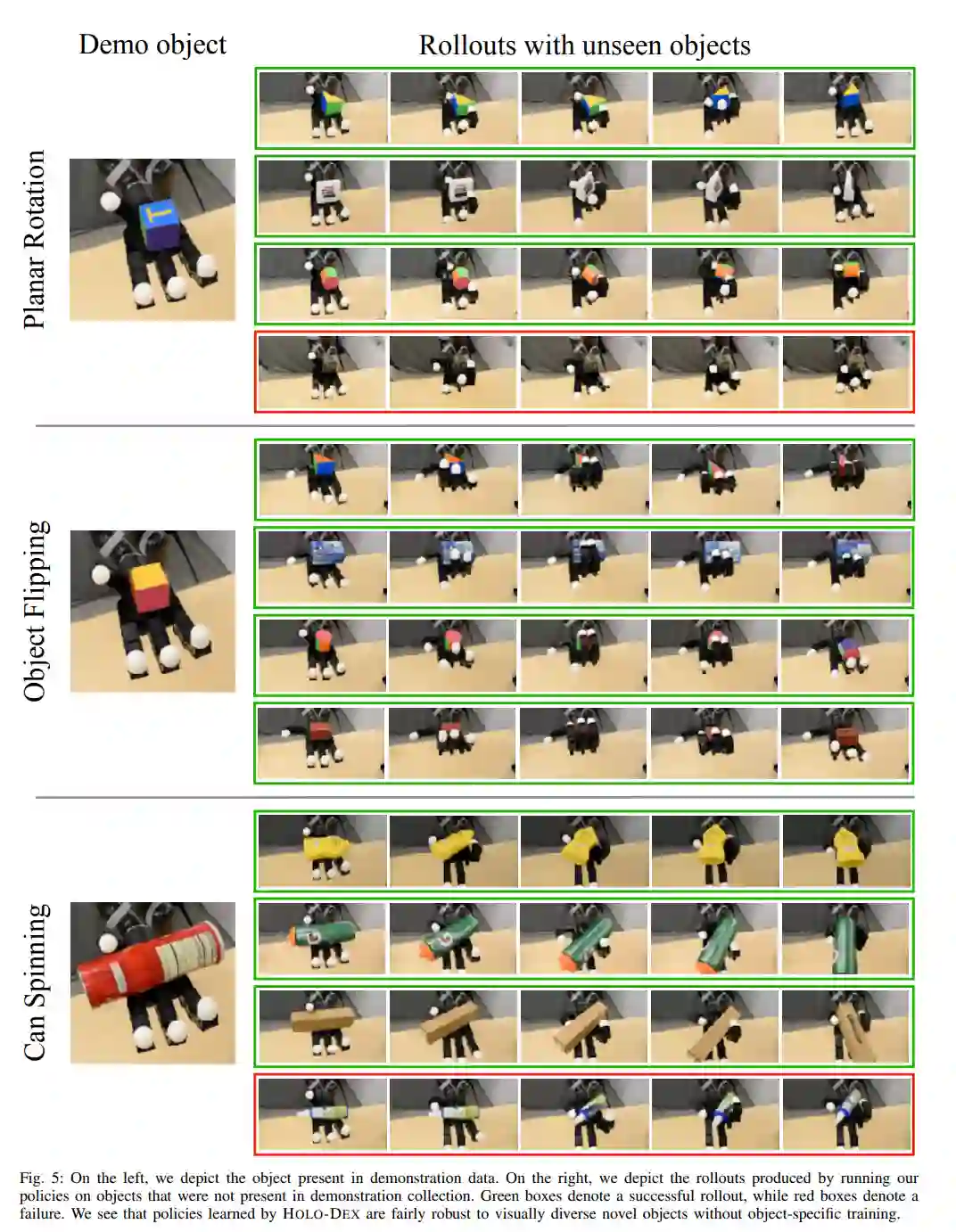
由于该研究提出的策略是基于视觉的,并且不需要明确估计对象的状态,因此它们能与训练中未见过的对象兼容。该研究评估了其手动操作策略,这些策略经过训练可在多种视觉外观和几何形状的对象上执行平面旋转、对象翻转和 Can Spinning 任务,如下图 5 所示。
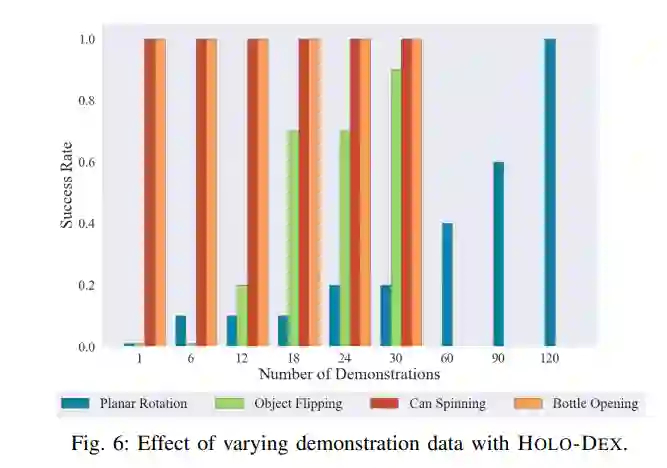
此外,该研究还在不同任务的不同大小的数据集上测试了 HOLO-DEX 的性能,可视化结果如下图所示。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


