MIT 研究“看见”神经网络形成概念过程,神经网络不全是黑箱
新智元编译
来源:news.mit.edu
编译:文强
【新智元导读】MIT 新研究为解开深度神经网络黑箱迈出重要一步:今年的CVPR上,研究者提交一份新的研究,全自动分析了 ResNet,VGG-16,GoogLeNet 和 AlexNet 执行 20 多种任务的过程。他们提出的 Network Dissection 能够量化 CNN 的可解释性,发现深度神经网络并非完全的黑箱结构。

神经网络性能强大,用处广泛,但有一个致命的缺点:一旦训练好,哪怕是设计者也无从得知其中的运作原理。没错,也就是所谓的黑箱。
2 年前,MIT 计算机科学和人工智能实验室(CSAIL)团队的一组计算机视觉研究员提出了一种方法,能够“窥视”神经网络的黑箱。这种方法提供了一些有趣的见解,然而其所需的数据需要事先经过人工标记,费时费力。
在今年的计算机视觉顶会 CVPR 上,MIT CSAIL 研究人员将发布同一个系统的全自动版本。将整个过程自动化很重要,因为这意味着结果不是由人,而是由机器生成的,这对解开神经网络的黑箱是重要的一步。
在之前的研究论文中,CSAIL 研究组分析了一种能够完成一项任务的神经网络。在新的论文中,作者分析了 4 种神经网络,分别是 ResNet,VGG-16,GoogLeNet 和 AlexNet,这 4 种神经网络能够完成 20 种任务,包括识别场景和物体、为灰色图像上色,以及解决拼图。
研究人员还在这些网络上进行了几组实验,得出的结果结果不仅对研究计算机视觉和计算摄影算法有用,还对人类大脑的组织方式提供了启发。

上图显示了,在 VGG-16、GoogLeNet 和 ResNet 中,选定的单元经过训练后,可以对地点(来自数据集 Places-365)进行分类。许多单个的单元会对特定的高级概念(物体分割)产生响应,而这些高级概念是网络在训练数据集(场景分类)中没有接触过的。
与人类大脑中神经元连接的方式类似,神经网络也是由大量节点构成。当接收到相邻节点传递的信息后,网络节点要么“发射”信号,也即产生响应,要么什么都不做。不同的节点发射信号的强度也各有不同。
在新旧论文中,MIT 研究人员训练神经网络执行计算机视觉任务,根据设计,单个节点针对不同的输入的响应可以被检测到。然后,研究人员选择了 10 幅能最大程度刺激神经元产生响应的输入图像。
论文的联合第一作者之一、MIT 电气工程研究生 David Bau 说:“我们编目了 1,100 个视觉概念,例如绿色、漩涡纹理、木质材料、人脸、自行车车轮或雪山顶。”“我们借用了其他人开发的几个数据集,将它们合并成一个视觉概念数据集。这个数据集有很多很多标签,对于每个标签,我们都知道哪幅图像中哪个像素对应于这个标签。”
研究人员还知道哪些图像的像素对应于给定网络节点的最强响应。神经网络是一层一层组成的。数据先被馈送到最低层,处理后会再传递到下一层,以此类推。在处理视觉数据时,输入图像被分成小块,每一块被馈送到单独的输入节点。
对于网络中高层节点的强烈反应,研究人员可以追溯到它的触发模式,从而识别出对应的特定图像像素。因为研究人员开发的系统可以很快识别出这样的像素对应的标签,因此可以精确地表征节点的行为。
研究人员将数据库中的视觉概念组织成一个层次结构。其中,每个层次结合了以下级别的概念,从颜色开始,到纹理,材料,部分,对象和场景。通常,神经网络的较低层将对更简单的视觉特征(例如颜色和纹理)产生响应,较高的层则对更复杂的特征产生响应。
此外,层次结构也让研究人员能够量化训练好的网络在执行不同视觉特性任务时所分配的重点。例如,为黑白图像上色的网络为将大部分节点用于识别纹理。另外一个用于在多帧视频中跟踪对象的网络,则将较高比例的节点用于场景识别。
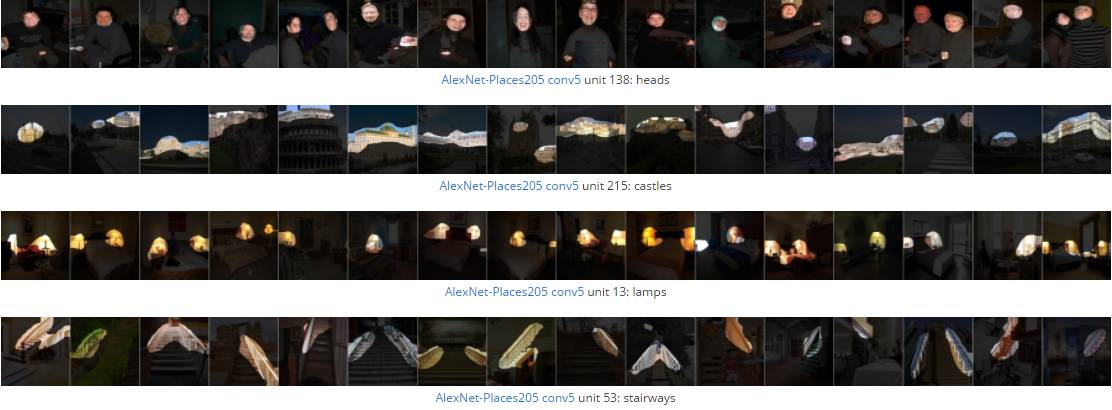
这些可解释的单元十分有趣,因为它们的存在表明了深度神经网络并非完全的黑箱结构。但是,目前并不清楚这些可解释单元是否能证明所谓“disentangled representation” 存在。
研究人员在论文中致力于回答以下 3 个问题:
什么是 disentangled representation?如何量化并检测它的因子?
可解释的隐藏单元是否反映了特征空间上一种特殊的一致性?还是说,可解释性是不存在的(chimera)?
当前最先进训练方法中的什么条件,使表征中产生了 entanglement?
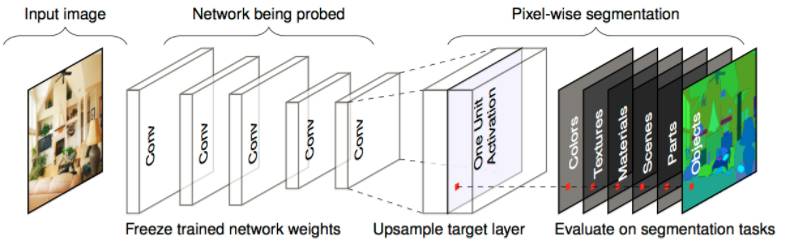
研究人员提出了一个整体框架式的 Network Dissection(见下),用于量化 CNN 的可解释性。他们还分析了 CNN 训练技术对可解释性的影响,发现不同层的表征揭示了含义的不同类别,而不同的训练技术对隐藏单位学习的表征的可解释性有显著影响。
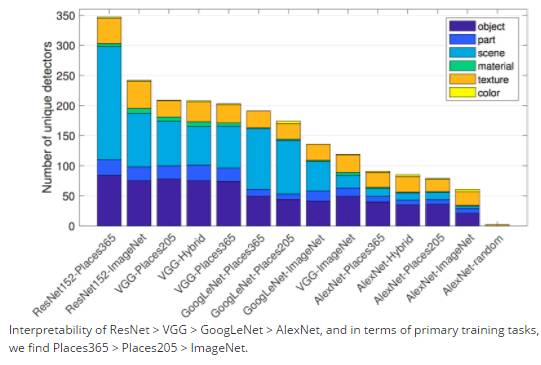
结果发现,网络的可解释性 ResNet >VGG >GoogLeNet > AlexNet,并在在训练任务中,数据集的结果也不同,Places365 > Places205 >ImageNet。
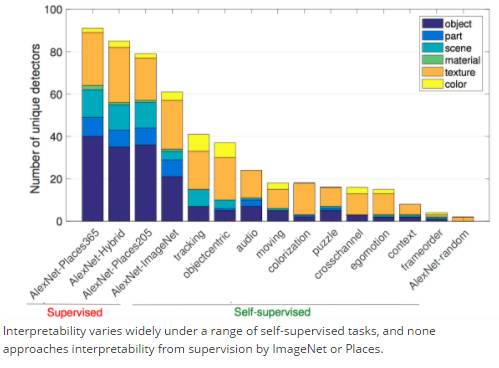
在自监督任务中,对于不同的任务,可解释性也各不相同。
不仅如此,Network Dissection 还让研究人员“看见”了在训练时,网络“形成概念”的过程。
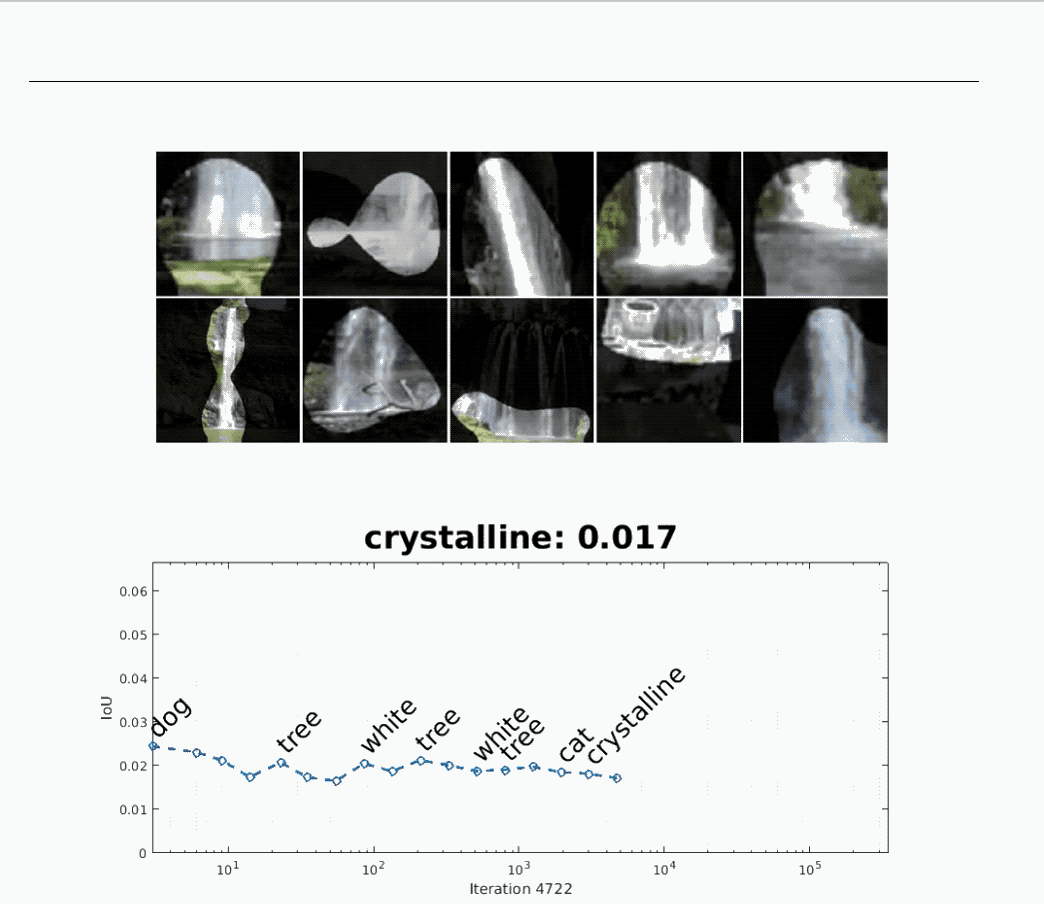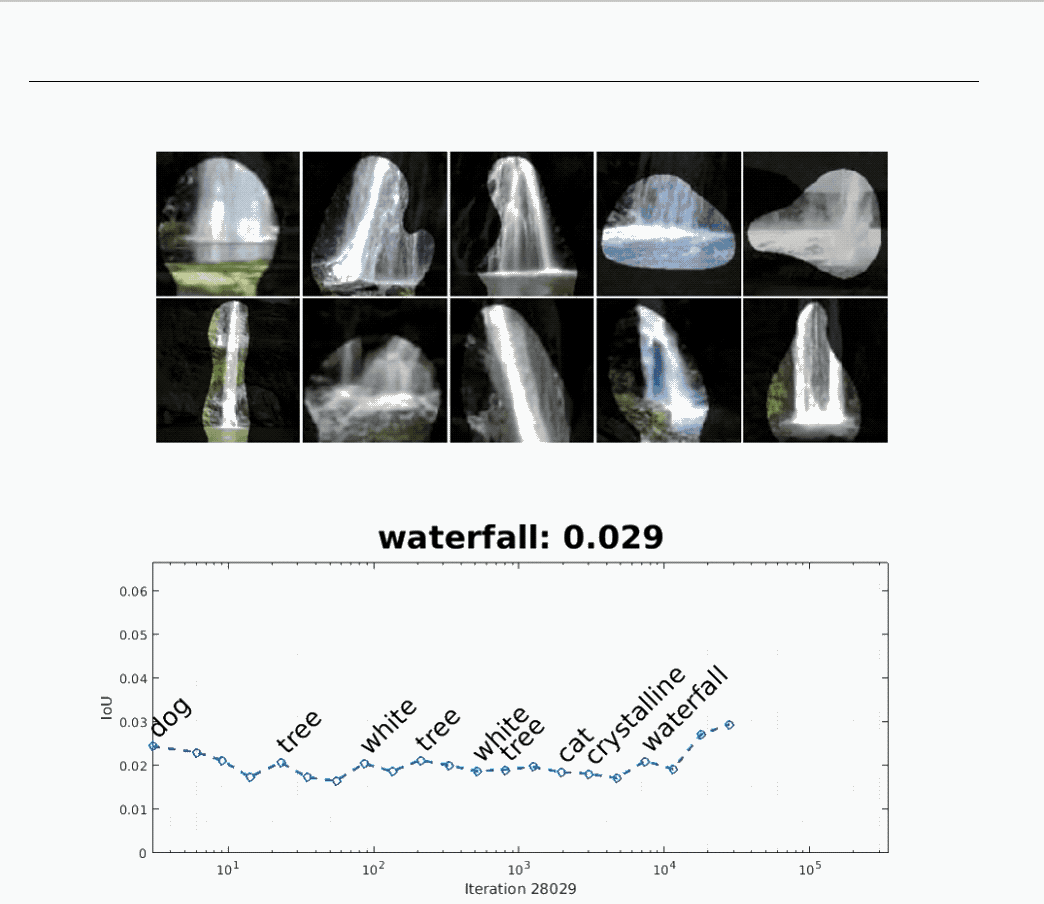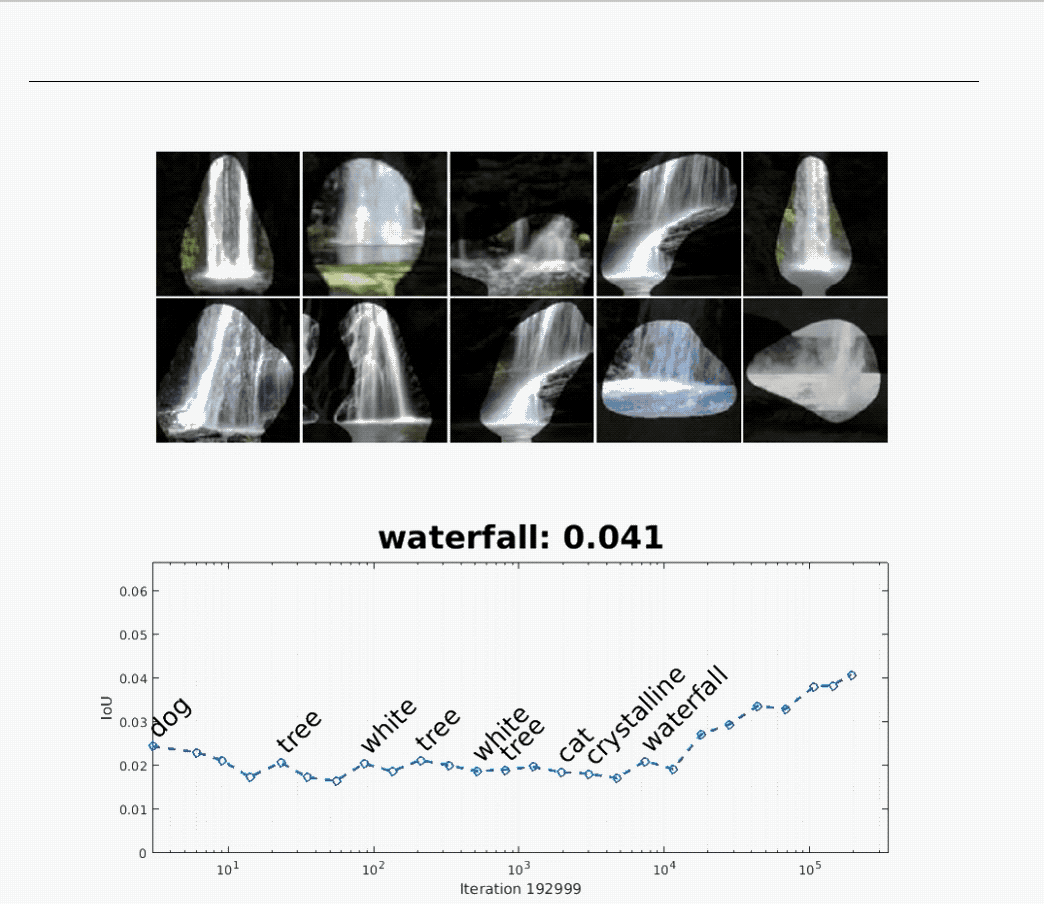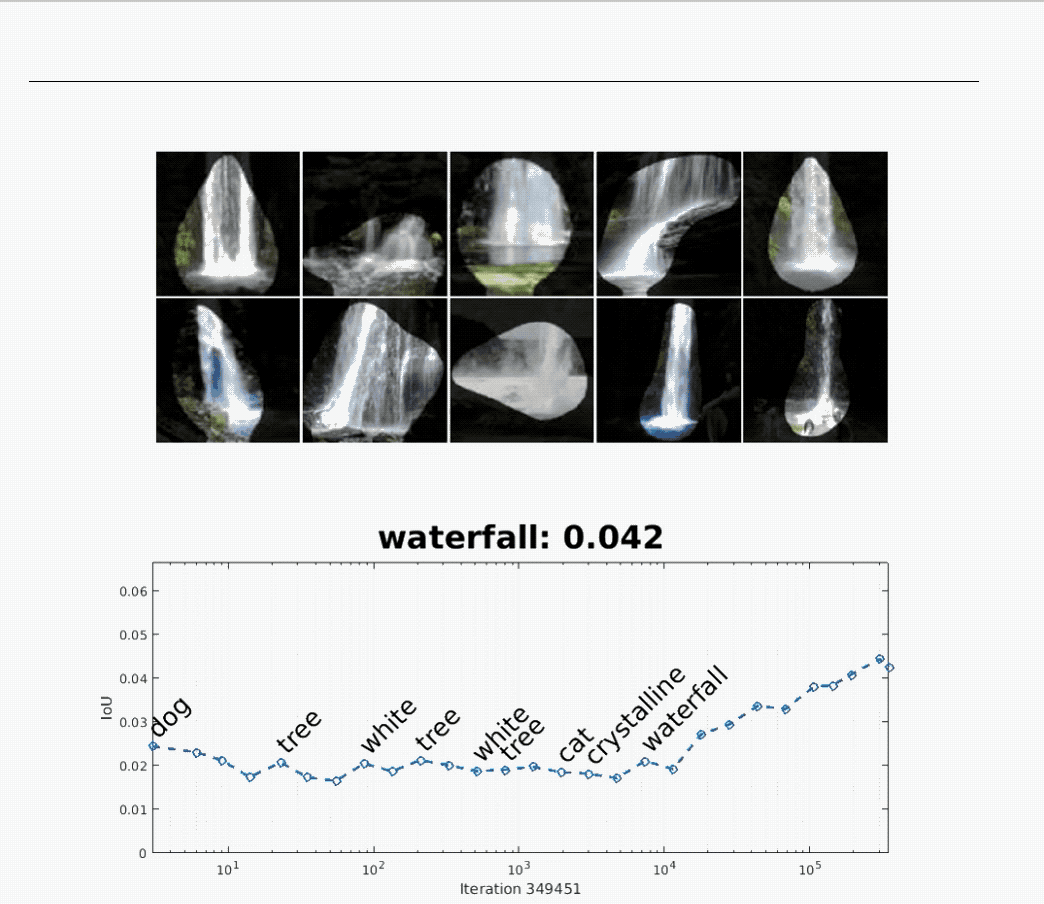
上面的动图显示了,一开始用于识别“狗”的神经网络,在后来变为识别“瀑布”的神经网络。
研究人员进行的实验中,还有一项为神经科学中长期以来的一项争论给出了答案。此前有研究表明,大脑中单个神经元会对特定的刺激产生响应。这一假说最初被称为祖母神经元假说,后来又被称为“詹妮弗·安妮斯顿神经元假说”而广为人知。当时,提出詹妮弗·安妮斯顿神经元假说的科学家发现,他们实验中的几位患者,有的神经元似乎只对特定好莱坞名人的脸作出反应。
很多神经科学家都不同意这一假说。他们认为,是不同的神经元的组合,而不是单个的神经元,在大脑中负责确定判别感知。因此,所谓的詹妮弗·安妮斯顿神经元只是许多神经元之一,是对詹妮弗·安妮斯顿的脸的图像产生响应的神经元的一部分。这部分神经元还可能是许多其他神经元组合的一部分,只是那些组合现在还没有被观测到而已。
由于 MIT 研究人员提出的新分析技术是完全自动化的,所以能够测试神经网络中是否发生了类似的事情。除了识别对特定视觉概念产生响应的单个网络节点外,研究人员还考虑了随机选择的节点组合。但是,结果发现节点组合选择的视觉概念远远少于单个节点——大约减少了80%。
Bau 说:“在我看来,这表明神经网络实际上在努力得到一个祖母神经元的近似。神经元并不想把祖母的概念弄得到处都是,而是把这个概念分配给一个神经元。这一结构的这一点,大多数人都不相信这么简单。”

摘要
我们提出了一个通用框架,叫做网络解剖(Network Dissection),通过评估单个隐藏单元和一组语义概念之间的一致性程度,量化 CNN 潜在表征的可解释性。给定任何 CNN 模型,我们所提出的方法利用一个含有大量视觉概念的数据集,评估每个中间卷积层隐藏单元的语义。具有语义的单元会被赋予一系列不同的标签,包括对象,部件,场景,纹理,材质和颜色。我们使用所提出的方法测试了这样一个假说,即单元的可解释性等同于该单元随机线性组合。然后,我们应用我们的方法比较各种网络的潜在表征,这些网络都被训练用于解决不同的监督和自我监督的任务。我们进一步分析训练迭代的效果,比较不同初始化训练的网络,检查网络深度和宽度的影响,并测量 dropout 和批量归一化对深度视觉表征可解释性的影响。我们展示了所提出的方法可以揭示 CNN 模型以及相关训练方法的特性。
论文地址:http://netdissect.csail.mit.edu/final-network-dissection.pdf

点击阅读原文查看新智元招聘信息

