TensorFlow神经网络教程

Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
TensorFlow是机器学习应用的一个开源库。这是谷歌大脑的第二代系统,取代闭源项目DistBelief,并被谷歌同时用于研究和产品。TensorFlow应用可以用几种语言书写:Python,Go,Java和C。这篇文章主要涉及它的Python版本,并关注库的安装、基本的低级组件,以及从头构建一个前馈神经网络,以便在真正的数据集上学习。
深层学习神经网络的训练时间往往是其在复杂场景应用时遇到的一个瓶颈。由于神经网络,以及其他的学习算法,通常都在用矩阵乘法,用图形处理器(GPU)而不是中央处理器(CPU)进行计算显然会更快。
TensorFlow同时支持CPU和GPU,并且谷歌甚至为此专门推出了性能上优于其他处理器的云计算硬件——Tensor处理器(TPU)。
安装
TPU在云端才可用,而TensorFlow的本地安装可以针对CPU或GPU构架。想要用GPU版本,你的电脑必须要有一个NVIDIA显卡和其他一些要求。
基本上,至少有5种不同的安装选择:virtualenv, pip, Docker, Anaconda, 和从源安装。
·用virtualenv和Docker安装可以把TensorFlow安装在一个相对独立的环境。
·Anaconda是一个内嵌了大量科学计算库的Python发型版,这些库中也包括TensorFlow。
·pip则是安装python包最自然的工具,不需要依赖第三方环境。
·最后,通过Git来从源安装,是安装一个特定版本的TensorFlow的最好方法,这些版本中也包括当前最稳定的r1.4(撰写本文时)。
最常见和最简单的方式还是通过virtualenv和pip,因此这两种方法会在文中着重介绍。
如果你已经使用Python一段时间了,你可能知道pip。下面是如何在Ubuntu上得到它:

以下几行是在Ubuntu和Mac OSX上安装TensorFlow的方法:

上述这些命令在Windows下的Python 3.5.x和3.6.x下也可以用。
在一个单独环境中安装TensorFlow则可以通过virtualenv或者conda(Anaconda的一部分)。过程大致可以遵循相同的代码,唯一不同的是,你需要用virtualenv先创建并激活一个新的环境:

这种方法可以使得所有需要的包和你之前在你操作系统上配置的全局包隔离开。
核心应用接口组件
有多种应用接口可以用于编写TensorFlow。最底层的一个被称为核心,并以张量、图形、会话这三个基本组件工作。
此外还有更高层的应用接口(如tf.estimator),用于简化工作流程和自动化数据集管理、学习、评估等过程。无论如何,了解库的核心的特性对于构建最新的机器学习应用程序至关重要。
核心应用接口的重点在于构建一个计算图,它包含一系列排列成节点图形的操作。每个节点可以有多个张量(基本数据结构)作为输入,并对它们执行操作以便计算输出,在一个多层网络中这个输出又可以作为其他节点的输入。这种类型的架构适用于机器学习应用,如神经网络。
张量
张量是TensorFlow中的基本数据结构,它存储任意维数的数据,类似于NumPy中的多维数组。 张量有三种基本类型:常量,变量和占位符。
·常量是张量不变的类型。 他们可以被看作没有输入的节点,输出他们存储在内部的单个值。
·变量是可变类型的张量,其值可以在图形运行期间改变。在机器学习应用中,变量通常存储需要优化的参数(例如,神经网络中节点之间的权重)。变量需要在运行图形之前通过调用一个特殊的操作来初始化。
·占位符是存储来自外部数据的张量的张量。它们代表了一个“承诺”,即在图形运行时将提供一个值。 在ML应用程序中,占位符通常用于向学习模型输入数据。
以下几行给出了三种张量类型的例子:
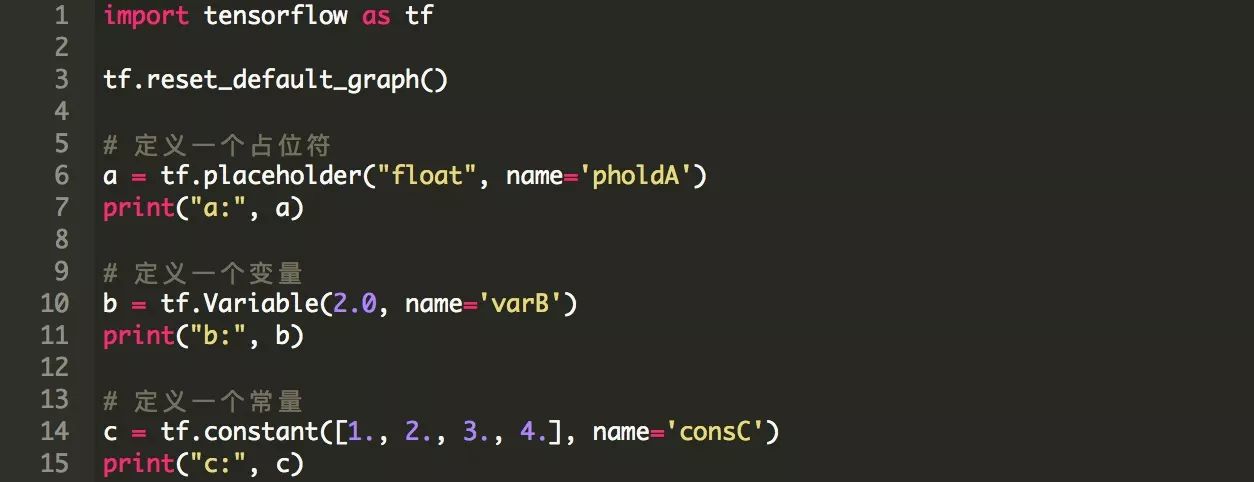

请注意,张量在此处不包含值,并且只有当图形在会话中运行的时候它们的值才可用。
图形
目前为止,图形只保存没有连接的3个张量。现在,让我们对张量进行一些操作:


结果输出又是一个名为"add"的张量,现在我们的模型看起来如下图所示。你可以使用TensorFlow的内置功能TensorBoard探索你的图形以及其他参数。
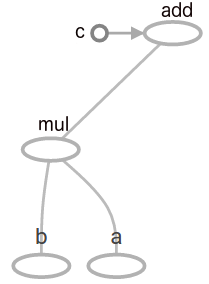
图1:由一次乘法和加法组成的TensorFlow图。
另一个探索图形的有用工具如下代码所示,它可以将所有的操作输出到屏幕。


会话
最后,我们的图应该在会话中运行。请注意,变量被预先初始化,而占位符张量则通过feed_dict接收具体值。
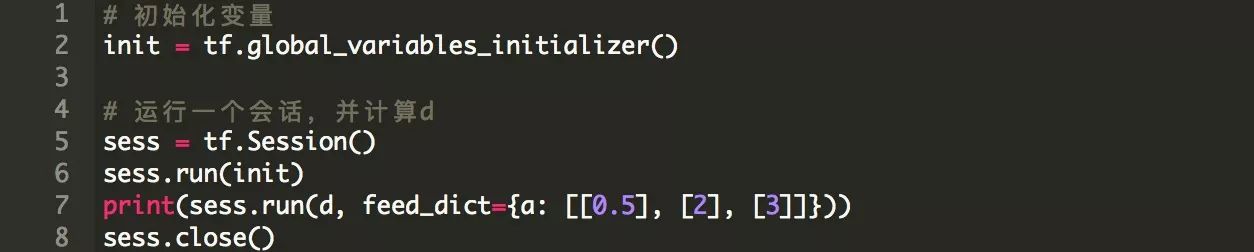

上面的例子是一个学习模型的简化。总之,它显示了如何将基本的tf组件组合在一个图表中并在会话中运行。此外,它还说明了操作如何在不同模型的张量上运行。
在下面的章节中,我们将使用核心应用接口来在一个真实数据集上构建一个用于机器学习的神经网络。
神经网络模型
在这一部分我们使用TensorFlow的核心组件从头开始建立一个前馈神经网络。 我们比较一个神经网络的三种结构,这将在一个隐藏层中的节点数量上有所不同。
Iris数据集
我们使用简单的Iris数据集,该数据集由150个植物实例组成,每个实例都有其4个纬度(用作输入要素)及其类型(需要预测的输出值)。 一种植物可以属于三种可能的输出类型之一:setosa,virginica和versicolor。 我们首先从TensorFlow的网站下载数据 - 它分为120个样本的训练集和30个样本的测试集。
模型和学习
我们的神经网络的输入和输出层的形状将对应于数据的形状,即输入层将包含代表四个输入特征的四个神经元,而输出层将包含三个神经元,每一个神经元存储1比特,3比特以独热的方式可以存储植物的三种类型。例如“setosa”物种可以用矢量[1,0,0]编码,“virginica”用[0,1,0]编码。
我们为隐藏层中的神经元数目选择三个值:5,10和20,得到(4-5-3),(4-10-3)和(4-20-3)的网络大小。 这意味着,例如(4-5-3)将有4个输入神经元,5个“隐藏”神经元和3个输出神经元。
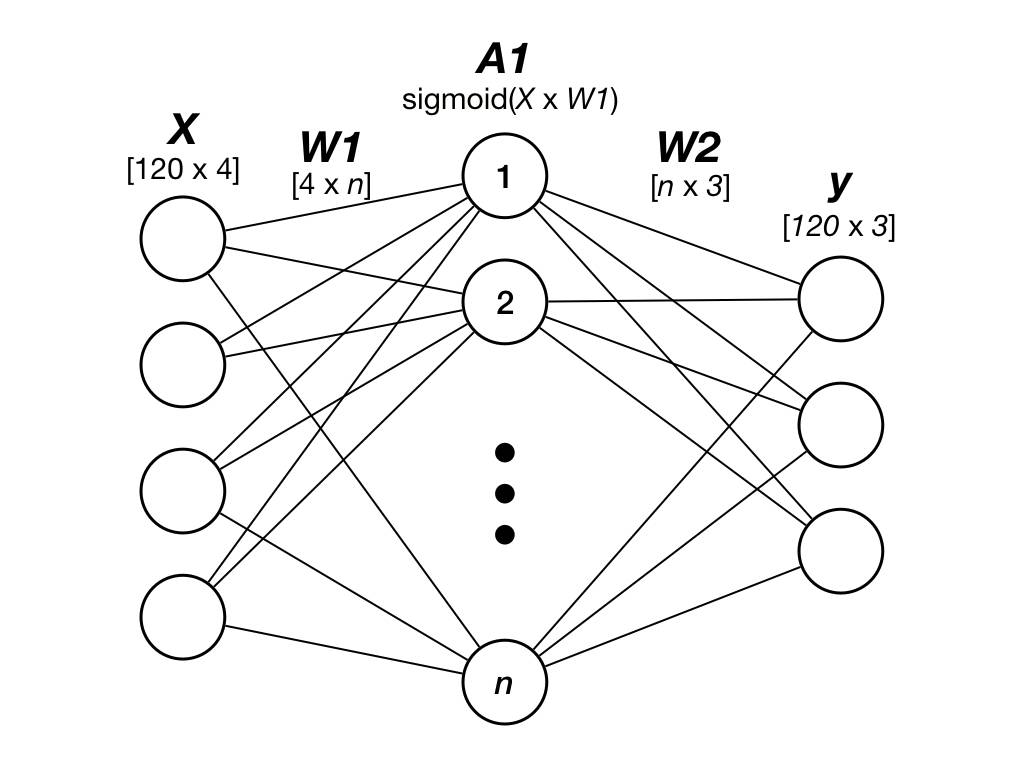
图2:我们的三层前馈神经网络
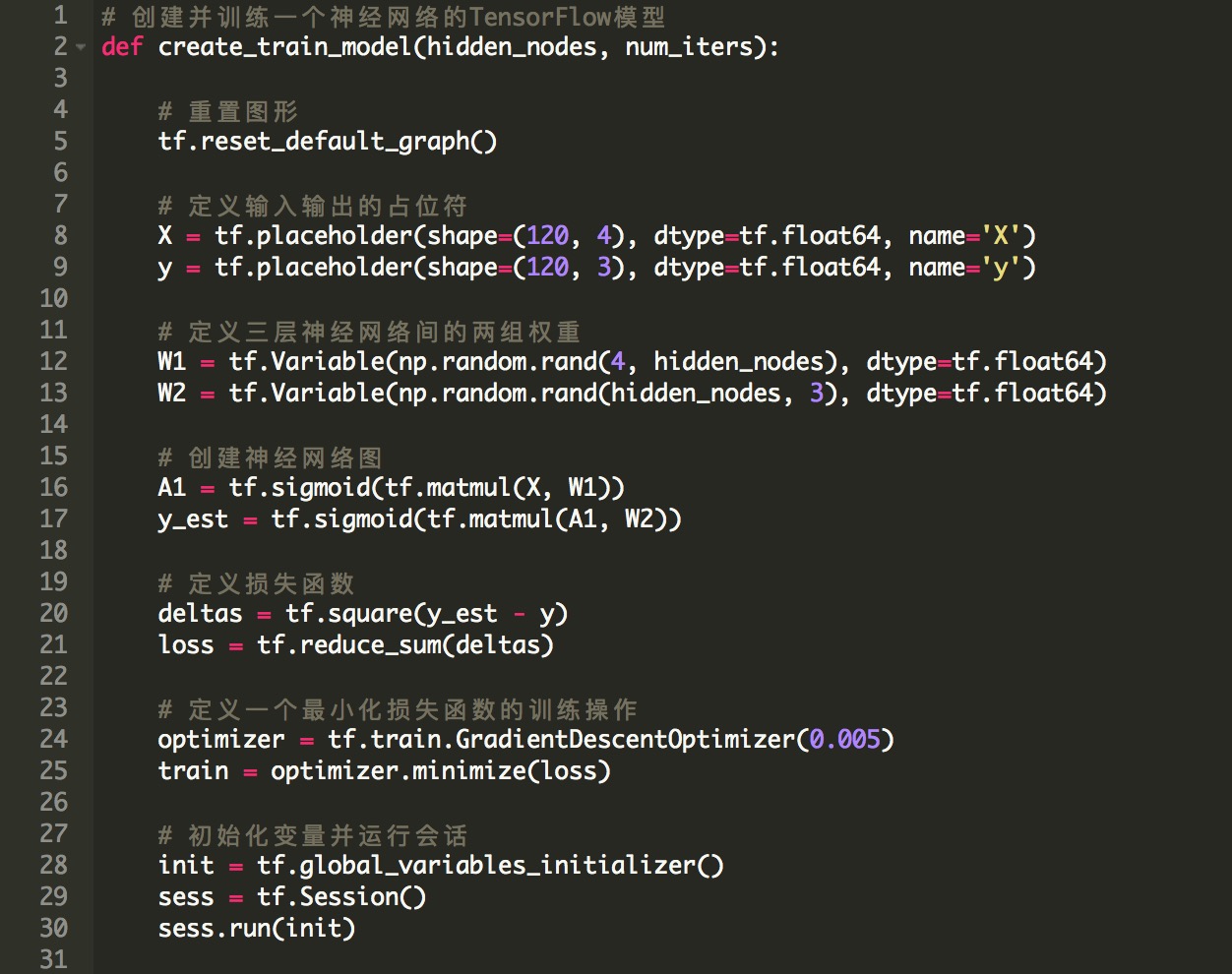
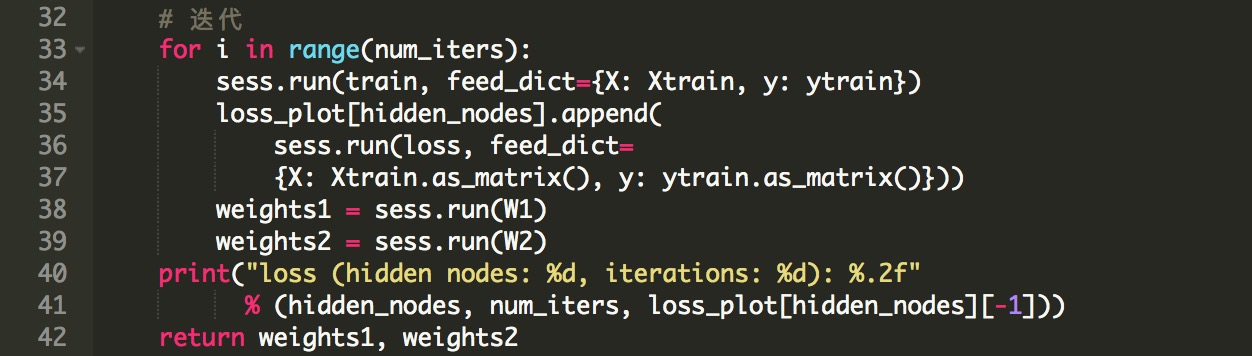
下面的代码定义了一个函数,我们在这个函数中创建模型,定义一个需要最小化的损失函数,并且运行2000次迭代,来训练习得最优权重W_1和W_2。 如前所述,输入和输出矩阵被馈送到tf.placeholder张量,并且权重被表示为变量,因为它们的值在每次迭代中变化。损失函数被定义为我们预测y_est和实际物种类型y之间的平均方差,我们使用的激活函数是sigmoid。最后,由create_train_model函数返回学习权重并输出损失函数的最终值。
好,让我们创建(之前提到的)三个神经网络架构,并在迭代中绘制损失函数。
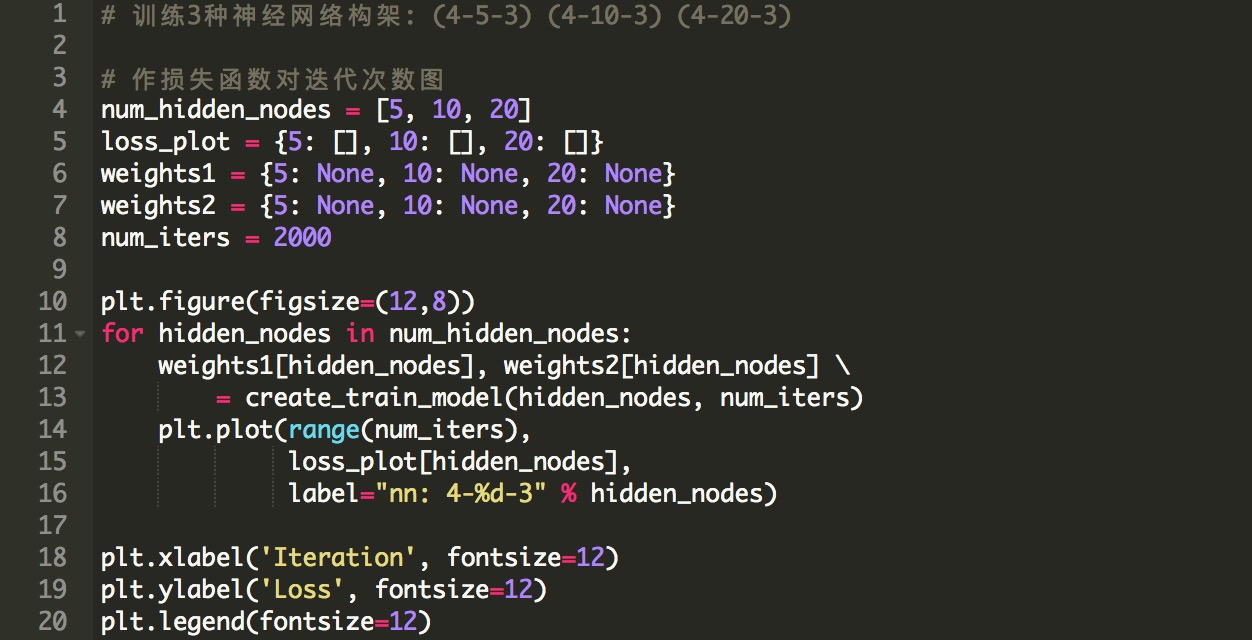

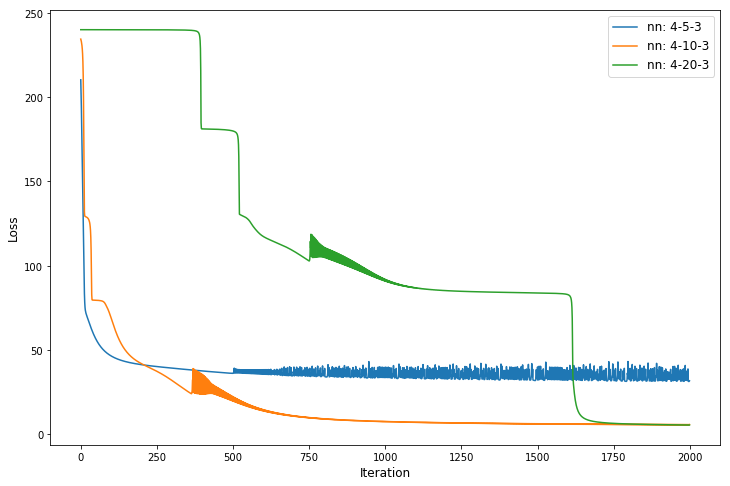
图3:2000次迭代后,不同神经网络构架的损失函数。
我们可以看到,具有20个隐藏神经元的网络需要更多的时间来达到最小值,这是由于其更高的复杂性。而具有5个隐藏神经元的网络陷入局部最小值,并且不会给出好的结果。
无论如何,对于Iris这样简单的数据集,即使是具有5个隐藏神经元的小网络也应该能够学习到一个好的模型。在我们的例子中,这只是一个随机事件,模型被限制在一个局部最小值,而且如果我们一次又一次地运行代码,它并不会经常发生。
模型评估
最后,让我们来评估我们的模型。我们使用学习权重W_1和W_2,将模型应用于测试集的类型的预测。准确性定义为正确预测样本的百分比。
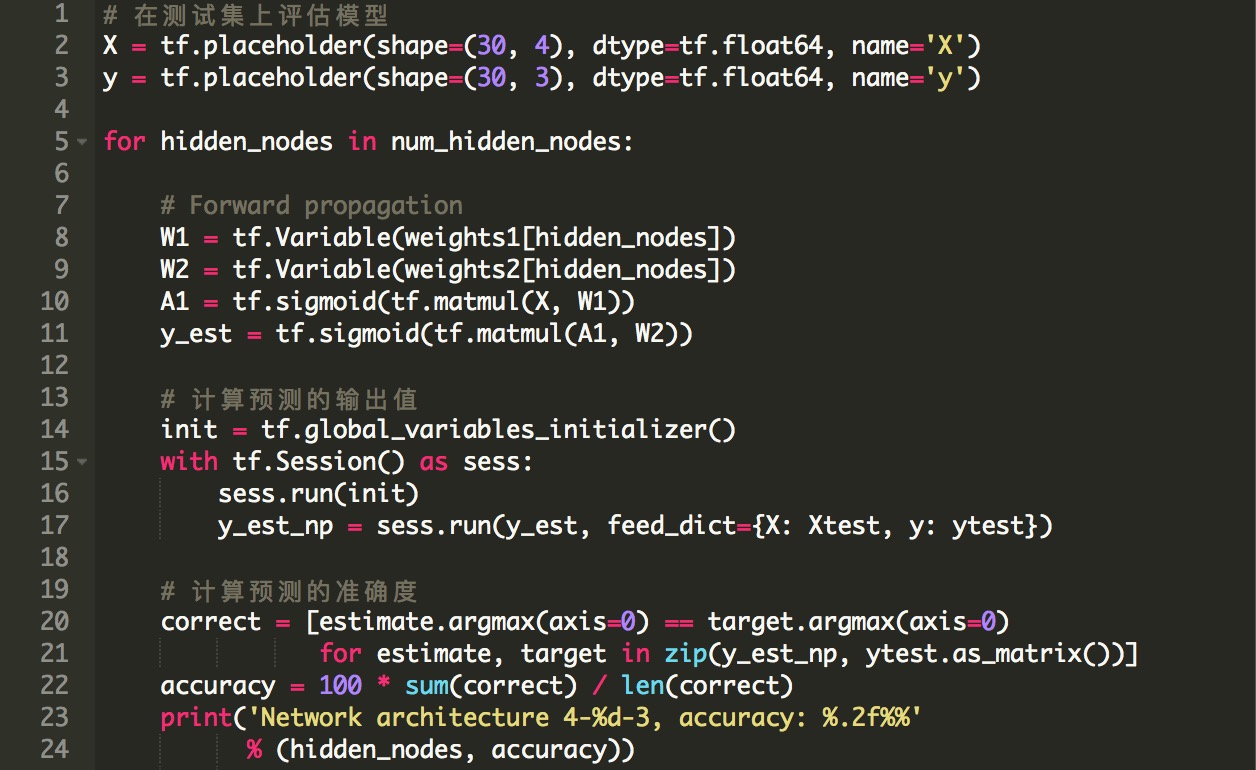

总的来说,我们设法用一个简单的前馈神经网络来达到非常高的精确度,特别是使用一个非常小的数据集的却达到如此高精度的预测,这非常令人惊讶。
你可以在这里使用TensorFlow的高级应用接口来看一个更简单的例子。
资源
本教程只介绍了TensorFlow可以做的一小部分。 以下是一些有关TensorFlow和深入学习的更多资源:
TensorFlow.org
用Python进行深度学习的TensorFlow完整指南
用TensorFlow深入学习
数据科学:Python深度学习
结论
在这篇文章中,我们介绍了用于机器学习的TensorFlow库,为安装提供了简要的指导,介绍了TensorFlow底层核心应用接口的基本组件:张量,图形和会话,最后构建了一个神经网络模型来对真实数据集——Iris数据集进行分类。
总的来说,理解TensorFlow的编写原理可能需要一些时间,因为它是一个符号库,但是一旦熟悉了核心组件,这对构建机器学习应用程序来说是相当方便的。在这篇文章中,我们使用底层的核心应用接口来展现基本的组件,并且对模型有完全的控制,但是通常人们会使用更高级的应用接口,比如tf.estimator,甚至是外部的库,比如Keras。
英文原文:http://stackabuse.com/tensorflow-neural-network-tutorial/
译者:浙南菌





