
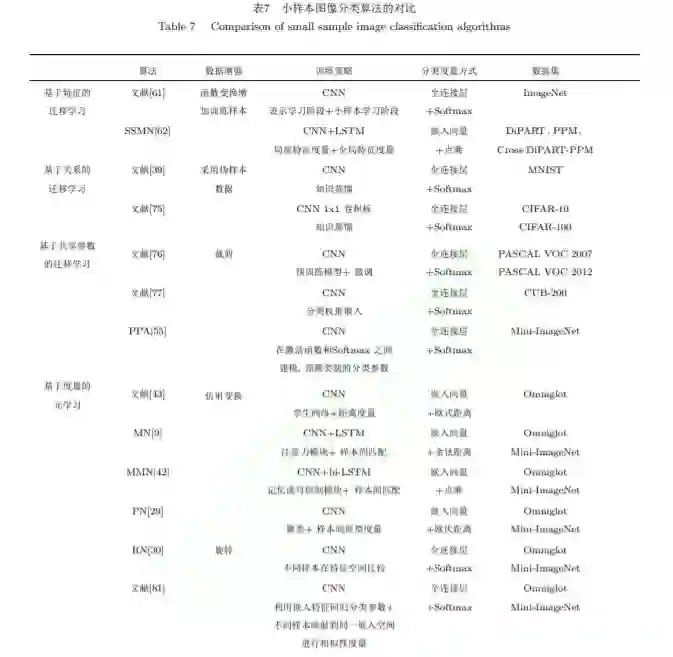
摘要:图像分类的应用场景非常广泛,很多场景下难以收集到足够多的数据来训练模型,利用小样本学习进行图像分类可解决训练数据量小的问题.本文对近年来的小样本图像分类算法进行了详细综述,根据不同的建模方式,将现有算法分为卷积神经网络模型和图神经网络模型两大类,其中基于卷积神经网络模型的算法包括四种学习范式:迁移学习、元学习、对偶学习和贝叶斯学习;基于图神经网络模型的算法原本适用于非欧几里得结构数据,但有部分学者将其应用于解决小样本下欧几里得数据的图像分类任务,有关的研究成果目前相对较少.此外,本文汇总了现有文献中出现的数据集并通过实验结果对现有算法的性能进行了比较.最后,讨论了小样本图像分类技术的难点及未来研究趋势.
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文