卷积神经网络如何进行图像识别?

在机器视觉的概念中,图像识别是指软件具有分辨图片中的人物、位置、物体、动作以及笔迹的能力。计算机可以应用机器视觉技巧,结合人工智能以及摄像机来进行图像识别。
对于人类和动物的大脑来说,识别物体是很简单的,但是同样的任务对计算机来说却是很难完成的。当我们看到一个东西像树、或者汽车、或者我们的朋友,我们在分辨他是什么之前,通常不需要下意识的去研究他。然而,对于计算机来说,辨别任何事物(可能是钟表、椅子、人或者动物)都是非常难的问题,并且找到问题解决方法的代价很高。
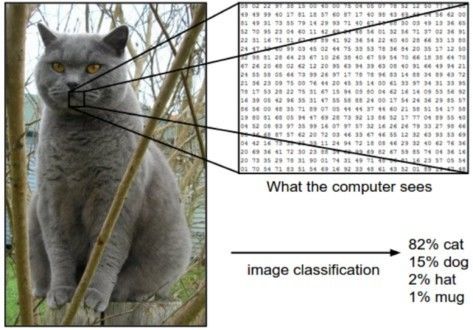
图像识别算法一般采用机器学习方法,模拟人脑进行识别的方式。根据这种方法,我们可以教会计算机分辨图像中的视觉元素。计算机依靠大型数据库,通过对数据呈现的模式进行识别,可以对图像进行理解,然后形成相关的标签和类别。
图像识别技术有许多应用。其中最常见的就是图像识别技术助力的人物照片分类。谁不想更好地根据视觉主题来管理巨大的照片库呢?小到特定的物品,大到广泛的风景。
图片识别技术赋予了照片分类应用的用户体验新感受。除了提供照片存储,应用程序也可以更进一步,为人们提供更好的发现和搜索功能。有了通过机器学习进行自动图像管理的功能,它们就可以做到这一点。在应用程序中整合的图像识别程序界面可以根据机器所鉴定的特征对图像进行分类,并且根据主题将照片分组。
图像识别的其他应用包括存储照片和视频网站、互动营销以及创意活动,社交网络的人脸和图像识别,以及具有大型视觉图像库网站的图像分类。
图像识别不是一项容易的任务,一个好的方法是将元数据应用到非结构数据上。聘请专家对音乐和电影库进行人工标注或许是一个令人生畏的艰巨任务,然而有的挑战几乎是不可能完成的,诸如教会无人驾驶汽车的导航系统将过马路的行人与各种各样的机动车分辨出来,或者将用户每天传到社交媒体上的数以百万计的视频或照片进行标注以及分类。
解决这个问题的一个方法是使用神经网络。理论上,我们可以使用传统神经网络对图像进行分析,但是实际上从计算角度来看代价很高。举个例子,一个传统的神经网络在处理一张很小的图片时(假设30x30像素)仍然需要50万个参数以及900个输入神经元。一个相当强大的机器可以运行这个网络,但是一旦图片变大了(例如500x500像素),参数以及输入的数目就会达到非常高的数量级。
神经网络应用于图像识别的另一个会出现的问题是:过拟合。简单地说,过拟合一般发生在模型过于贴合训练数据的情况下。一般而言,这会导致参数增加(进一步增加了计算成本)以及模型对于新数据的结果在总体表现中有所下降。
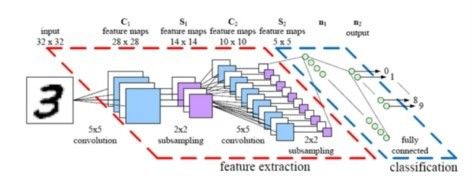
根据神经网络的构建方式,一个相对简单的改变就可以让较大的图像变得更好处理。改变的结果就是我们所见到的卷积神经网络(CNNs,ConvNets)。
神经网络的广适性是他们的优点之一,但是在处理图像时,这个优点就变成了负担。卷积神经网络对此专门进行了折衷:如果一个网络专为处理图像而设计,有些广适性需要为更可行的解决方案做出让步。
对于任意图像,像素之间的距离与其相似性有很强的关系,而卷积神经网络的设计正是利用了这一特点。这意味着,对于给定图像,两个距离较近的像素相比于距离较远的像素更为相似。然而,在普通的神经网络中,每个像素都和一个神经元相连。在这种情况下,附加的计算负荷使得网络不够精确。
卷积神经网络通过消除大量类似的不重要的连接解决了这个问题。技术上来讲,卷积神经网络通过对神经元之间的连接根据相似性进行过滤,使图像处理在计算层面可控。对于给定层,卷积神经网络不是把每个输入与每个神经元相连,而是专门限制了连接,这样任意神经元只能接受来自前一层的一小部分的输入(例如 3x3 或 5x5)。
因此,每个神经元只需要负责处理一张图像的一个特定部分。(顺便提一下,这基本就是人脑的独立皮质神经元工作的方式。每个神经元只对完整视野的一小部分进行响应)。
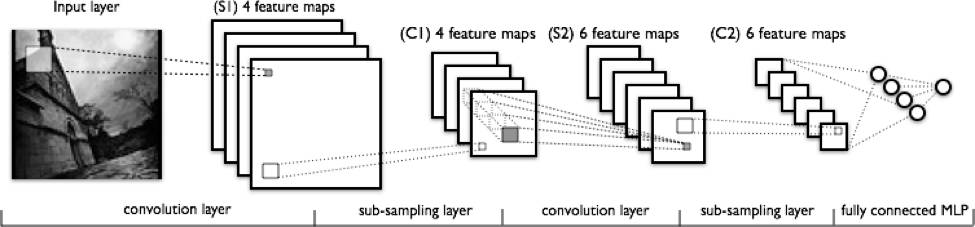
上图从左到右可以看出:
网络对输入的真实图像进行扫描提取特征。传递特征的滤波器由浅色方块表示。
激活图由堆栈形式排列,每一个对应所用的滤波器。较大的方形是要进行下采样的块。
激活图通过下采样进行压缩。
下采样后的激活图经过滤波器产生新的一组激活图。
第二次下采样——对第二组激活图进行压缩。
全连接层为每个节点的输出指定一个标签。
卷积神经网络的滤波器如何对连接根据相似性进行滤波?诀窍在于新加的两种层结构:池化层和卷积层。我们下面将步骤进行分解。用为了只完成一件事情而设计的网络实例进行介绍,即决定一张图片中是否含有一个老爷爷。
过程的第一步是卷积层,它自己本身就包含几个小步骤。
首先,我们要将包含老爷爷的图片分解为一系列有重叠的3*3的像素块。
在这之后,我们将每个像素块输入一个简单的、单层的神经网路,保持权重不变。这一步将像素块集转化成一个矩阵。只要我们保持每块像素块都比较小(这里是3x3),处理它们所需的网络也可以保持可控以及小型。
下一步,输出值会被排成矩阵,以数据形式表示照片中每个区域的内容,不同轴分别代表颜色、宽度、和高度通道。对于每一个图像块,都有一个3x3x3的表示。(如果要处理视频,可以加入第四维度代表时间)。
接下来是池化层。池化层对这些3或4维的矩阵在空间维度上进行下采样。处理结果是池化阵列,其中只包含重要部分图像,并且丢弃了其他部分,这样一来最小化了计算成本,同时也能避免过拟合问题。
经过下采样的矩阵作为全连接层的输入。由于经过了池化和卷积操作,输入的尺寸被大幅减小,我们现在有了正常网络能处理的,同时能保持数据最重要特性的东西。最后一步的输出代表系统对于图片中有老爷爷这一判断的确信度。
在实际应用中,卷积神经网络的工作过程很复杂,包括大量的隐藏、池化和卷积层。除此之外,真实的卷积神经网络一般会涉及上百甚至上千个标签,而不只是样例中的一个。
从头开始构建一个卷积神经网络是很费时费力的工作。目前已经有了许多API能够实现关于卷积神经网络的想法,而不需要工程师去了解机器学习的原理或者计算机视觉的专业知识。
Google云视觉是使用REST API搭建的视觉识别API。它基于开源的TensorFlow框架。它可以检测到独立的人脸或物体,并且包含十分全面的标签集。
IBM Watson 视觉识别是Waston Developer Cloud服务的一部分,并且自带大量内置类别,但它实际是为训练基于你提供图片的自定义类别而打造的。同时,和Google云视觉一样,它也提供了大量花哨的特性,包括NSFW以及OCR检测。
Clarif.ai也是一个使用REST API的初创图像识别服务。关于Clarif.ai有趣的一点是,它自带的一系列模块可以用于修改算法,将其应用到特定的主题上,例如食物、旅游和结婚。
尽管上述的API适合一些一般的应用,但最好还是针对特定问题开发一个自定义的解决方案。幸运的是,大量可用的库解决了优化和计算方面的问题,开发人员和数据科学家可以只关注训练模型,这样一来他们的工作便轻松了一些。这些库包括Theano、 Torch、 DeepLearning4J以及TensorFlow,已成功地运用在各种各样的应用程序中。
卷积神经网络的有趣小应用
自动为无声电影添加声音
要为无声电影添加匹配的声音,系统必须在这个任务中自动合成声音。该系统使用上千个视频样例进行训练,视频带有鼓棍敲打不同表面产生的不同声音。一个深度学习模型将视频的帧和预录的声音建立联系,然后选择能够完美匹配场景的音频进行播放。系统会通过图灵测试进行评估,让人来决定那个视频是合成的,哪个是真实的声音。这是卷积神经网络和LSTM循环神经网络的一个很潮的应用。
视频地址如下:
https://www.youtube.com/watch?v=0FW99AQmMc8视觉指引声音 (Visually-Indicated Sounds)
作者LinkedIn主页:
https://www.linkedin.com/in/savaram-ravindra-48064641/
联系方式:
savaramravindra4@gmail.com
英文原文:
http://www.kdnuggets.com/2017/08/convolutional-neural-networks-image-recognition.html





