【泡泡图灵智库】基于表面法线的稠密单目重建(ICRA)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Dense Monocular Reconstruction using Surface Normals
作者:Chamara Saroj Weerasekera, Yasir Latif, Ravi Garg, Ian Reid
来源:ICRA2017
编译:黄文超
审核:刘小亮
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——基于表面法线的稠密单目重建,该文章发表于ICRA2017 。
本文提出了一个使用移动单目相机进行稠密3D场景重建的高效的框架。完全基于几何方法的vSLAM已经被证明能够准确地跟踪移动摄像机的位姿并同时实时地构建环境地图。然而,大多数算法建成的3D地图太稀疏,无法实际应用。生成的地图中的缺失点主要对应于输入图像中缺少纹理的区域,而稠密的建图系统通常依赖于手工制作的先验特征,如分段平面性或分段平滑的深度。这些先验并不总能提供足够的场景理解来准确填充地图。另一方面,卷积神经网络(CNN)在从图像中提取高层次的信息和递归像素的表面法线、语义甚至深度方面取得了巨大的成功。在这项工作中,作者利用到了深层CNN以表面法线先验形式学习到的高层次的场景上下文信息。作者指特别出,使用表面法线先验比更弱的平滑先验可以有更好的重建效果。
主要贡献
1、 使用神经网络学习得到的强先验来建立 1) 最小化光度误差; 2) 与单视图法线预测一致的地图。
2、 详细、量化地评估了本文提出的算法与传统手动平滑算法和单纯基于学习的方法,并且指出本文的算法解决了上述两种算法的不足。
算法流程
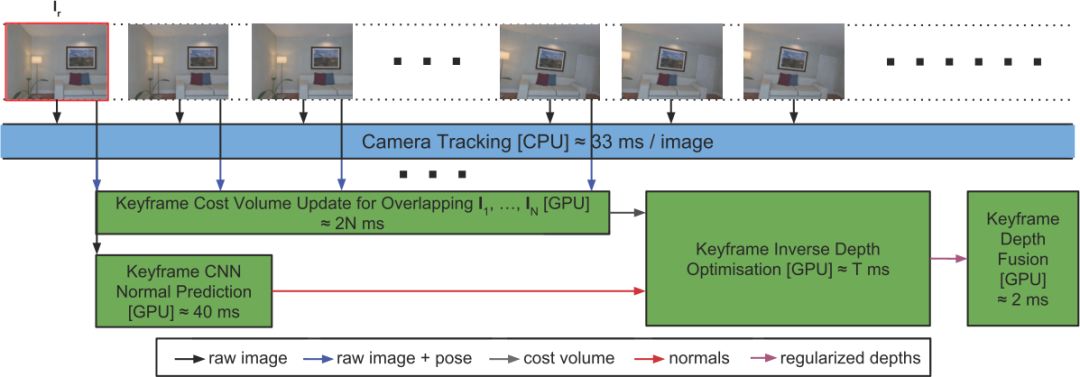
图3 算法整体框架
算法流程图如图3,图中所描述的步骤对每一个关键帧 Ir 都重复执行。其中:相机跟踪在主CPU线程里运行,误差量的更新和CNN法线预测都在GPU上运行,且设法与主线程同步。优化和深度融合随后运行,也与主线程同步。
1、相机位姿跟踪和帧选择
这部分的工作使用了ORB-SLAM的框架来获得精确的基于特征的相机追踪,并且提供用于计算光度误差的变换矩阵。关键帧 Ir 的选择和重叠对数据的可靠性有很大影响,在关键帧前后设定一个帧窗口,过去的帧由ORB-SLAM提供,未来的帧如果设为 0 代表即时重建,增大窗口中的帧数会导致建图延时也增大。
2、 误差量计算和表面法线预测
误差的计算方法与Dtam一致,将深度估计作为能量最小化问题,能量函数由数据项和正则项组成,如式(1)。
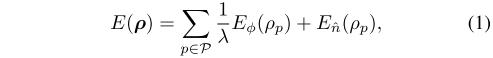
Eφ是计算光度误差的数据项,Eˆn是能量,用于在优化中惩罚不一致的逆深度。
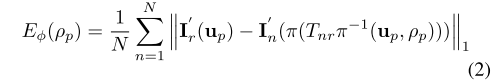
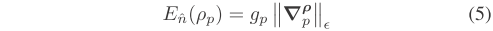
为了直接从关键帧回归计算表面的法向量,本文作者使用了多尺度的CNN模型,尺度为 1 是的模型为基于VGG-16的卷积层,随后是两个全连接层,这主要是比较粗糙地提取全局特征。随后尺度 2 和 3 由全卷积层组成,在更精细的分辨率层次提取更多局部特征。尺度为 3 的网络同时还为输入的关键帧回归出一个表面法线图和深度图。
3、逆深度优化和深度融合
优化算法如下

最后一步,优化得到的深度图被融合到全局的模型中。这一步使用的方法是开源的InfiniTAM系统。
主要结果
本文作者在几个视频数据集中大量的序列上做了测试,使用的计算机包含Intel i7 4790 CPU和一块Nvidia GTX 980 4GB GPU。
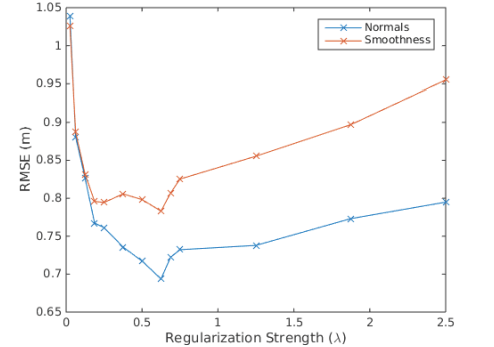
图4 关键帧重建平均RMS误差(m) 关于正则化强度的变化
可以看出基于法线的方法的误差一直较低

图6 NYU数据集 'bedroom 0048'上的定性结果比较
左上图为输入的图像。最右侧的图片分别为使用平滑正则化方法(上)和基于关键帧平面法线(下)的重建结果,可以看出墙和地面的重建效果的改善。
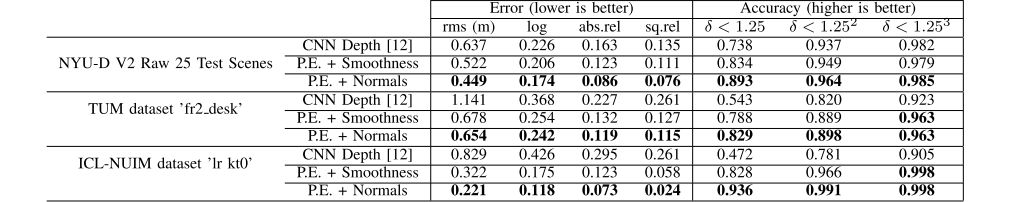
表1 各数据集测试序列的量化比较结果
P.E.代表光度误差,
(此处的结果基于图4中给出的最优正则化强度)

Abstract
This paper presents an efficient framework for dense 3D scene reconstruction using input from a moving monocular camera. Visual SLAM (Simultaneous Localisation and Mapping) approaches based solely on geometric methods have proven to be quite capable of accurately tracking the pose of a moving camera and simultaneously building a map of the environment in real-time. However, most of them suffer from the 3D map being too sparse for practical use. The missing points in the generated map correspond mainly to areas lacking texture in the input images, and dense mapping systems often rely on hand-crafted priors like piecewise-planarity or piecewise-smooth depth. These priors do not always provide the required level of scene understanding to accurately fill the map. On the other hand, Convolutional Neural Networks (CNNs) have had great success in extracting high-level information from images and regressing pixel-wise surface normals, semantics, and even depth. In this work we leverage this high-level scene context learned by a deep CNN in the form of a surface normal prior. We show, in particular, that using the surface normal prior leads to better reconstructions than the weaker smoothness prior.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



