自动深度学习是关注的研究问题之一,来自悉尼科技大学董宣毅等研究者发布了《自动深度学习》论文,65页pdf316篇文献 阐述了AutoDL的发展现状
![]()
深度学习(DL)已经被证明是一种非常有效的方法,可以在不同的环境下开发模型,包括视觉感知、语音识别和机器翻译。然而,应用DL的端到端过程并不简单。它需要处理问题形式化和上下文理解、数据工程、模型开发、部署、持续监视和维护等等。此外,就知识和互动而言,每个步骤都严重依赖于人类,这阻碍了DL的进一步发展和普遍化。因此,为了应对这些问题,在过去几年出现了一个新的领域: 自动深度学习(AutoDL)。这一努力寻求最小化人类参与的需要,并以其在神经架构搜索(NAS)方面的成就而闻名,这是几个综述的焦点话题。也就是说,NAS并不是AutoDL的全部和最终目标。因此,本文采用了一个全面的视角,在整个原型DL工作流中检查自动化方面的研究工作。在这样做的同时,这项工作还提出了一套全面的10个标准,通过这些标准来评估现在工作和更广泛的研究领域的现有工作。这些标准是: 新颖性、解决方案质量、效率、稳定性、可解释性、复现性、工程质量、可扩展性、通用性和生态友好性。因此,最终,本综述提供了一个对本世纪20年代初AutoDL的评估概述,确定了未来可能存在的进步机会。
https://arxiv.org/abs/2112.09245
在对人工智能(AI)的追求中,历史可能会将2010年代早期视为一个里程碑,以无与伦比的强度刺激研发的新时代。在这些改革的岁月里,机器学习(ML)领域目睹了优先级和方法的转变。两种方法脱颖而出:
这两种方法最终将不可避免地融合在一起,融合到自动化深度学习(AutoDL)这一新颖的学科中。
![]()
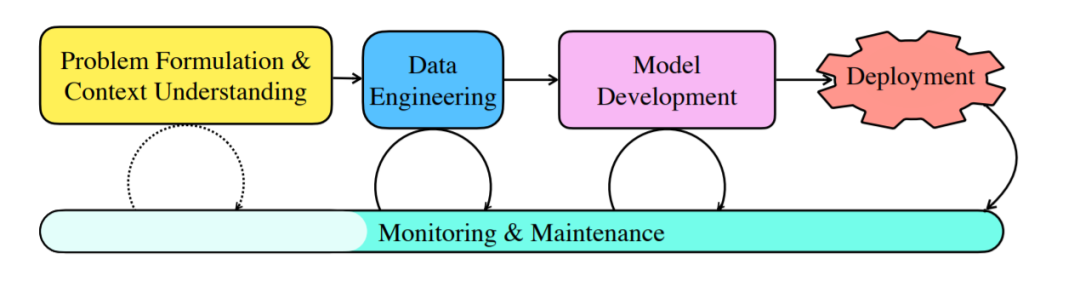
端到端DL工作流示意图,即应用DL解决问题所涉及的过程。传统上,该工作流的每个部分都需要人工决策,例如分析问题上下文、定义ML任务、设计模型、手动调整超参数、选择训练策略等。
无可否认,虽然AutoDL在2021年是一个“热门话题”,但这一热潮背后的基础可以追溯到几十年前。
ML本身的概念[187]建立于20世纪50年代,旨在通过自动数据驱动算法调整理想函数的数学模型。随着时间的推移,到21世纪初,大量的ML模型和算法将在实际场景中得到应用,支持向量机和其他内核方法尤其受欢迎[113]。神经元与人类智能有着千丝万缕的联系,神经元的概念似乎一直是ML的一个显而易见的基础。早在20世纪40年代[185],它们在多层排列中的代表性就已经在20世纪60年代后期显现出来,以protoDL“数据处理的群体方法”(GMDH)为例[125]。因此,随着人工智能冬天的到来,各种类型的神经层和架构的变化被提出和采用。这些包括循环结构[114,166],卷积和下采样层[85],自动编码器层次[15],记忆机制[208]和门结构[111]。因此,历史上人工神经网络(ANN)的成功是不可否认的,包括手写识别[154]、时间序列预测[269]、视频检索[131,289]、有丝分裂检测[46]等。然而,深度神经网络(DNN)的优势,包括其作为通用逼近器的地位[115],被其复杂性的笨拙性质所抵消。例如,虽然BackPropagation在20世纪70年代被建立为反向自动微分[165],但这种DNN训练技术直到最近才普遍可行。因此,DL在2010年代的主导地位上升[153,234],既是大数据基础设施和硬件加速(特别是图形处理器)的结果,也是任何一个理论进步的结果。
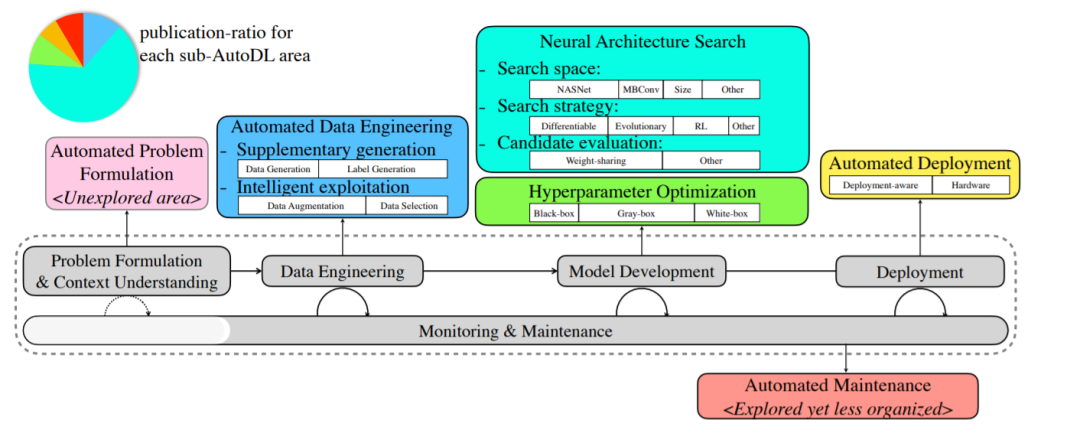
虽然在这个领域有许多综述[70,79,219,274,298],大多数集中在AutoDL的一两个子领域的深度分析。相比之下,我们研究了整个DL工作流(如果存在的话)的研究,并试图评估到2021年,AutoDL目前的角色是什么,以及它的发展方向是什么。我们首先在第2节提供AutoDL的概述,介绍几个基本概念。然后,根据DL工作流的启发,将主要的AutoDL研究划分为几个部分,如图2所示,我们探索自动化:任务管理(第3节)、数据准备(第4节)、神经架构设计(第5节)、超参数选择(第6节)、模型部署(第7节)和在线维护(第8节)。
![]()
AutoDL研究分解示意图,将调研论文归于DL工作流的不同阶段,然后进一步细分。饼状图表示所有工作流阶段中出版物的比例,而白色堆叠条形图表示每个子类别中的比例。所有统计数据都来自Awesome-AutoDL项目:https://github.com/D-X-Y/Awesome-AutoDL。
DL任务通常从定义感兴趣的问题开始。这主要涉及到将人类的需求转化为计算机可操作的表示,例如,从像素映射到分类类的预测函数的搜索,其中稀疏标记可能需要半监督学习技术。一旦问题被定义,下一步通常是定义未来DNN模型的输入空间。一般假设输入数据应该是独立的和相同分布的(i.i.d),数据收集和组织的策略需要仔细考虑。当对原始数据进行智能预处理时,神经网络的训练效果也会更好,而且有很多方法可以做到这一点。例如,主成分分析(PCA)可用于改变高维数据的基础,即具有许多特征的实例,从而使数据方差沿着最小的维数最大化; 随后的投影消除了这些所谓的主分量以外的轴,以最小的信息损失实现了降维[116,202]。预处理还可以包括将分类数据编码为整数或一个热门向量[3],以及通过标准化、标准化或幂变换[26]进行特征缩放。
最终,是时候构建DL模型了。在标准表述中,该模型是一个具有多个神经元层的DNN,并使用多种方式将这些神经元层连接在一起,例如使用全连接、局部卷积连接,甚至使用残差神经网络(ResNet)的直接层跳过[105]。因此,需要选择神经结构和训练算法;它们分别与通常所说的“模型/架构超参数”和“算法/训练超参数”相关。然后,DL模型根据输入数据进行训练,从而调整DL模型的权重以最佳地表示理想的函数。从历史上看,有很多关于如何做到这一点的方法,从GMDH[125]到无监督的赢家通吃方法[34,84,151]。然而,反向传播已成为现代全连接多层神经网络的主要训练策略。最初的推导和实现[165]分别可以追溯到20世纪60年代和70年代,它在20世纪80年代得到普及[152,225,273],并有效地用于训练多层感知器(MLPs),尽管在硬件的进步使大规模问题的普遍使用成为可能之前还需要几十年。值得注意的是,通过反向传播的梯度下降的普通形式在速度、收敛性、泛化等方面存在一些缺点。在过去几十年里,已经提出了许多升级方法,如随机梯度下降(SGD)、动量SGD[225]、弹性传播[221]和自适应估计[141]。神经结构搜索(Neural Architecture Search, NAS)也成为DL模型构建的关键研究课题之一;见第五节。
一旦DL模型被选择和训练,在典型的DL工作流中还有更多的工作要做。在实际应用中,需要部署DL模型,有时在定制设备和硬件上。在大多数情况下,部署的DL模型在结构和网络权值上都与训练的DL模型相同。在某些资源受限的情况下,必须通过剪枝、量化或稀疏正则化对模型进行压缩[59、100、101、167],然后才能将其投入实际生产。此外,还存在一个从不断变化的环境中学习和适应的问题,即必须使用AutoDL方法来处理连续流、非平稳的数据。虽然这个问题已经在更广泛的ML领域研究了很多年[86,136,311],甚至开始在完全自动化和自主ML系统的背景下考虑和解决[14,140],但它仍然是DL的一个主要挑战。由于这个问题出现在许多现实世界的场景中,例如股票市场[7,292]和消费者推荐系统[106,220],在这些场景中,DNN是例行部署的,因此需要强大的适应性能力来保持这些模型更新。
![]()
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
商务、投稿、技术等合作:请加微信助手:Quan_ABT, 或发邮件到bd@zhuanzhi.ai
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取7万+AI主题干货知识资料!