西电最新《场景图生成SGG》全面综述论文,阐述总结138项工作
西安电子科技大学最新场景图生成综述论文
近年来,深度学习技术在通用目标检测领域取得了显著的突破,并催生了许多场景理解任务。场景图因其强大的语义表达能力和在场景理解中的应用而成为研究的热点。场景图生成(Scene Graph Generation, SGG)是指将图像自动映射为语义结构的场景图,需要正确标注被检测对象及其关系。虽然这是一个具有挑战性的任务,但社区已经提出了许多SGG方法,并取得了良好的效果。在本文中,我们提供了一个全面的综述,在这一领域的最新成就带来了深度学习技术。本文综述了138个具有代表性的研究成果,并从特征提取和融合的角度系统总结了现有的基于图像的SGG方法。我们试图将现有的视觉关系检测方法进行连接和系统化,以全面的方式总结和解释SGG的机制和策略。最后,我们对目前存在的问题和未来的研究方向进行了深入的讨论,完成了本次综述。这一综述将有助于读者更好地了解目前的研究现状和思路。
https://www.zhuanzhi.ai/paper/d72c999bf8a19c1381032186bed68e48
计算机视觉(CV)的最终目标是构建智能系统,能够像人类一样从数字图像、视频或其他形式中提取有价值的信息。在过去的几十年里,机器学习(ML)为CV的发展做出了巨大的贡献。受人类能够轻松解读和理解视觉场景能力的启发,视觉场景理解一直被推崇为CV的圣杯,并已经引起了研究界的广泛关注。
视觉场景理解包括许多子任务,一般可分为识别和应用两部分。这些识别任务可以在几个语义级别上进行描述。早期的大部分作品主要集中在图像分类上,只给图像分配了一个标签,例如一只猫或一辆车的图像,并进一步分配了多个标注,而没有定位每个标注在图像中的位置,即[38]。大量的神经网络模型已经出现,甚至在图像分类任务[27],[29],[33],[34]中达到了接近人类的性能。此外,其他一些复杂的任务,如像素级的语义分割,对象检测和实例级的实例分割,都建议将图像分解为前景对象和背景杂波。像素级任务的目标是将图像(或多个)的每个像素分类到一个实例中,其中每个实例(或类别)对应于一个类[37]。实例级任务的重点是在给定的场景中检测和识别单个的对象,以及分别用包围框或分割蒙版勾画一个对象。最近提出的一种名为Panoptic Segmentation (PS)的方法同时考虑了逐像素类和实例标签[32]。随着深度神经网络(DNN)的发展,以对象为中心的任务和基于[17]、[19]、[21]、[22]、[23]模型的各种商业化应用取得了重要突破。然而,场景理解超出了对象的定位。更高层次的任务侧重于探索对象之间丰富的语义关系,以及对象与周围环境的交互,如视觉关系检测[15]、[24]、[26]、[41]和人-物交互(HOI)[14]、[16]、[20]。这些任务同样重要,也更具挑战性。在一定程度上,它们的发展取决于个体实例识别技术的性能。同时,对图像内容进行更深层次的语义理解也有助于完成视觉识别任务[2],[6],[36],[39],[120]。Divvala等人[40]研究了各种形式的上下文模型,它们可以提高以物体为中心的识别任务的准确性。近年来,研究者们将计算机视觉与自然语言处理(NLP)相结合,提出了一些先进的研究方向,如图像描述、视觉问答(VQA)、视觉对话等。这些视觉和语言主题需要对我们的视觉世界有丰富的理解,并提供智能系统的各种应用场景。
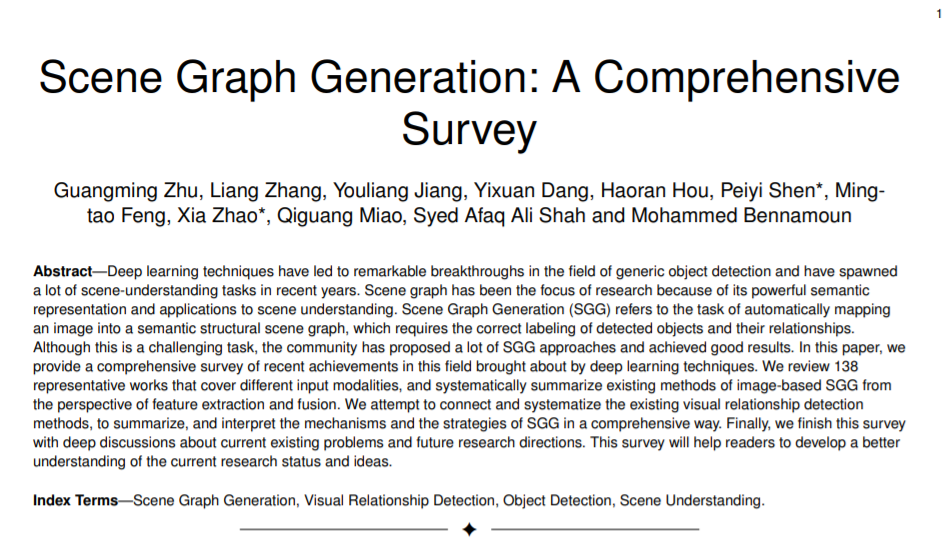
图1 一个场景图结构的可视化说明和一些应用。场景图生成模型以图像为输入,生成视觉基准的场景图。图像描述可以直接从场景图生成。与此相反,图像生成模型通过从给定的句子或场景图生成逼真的图像来逆过程。引用表达式(REF)标记输入图像中与给定表达式对应的区域,该区域与表达式映射场景图的同一子图。基于场景图的图像检索以查询为输入,将检索视为场景图匹配问题。对于Visual Question answer (VQA)任务,答案有时可以直接在场景图中找到,即使对于更复杂的视觉推理,场景图也很有帮助。
尽管在各个层次的场景理解方面已经取得了长足的进步,但还有很长的路要走。信息的整体感知和有效表达仍然是瓶颈。正如之前的一系列作品[1],[44],[191]所指出的,构建一种高效的、能够捕获全面语义知识的结构化表示是深入理解视觉场景的关键一步。这种表征不仅可以为基本的识别挑战提供上下文线索,也为高级智力视觉任务提供了一个有前途的替代方案。场景图由Johnson et al.[1]提出,是一种基于特定场景中对象实例的可视化图形,其中节点对应于对象边界框及其对象类别,边表示其成对关系。
由于与图像特征相比,场景图具有结构化的抽象和更大的语义表达能力,因此场景图具有处理和提高其他视觉任务的本能潜力。如图1所示,场景图将图像解析为一个简单而有意义的结构,是视觉场景与文本描述之间的桥梁。许多结合视觉和语言的任务都可以通过场景图来处理,包括图像描述[3]、[12]、[18]、视觉问题回答[4]、[5]、基于内容的图像检索CBIR、[7]、图像生成[8]、[9]和参考表达理解[35]。有些任务将图像作为输入,并将其解析为场景图,然后生成合理的文本作为输出。其他任务则从文本描述中提取场景图,然后生成逼真的图像或检索相应的视觉场景。
我们涵盖了几乎所有与该领域相关的当代文献,并对138篇有关场景图生成的论文进行了全面的综述。这些论文按输入模式(即图像、视频和三维网格)进行分类。
从全局的角度提出了二维场景图生成的通用框架,并从特征提取和更新的角度对这些方法进行了分析。
我们对场景图生成的各个方面进行了深入的分析,包括生成框架、对象和关系特征表示、输入模式、训练
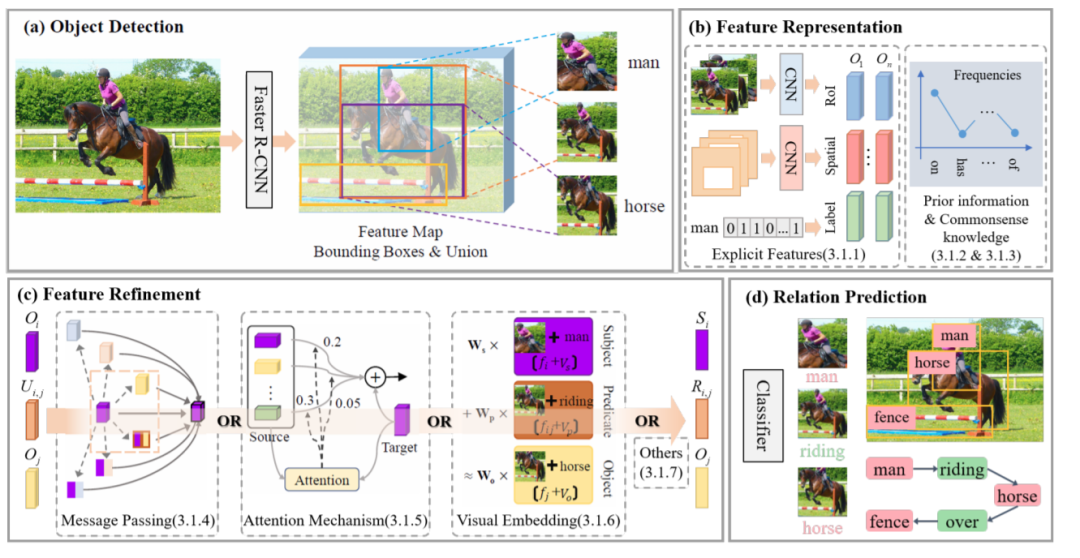
二维通用场景图生成流程框架
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SGG” 就可以获取《西电最新《场景图生成SGG》全面综述论文,阐述总结138项工作》专知下载链接


