【干货】AutoML自动机器学习:最新进展综述
【导读】自动机器学习(Automated Machine Learning)现在已经成为了学术界和工业界的热点。本文为大家带来是香港浸会大学计算机科学系Xin He等学者关于自动机器学习的最新进展综述,文章着重介绍了两个方面:一是自动机器学习的pipeline过程总结,主要包括数据准备(Data Preparation)、特征工程(Feature Engineering)、模型生成(Model Generation)和模型评估(Model Evaluation);二是细致地总结和比较各种主流的神经架构搜索算法(Neural Architecture Search algorithm, NAS),现有主流的NAS算法有四种类型:随机搜索(Random Search, RS)、强化学习(Reinforcement Learning, RL)、进化算法(Evolutionary Algorithm, EA)和基于梯度下降(Gradient Descent, GD)的算法。
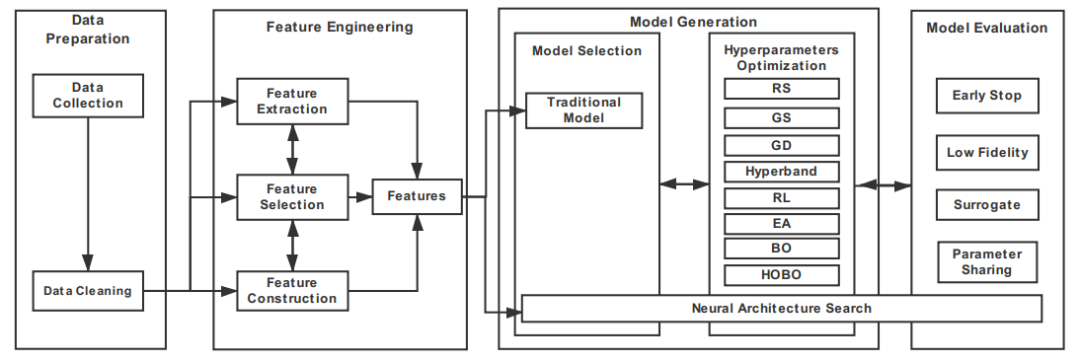
AutoML Pipeline 框架图
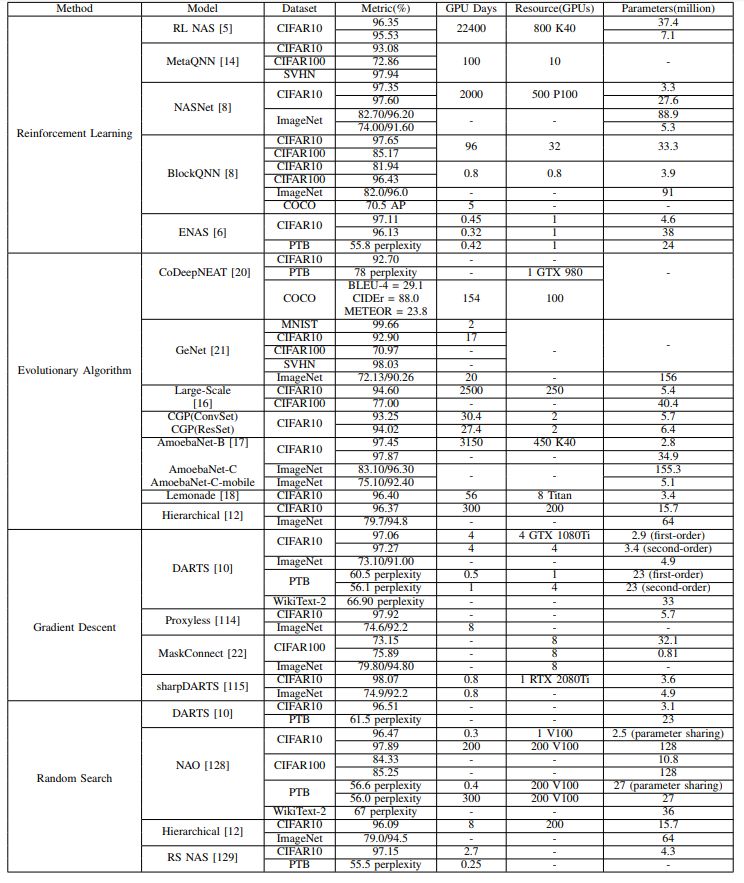
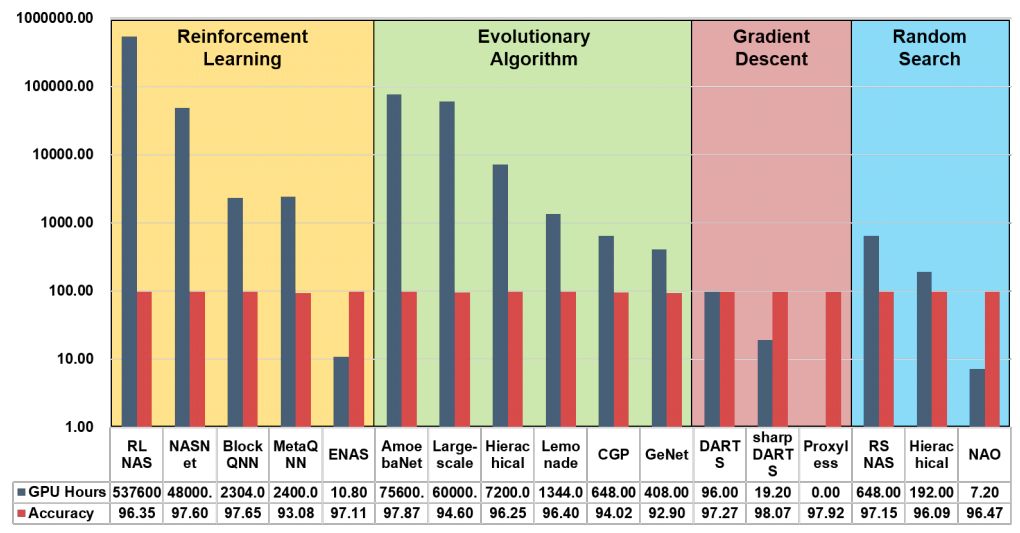
主流NAS算法性能和效果比较
原文链接:
请关注专知公众号(点击上方蓝色专知关注)
后台回复“AutoML最新进展综述” 就可以获取AutoML论文下载链接~
自动机器学习:最新进展综述

随着深度学习在AI方面的广泛应用,如分类与目标检测、语言建模和推荐系统等,深度学习渗透到我们生活的方方面面,为我们带来了极大的便利。然而,为特定任务建立高质量深度学习系统的过程不仅耗时,而且需要大量资源并依赖于人类专业知识,这阻碍了工业界和学术界的深度学习的发展。
为了解决时间和资源成本的问题,使机器学习的整个流水线过程能够自动化的新想法应运而生,即自动机器学习(AutoML)。AutoML有各种定义。例如,根据维基百科,“AutoML是自动化端到端流程的过程,应用适当的数据预处理,特征工程,模型选择和模型评估来解决特定任务”。又比如,AutoML被定义为自动化和机器学习的结合。换句话说,AutoML可以自动构建具有有限计算预算的机器学习Pipline。
越来越多关于AutoML的研究在逐渐展开,其中大部分的研究主要关注神经架构搜索算法(Neural Architecture Search algorithm, NAS)。NAS算法旨在通过从预定义的搜索空间中选择和组合不同的基本组件来生成健壮且性能良好的神经架构。本文将从两个方面介绍ANS算法,一是模型结构,二是超参优化(Hyperparameter Optimization, HPO)。
-
数据收集(Data Collection) : 对于深度学习任务,我们一般首选公开的大型数据集,如CIFAR10 & CIFAR100等等,但是对于一些特定的任务,很难找到合适的数据集,这里我们有两类方法解决这个问题。 一是数据合成(Data Synthesis); 二是数据搜索( Data Searching )。这些都可以让你收集到合适的数据集。 -
数据清理(Data Cleaning) : 在进入特征生成之前,必须预处理原始数据,因为存在许多类型的数据错误(例如,冗余,不完整或不正确的数据)。 被广泛使用的数据清理操作包括标准化,缩放,定量特征二值化,one-hot编码定性特征,用平均值填充缺失值等等。
A.特征选择(Feature Selection)
特征选择基本流程
B.特征构造(Feature Construction)
C.特征提取(Feature Extraction)
A.模型结构(Model Structure)
整体结构(Entire structure):第一种直观的方法是生成一个完整的链结构神经网络,类似于传统的神经网络结构。但是这类模型的缺点也是明显的,耗时耗力,参数搜索空间等等。
基于单元的结构(Cell-based structure):为了解决Entire structure的缺点,出现了Cell-based structure,该首先构建单元格结构然后堆叠预定义数量的已发现单元格,以类似于链式结构的方式生成整个架构。
层次结构(Hierarchical structure):层次结构类似于基于单元的结构,但主要区别在于生成单元的方式。对于分层结构,模型存在很多级别,每个级别具有固定数量的单元格。通过迭代地合并较低级别的单元来生成较高级别的单元。
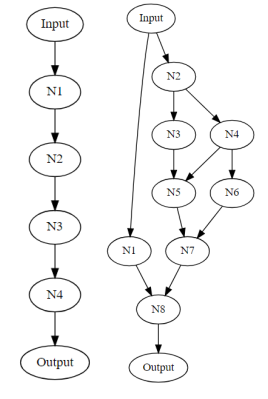
整体结构(Entire structure)
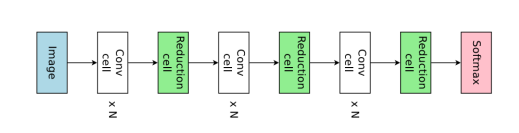
基于单元的结构(Cell-based structure)
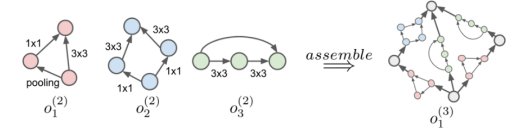
层次结构(Hierarchical structure)
B.参数优化(HyperParameter Optimization)
网格和随机搜索(Grid & Random Search):网格搜索将可能的超参数空间划分为规则的间隔(网格),然后为网格上的所有值训练模型,并选择性能最佳的一个,而随机搜索,顾名思义,随机选择一组超参数。
强化学习(Reinforcement Learning):基于RL的算法由两部分组成。一是控制器,它是一个RNN,用于在不同的时期生成不同的子网络;二是奖励网络,用于训练和评估生成的子网络并使用 更新RNN控制器的奖励(例如准确性)。
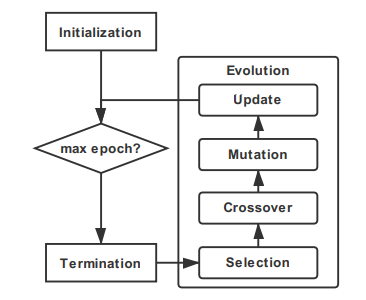
进化算法(Evolutionary Algorithm):进化算法(EA)是一种基于人口的通用元启发式优化算法,它从生物进化中获取灵感。与传统的优化算法(如基于微积分的方法和穷举方法)相比,进化算法是一种成熟的全局优化方法,具有很高的鲁棒性和广泛的适用性。进化算法主要由四个部分组成选择,交叉,变异和更新。
贝叶斯优化(Bayesian Optimization):贝叶斯优化(BO)是一种建立目标函数概率模型的算法,然后使用该模型选择最有希望的超参数,最后在真实目标函数上评估所选择的超参数。因此,贝叶斯优化可以通过跟踪过去的评估结果来迭代地更新概率模型。
梯度下降(Gradient Descent):上面介绍的搜索算法都可以自动生成模型体系结构,同时以离散的方式搜索超参数,但是HPO的过程被视为黑盒优化问题,这就导致模型需要迭代更新许多参数,因此也就需要大量的时间和计算资源。基于梯度下降(GD)的方法可以减少搜索超参数所花费的时间。
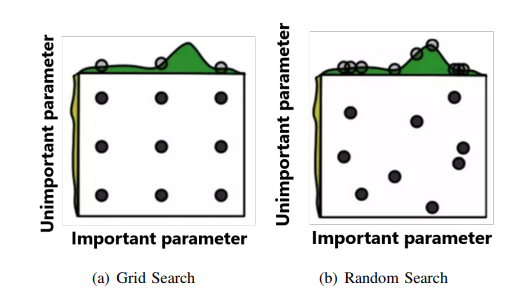
网格搜索和随机搜索
A.Low fidelity
B.迁移学习(Transfer learning)
C.代理(Surrogate)
D.Early stopping
完善AutoML Pipeline
可解释性(Interpretability)
可复现性(Reproducibility)
灵活的配置方案(Flexible Encoding Scheme)
扩展领域(More Area)
Lifelong Learning
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



