
摘要
作为一种比传统机器学习方法更有效的训练框架,元学习获得了广泛的欢迎。然而,在多模态任务等复杂任务分布中,其泛化能力尚未得到深入研究。近年来,基于多模态的元学习出现了一些研究。本综述从方法论和应用方面提供了基于多模态的元学习景观的全面概述。我们首先对元学习和多模态的定义进行了形式化的界定,并提出了这一新兴领域的研究挑战,如何丰富少样本或零样本情况下的输入,以及如何将模型泛化到新的任务中。然后我们提出了一个新的分类系统,系统地讨论了结合多模态任务的典型元学习算法。我们对相关论文的贡献进行了调研,并对其进行了分类总结。最后,提出了该领域的研究方向。
https://www.zhuanzhi.ai/paper/3cf8fdad89ed44f7ea803ce6e0ab21b5
引言
深度学习方法在语音、语言和视觉领域取得了显著进展[1,2,3]。然而,这些方法的性能严重依赖于大量标记数据的可用性,而在大多数应用中,获取这些数据可能不切实际或成本高昂。仅使用有限的标记数据往往会导致过拟合问题,导致泛化到新数据[4]或完全不同的分布的不确定性。另一方面,人类学习过程中使用的“学会学习”机制[5]使我们能够从很少的样本[6]中快速学习新的概念。已有证据表明,通过结合先验知识和情境,人类可以在有限情景下获得多个先验任务的经验,在有限情景下,习得的抽象经验被一般化,以提高未来对新概念的学习表现。受此启发,提出了一种名为元学习(meta-learning)的计算范式[7,8],用来模拟人类学习广义任务经验的能力,旨在让机器从类似任务中获取先验知识,并快速适应新任务。通过在动态选择中提取跨领域任务目标,元学习过程比传统机器学习模型更具数据效率[9,10]。
由于元学习能够泛化到新的任务,我们的目的是了解元学习如何发挥作用,当任务更复杂时,例如,数据源不再是单模态的,或原始模态中的数据是有限的。最近的研究集中在将元学习框架应用于复杂任务的分配上[11,12],但仅限于单一的模态。特别是,在多个应用[7]、学习优化步骤[13]的先验知识、数据嵌入[14,15]或模型结构[16]的多任务和单任务场景中,元学习已经被证明是成功的。然而,在异构任务模态下,如何巧妙地利用元学习给研究人员带来了独特的挑战。要在额外模态的帮助下从这些任务中学习新概念,示例应该以成对或多种方式提供,其中每个示例包含同一概念的两个或多个项目,但在不同的模态。
首先在图像分类的零样本学习(ZSL) /广义零样本学习(GSZL)领域探讨了不同模态的异质特征。语义模式被认为在模型训练中提供强大的先验知识和辅助视觉模式。为了更好地将知识从可见的类迁移到不可见的类,基于元的算法被广泛引入来捕获配对模态之间的属性关系。然而,训练过程大多将一个模态视为主要模态,并通过添加另一个模态来利用额外的信息。它不涉及在真实的复杂情景中对多种模态的分析,如未配对的模态、缺失的模态以及模态之间的关联。因此,一些研究进一步将元学习方法应用于由其他模态构成的任务。具体来说,当不同任务的模态来自不同的数据分布,或者不同任务的模态被遗漏或不平衡时,通过充分利用元学习背景下的多模态数据,可以将不同模式的优势整合到问题中,从而提高绩效。另一方面,元学习本身的训练框架有助于提高原多模态学习者在新任务中的泛化能力。虽然对这两个概念的跨学科研究听起来很有前景,但目前的研究大多将元学习算法和多模态学习算法分开进行总结,导致多模态与元学习结合的研究存在差距。
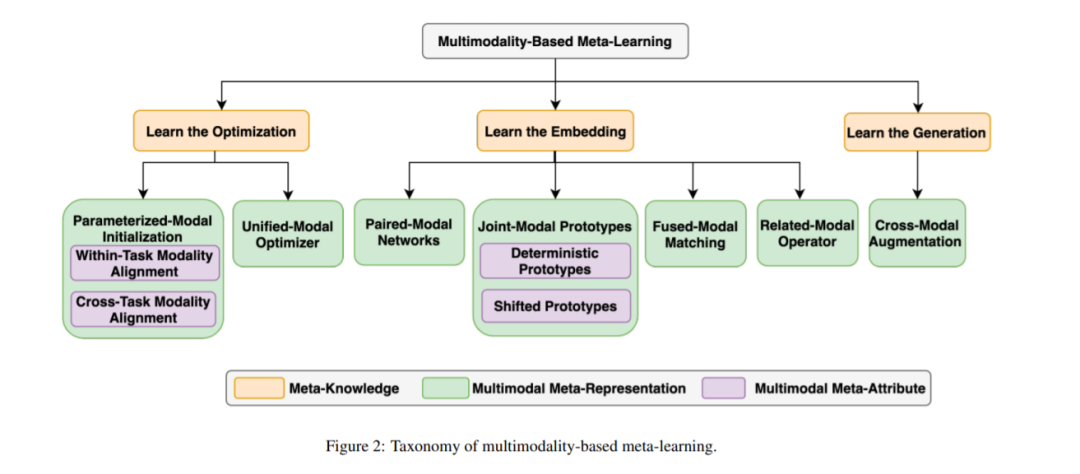
最后,我们希望在本次综述中对基于多模态的元学习算法进行系统而全面的研究。我们旨在为不同的方法提供直观的解释,并有助于:
识别将元学习算法应用于多模态任务的挑战; 提出一个新的分类,并为每个类别提供深刻的分析; 总结解决不同挑战的具体贡献,包括其方法和与其他方法的区别; 强调当前的研究趋势和未来可能的方向。
本综述的其余部分组织如下。在第二节中,我们首先对元学习和多模态的定义进行了形式化界定,然后给出了基于多模态的元学习挑战的总体范式。然后我们在第3节提出了一个基于元学习算法可以学习的先验知识的新分类。我们分别在第4节、第5节和第6节对如何使原始元学习方法适应多模态数据的相关研究进行了考察,在第7节对这些工作进行了总结。最后,我们总结了目前的研究趋势在第8节和可能的方向,未来的工作在第9节。

