BAT机器学习面试题1000题(361~365题)

点击上方蓝字关注


BAT机器学习面试题1000题(361~365题)
361题
简单介绍下logistics回归?
答案
点击下方空白处获得答案
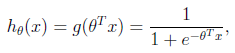
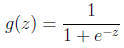
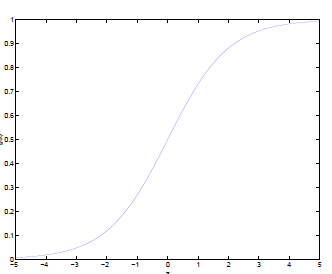
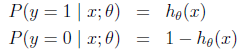

362题
说一下Adaboost,权值更新公式。当弱分类器是Gm时,每个样本的的权重是w1,w2...,请写出最终的决策公式。
答案
点击下方空白处获得答案
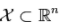
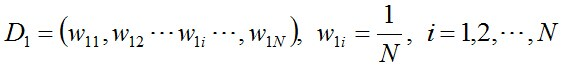
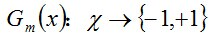
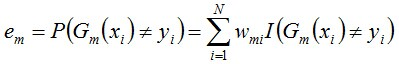
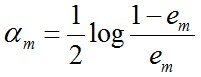
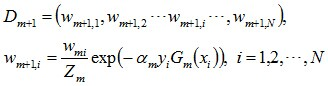
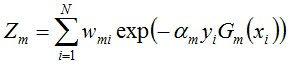
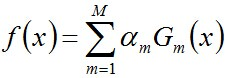
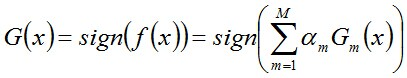
363题
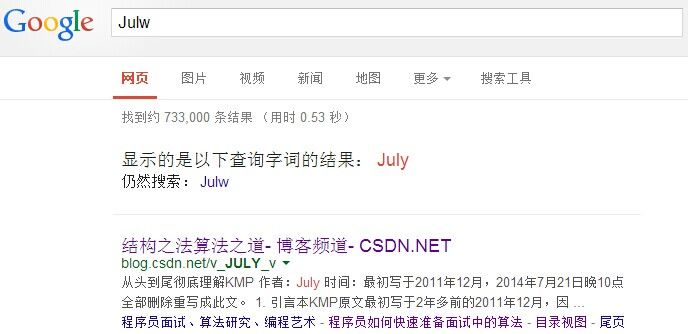
经常在网上搜索东西的朋友知道,当你不小心输入一个不存在的单词时,搜索引擎会提示你是不是要输入某一个正确的单词,比如当你在Google中输入“Julw”时,系统会猜测你的意图:是不是要搜索“July”,如下图所示:
这叫做拼写检查。根据谷歌一员工写的文章显示,Google的拼写检查基于贝叶斯方法。请说说的你的理解,具体Google是怎么利用贝叶斯方法,实现"拼写检查"的功能。
答案
点击下方空白处获得答案
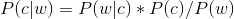
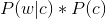
364题
为什么朴素贝叶斯如此“朴素”?
解析:
答案
点击下方空白处获得答案
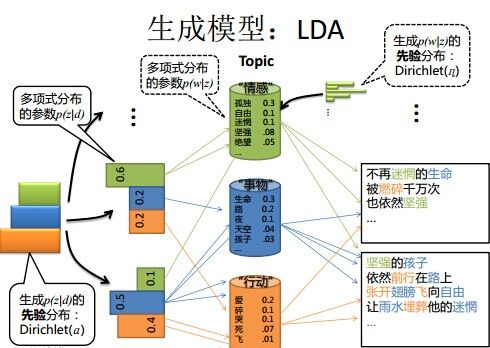
365题
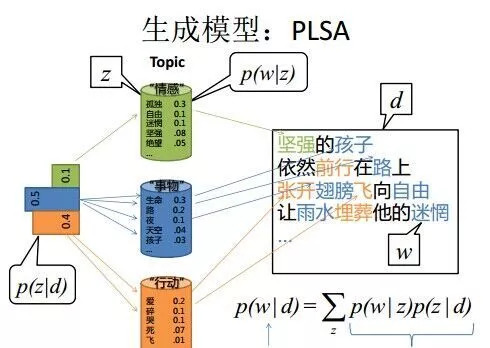
请大致对比下plsa和LDA的区别
答案
点击下方空白处获得答案
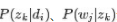
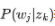
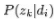
题目来源:七月在线官网(https://www.julyedu.com/)——面试题库——面试大题——机器学习
分享一哈
和大家分享完机器学习相关知识
小七再和大家分享下喔
我们的
【深度学习-第四期】
课程将于
8.23日
明天
开课啦
还没报名的小伙伴们
抓紧时间喽
2人及2人以上组团
立减100元
如没有找到小伙伴组团,
可以添加客服
julyedukefu_02
帮忙组团享受优惠喔
点击下方“阅读原文”,立即报名


更多资讯
请戳一戳


往期推荐
想做Python开发,这14种常用Python模块,你必须知道!
45万AI面经 | 面试offer拿不停,人称“offer收割机”

点击“阅读原文”,可在线报名
登录查看更多
相关内容

专知会员服务
54+阅读 · 2020年3月5日
Arxiv
11+阅读 · 2019年6月13日
Arxiv
21+阅读 · 2019年5月11日
Arxiv
3+阅读 · 2018年4月20日




相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
相关资讯
相关论文
Arxiv
11+阅读 · 2019年6月13日
Arxiv
21+阅读 · 2019年5月11日
Arxiv
3+阅读 · 2018年4月20日