BAT机器学习面试1000题系列(第116~120题)

上期思考题及参考解析
115.解释对偶的概念
一个优化问题可以从两个角度进行考察,一个是primal 问题,一个是dual 问题,就是对偶问题,一般情况下对偶问题给出主问题最优值的下界,在强对偶性成立的情况下由对偶问题可以得到主问题的最优下界,对偶问题是凸优化问题,可以进行较好的求解,SVM中就是将primal问题转换为dual问题进行求解,从而进一步引入核函数的思想。

116.如何进行特征选择?
特征选择是一个重要的数据预处理过程,主要有两个原因:一是减少特征数量、降维,使模型泛化能力更强,减少过拟合;二是增强对特征和特征值之间的理解
常见的特征选择方式:
1. 去除方差较小的特征
2. 正则化。1正则化能够生成稀疏的模型。L2正则化的表现更加稳定,由于有用的特征往往对应系数非零。
3. 随机森林,对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。一般不需要feature engineering、调参等繁琐的步骤。它的两个主要问题,1是重要的特征有可能得分很低(关联特征问题),2是这种方法对特征变量类别多的特征越有利(偏向问题)。
4. 稳定性选择。是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。
117.数据预处理
1. 缺失值,填充缺失值fillna:
i. 离散:None,
ii. 连续:均值。
iii. 缺失值太多,则直接去除该列
2. 连续值:离散化。有的模型(如决策树)需要离散值
3. 对定量特征二值化。核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。如图像操作
4. 皮尔逊相关系数,去除高度相关的列
118.你知道有哪些数据处理和特征工程的处理?
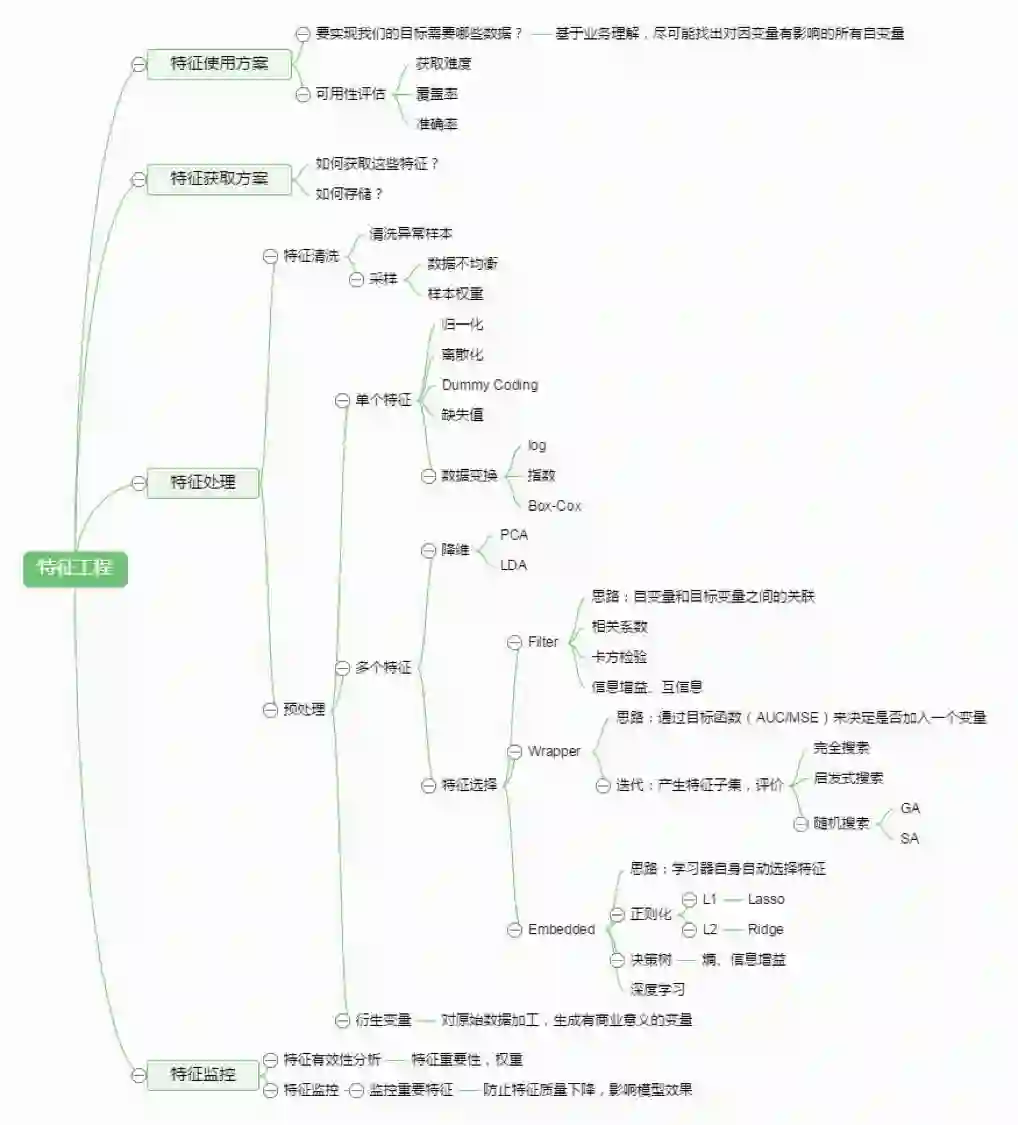
更多请查看此课程《机器学习工程师 第八期 [六大阶段、层层深入]》第7次课 特征工程(https://www.julyedu.com/course/getDetail/65)
119.简单说说特征工程

上图来源:http://www.julyedu.com/video/play/18
本期思考题:
120.请对比下Sigmoid、Tanh、ReLu这三个激活函数
在评论区留言,一起交流探讨,让更多小伙伴受益。
参考答案在明天公众号上公布,敬请关注!
往期题目:
【关注本公众号,点击菜单“有奖游戏”,答题抽大奖】

课程咨询|微信:julyedukefu
七月热线:010-82712840




