深度学习面试100题(第71-75题)

点击上方蓝字关注

深度学习面试100题(第71-75题)

71
深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵 A,B,C 的乘积ABC,假设三个矩阵的尺寸分别为m∗n,n∗p,p∗q,且m < n < p < q,以下计算顺序效率最高的是()
A、 (AB)C
B、 AC(B)
C、 A(BC)
D、 所以效率都相同
正确答案是:A
解析:
首先,根据简单的矩阵知识,因为 A*B , A 的列数必须和 B 的行数相等。因此,可以排除 B 选项,
然后,再看 A 、 C 选项。在 A 选项中,m∗n 的矩阵 A 和n∗p的矩阵 B 的乘积,得到 m∗p的矩阵 A*B ,而 A∗B的每个元素需要 n 次乘法和 n-1 次加法,忽略加法,共需要 m∗n∗p次乘法运算。同样情况分析 A*B 之后再乘以 C 时的情况,共需要 m∗p∗q次乘法运算。因此, A 选项 (AB)C 需要的乘法次数是 m∗n∗p+m∗p∗q 。同理分析, C 选项 A (BC) 需要的乘法次数是 n∗p∗q+m∗n∗q。
由于m∗n∗p

72
输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为
A、 95
B、 96
C、 97
D、 98
正确答案是:C
解析:
首先我们应该知道卷积或者池化后大小的计算公式,其中,padding指的是向外扩展的边缘大小,而stride则是步长,即每次移动的长度。
这样一来就容易多了,首先长宽一般大,所以我们只需要计算一个维度即可,这样,经过第一次卷积后的大小为: 本题 (200-5+2*1)/2+1 为99.5,取99
经过第一次池化后的大小为: (99-3)/1+1 为97
经过第二次卷积后的大小为: (97-3+2*1)/1+1 为97

73
基于二次准则函数的H-K算法较之于感知器算法的优点是()?
A、 计算量小
B、 可以判别问题是否线性可分
C、 其解完全适用于非线性可分的情况
正确答案是:B
解析:
HK算法思想很朴实,就是在最小均方误差准则下求得权矢量.
他相对于感知器算法的优点在于,他适用于线性可分和非线性可分得情况,对于线性可分的情况,给出最优权矢量,对于非线性可分得情况,能够判别出来,以退出迭代过程。
来源:@刘炫320,链接:http://blog.csdn.net/column/details/16442.html

74
在一个神经网络中,知道每一个神经元的权重和偏差是最重要的一步。如果知道了神经元准确的权重和偏差,便可以近似任何函数,但怎么获知每个神经的权重和偏移呢?
A、搜索每个可能的权重和偏差组合,直到得到最佳值
B、赋予一个初始值,然后检查跟最佳值的差值,不断迭代调整权重
C、随机赋值,听天由命
D、以上都不正确的
正确答案是:B
解析:
答案:(B)
选项B是对梯度下降的描述。

75
神经网络模型(Neural Network)因受人类大脑的启发而得名
神经网络由许多神经元(Neuron)组成,每个神经元接受一个输入,对输入进行处理后给出一个输出,如下图所示。请问下列关于神经元的描述中,哪一项是正确的?
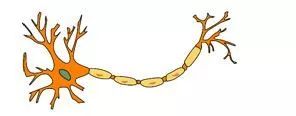
A、 每个神经元可以有一个输入和一个输出
B、 每个神经元可以有多个输入和一个输出
C、 每个神经元可以有一个输入和多个输出
D、 每个神经元可以有多个输入和多个输出
E、 上述都正确
正确答案是:E
解析:
答案:(E)
每个神经元可以有一个或多个输入,和一个或多个输出。

题目来源:七月在线官网(https://www.julyedu.com/)——面试题库——笔试练习——深度学习
福利时刻:为了帮助大家更多的学习深度学习课程的相关知识,我们特意推出了深度学习系列课程。

更多资讯
请戳一戳


往期精选
人工智能 | AI人才薪酬是什么水平?看完惊呆了!
面试大题 | 教你如何迅速秒杀掉:99%的海量数据处理面试题
干货合集 |【干货合集】从贝叶斯方法谈到贝叶斯网络
分享一哈 | 推荐系统算法合集,满满都是干货(建议收藏)

点击“阅读原文”,可在线报名



