一些关于随机矩阵的算法

©作者 | 刘敏
学校 | Universität Bonn
研究方向 | Probability
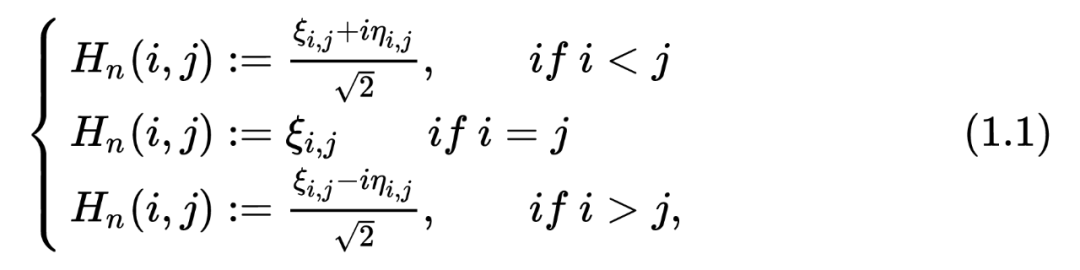

function GUE = GUE_matrix_MC_create_GUE(size,seed)
%set random seed
rng(seed);
tempMat=randn(size)+1i*randn(size);
GUE=(tempMat+tempMat')/2;
end-
对存储的要求非常大,也就是 。比如说我们需要大概 80G 去存储一个 1w 乘 1w 的矩阵。 -
构造出来的是一个 dense 的矩阵,也就是大多数分量都不是零!那当我们要去算 的时候,我们基本只能使用最基本的算特征值的方法,复杂度就是 !
他对存储的要求比较低。
他有点特殊,可以用一些算法复杂度比较低的方法来算他最大的特征值。
-
他最大的特征值的分布是等于 的分布的。

-
和 随机变量都是两两互为独立的。 -
sub-digonal 和 super-digonal 上是相等的!
function triMat = GUE_matrix_MC_create_TriMat(size,seed)
%set random seed
rng(seed);
%set subdiagonal/superdigonal as chi-distributed
d=sqrt(1/2)*sqrt(chi2rnd(beta*[size:-1:1]))';
%set up digonal
d1=(randn(size,1));
triMat=spdiags(d,1,size,size)+spdiags(d1,0,size,size)+spdiags(d,1,size,size)';
end这个方法确实好,通过观察(2.1)我们可以发现:
-
我们只需要 的存储空间。
-
他具有 tridigonal 和 irreducible 的结构(因为他的 sub-digonal 上的元素 a.s. 不等于 0),那我们就可以用一些比较厉害的算法来计算他最大的特征值了!比如说 bisection method(这个方法真的不错,感兴趣的可以看看这本书的 [4] lecture 30),他的算法复杂度只有 。

▲ 从上到下依次为GUE+eigs, (2.1)+eigs以及(2.1)+bisection,我们可以看到他们的算法复杂度分别为n^3, n^2以及n.
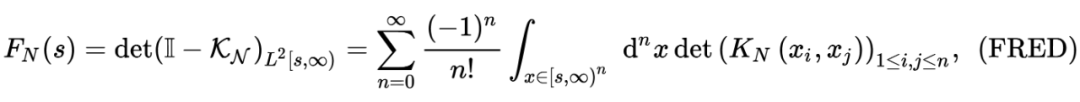
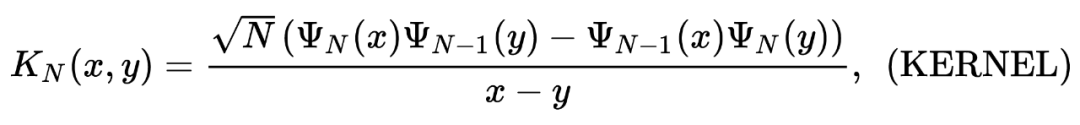

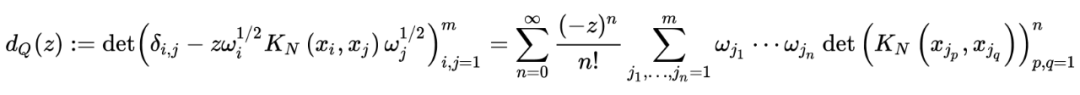

function [result] = step_TASEP_cdf(sigma,t,s)
s=step_TASEP_proper_interval(t,sigma,s);
c2=sigma^(-1/6)*(1-sigma^(1/2))^(2/3);
delta_t=c2^(-1)*t^(-1/3);
n=sigma*t;
MAX=(t+n-2*(sigma)^(1/2)*t-1/2)/(c2*t^(1/3));
for k=1:length(s)
if s(k)> MAX
result(k)=1;
else
s_resc=s(k)+delta_t;
x=s_resc:delta_t:MAX;
x=x';
result(k)=det(eye(length(x))-step_TASEP_kernel(t,sigma,x,x)*delta_t);%Bornemann Method
end
end
end这篇文章就是简单的介绍了一下有关于 random matrix 的算法,之后可能会陆续介绍一下 KPZ-universality 相关的东西,也就是我自己的方向,真的超级有趣!

参考文献
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧




