RCNN算法分析
项目地址:https://github.com/rbgirshick/rcnn
论文地址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn
SelectiveSearch:http://koen.me/research/pub/uijlings-ijcv2013-draft.pdf
2014年CVPR上的经典paper,这篇文章的算法思想又被称之为:R-CNN(Regions with Convolutional Neural Network Features),是物体检测领域曾经获得state-of-art精度的经典文献。其是将CNN方法应用到目标检测问题上的一个里程碑,由Ross Girshick提出,借助CNN良好的特征提取和分类性能,通过Region Proposal方法实现目标检测问题的转化。
R-CNN概括起来就是selective search+CNN+L-SVM的检测器
Selective Search遵循如下的原则:
1. 图片中目标的尺寸不一,边缘清晰程度也不一样,选择性搜索应该能够将所有的情况都考虑进去,如下图,最好的办法就是使用分层算法来实现。
2. 区域合并的算法应该多元化。初始的小的图像区域(Graph-Based Image Segmentation得到)可能是根据颜色、纹理、部分封闭等原因得到的,一个单一的策略很难能适应所有的情况将小区域合并在一起,因此需要有一个多元化的策略集,能够在不同场合都有效。
3. 能够快速计算。
IOU的定义
因为没有搞过物体检测不懂IOU这个概念,所以就简单介绍一下。物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。
IOU定义了两个bounding box的重叠度,如下图所示:
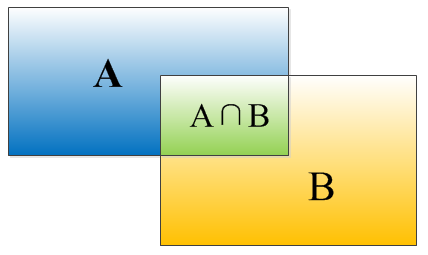
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例:
IOU=SI/(SA+SB-SI)
非极大值抑制基础知识:
因为一会儿讲RCNN算法,会从一张图片中找出n多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
VOC物体检测任务
这个就相当于一个竞赛,里面包含了20个物体类别:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/examples/index.html 还有一个背景,总共就相当于21个类别,因此一会设计fine-tuning CNN的时候,我们softmax分类输出层为21个神经元。
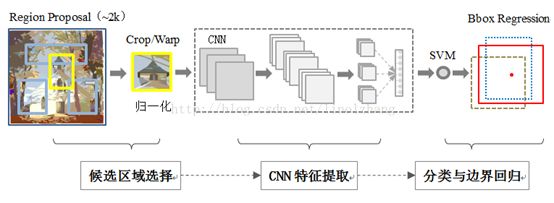
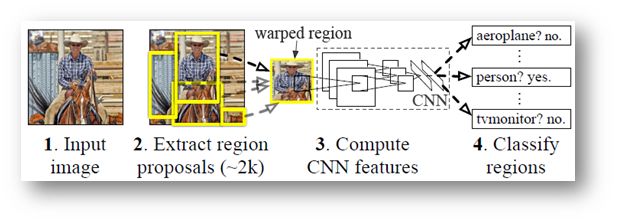
流程框架:
候选区域:先将region用selective search代替传统的滑动窗口,提取出2k+个候选region proposal,根据Proposal提取的目标图像进行归一化,作为CNN的标准输入。
提取特征:标准CNN过程,根据输入进行卷积/池化等操作,得到固定维度的输出;对于每个region,用摘掉了最后一层softmax层的AlexNet来提取特征。
分类:训练出来K个L-SVM作为分类器(每个目标类一个SVM分类器,K目标类个数),使用AlexNet提取出来的特征作为输出,得到每个region属于某一类的得分。
边界回归:最后对每个类别用NMS(non-maximum-suppression)来舍弃掉一部分region,得到精确的目标区域 (对得到的分类的前景目标进行精确的定位与合并,避免多个检出)
候选区域生成
使用了Selective Search1方法从一张图像生成约2000-3000个候选区域。基本思路如下:
- 使用一种过分割手段,将图像分割成小区域
- 查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,所谓候选区域
候选区域生成和后续步骤相对独立,实际可以使用任意算法进行。
合并规则
涉及区域的颜色直方图、纹理直方图、面积和位置。合并后的区域特征可以直接由子区域特征计算而来,速度较快。
优先合并以下四种区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
- 合并后,总面积在其BBOX中所占比例大的
保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域。
保证合并后形状规则。
为尽可能不遗漏候选区域,上述操作在多个颜色空间中同时进行(RGB,HSV,Lab等)。在一个颜色空间中,使用上述四条规则的不同组合进行合并。所有颜色空间与所有规则的全部结果,在去除重复后,都作为候选区域输出。
候选框搜索
1、实现方式
我们搜索出2000个候选框。然后从上面的总流程图中可以看到,搜出的候选框是矩形的,而且是大小各不相同。然而CNN对输入图片的大小是有固定的,如果把搜索到的矩形选框不做处理,就扔进CNN中,肯定不行。因此对于每个输入的候选框都需要缩放到固定的大小。下面我们讲解要怎么进行缩放处理,为了简单起见我们假设下一阶段CNN所需要的输入图片大小是个正方形图片227*227。因为我们经过selective search 得到的是矩形框,paper试验了两种不同的处理方法:
(1)各向异性缩放
这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到CNN输入的大小227*227,如下图(D)所示;
(2)各向同性缩放
因为图片扭曲后,估计会对后续CNN的训练精度有影响,于是作者也测试了“各向同性缩放”方案。这个有两种办法
A、直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如下图(B)所示;
B、先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如下图(C)所示;

对于上面的异性、同性缩放,文献还有个padding处理,上面的示意图中第1、3行就是结合了padding=0,第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高,(含一个16宽度的边框,原region向周围扩大16个像素,包含一些背景信息,超过的补色,然后再wrap到227*227)。
上面处理完后,可以得到指定大小的图片,因为我们后面还要继续用这2000个候选框图片,继续训练CNN、SVM。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。
因此我们需要用IOU为2000个bounding box打标签,以便下一步CNN训练使用。在CNN阶段,如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别,否则我们就把它当做背景类别。
CNN特征提取
1、算法实现
a、网络结构设计阶段
网络架构我们有两个可选方案:第一选择经典的Alexnet;第二选择VGG16。经过测试Alexnet精度为58.5%,VGG16精度为66%。VGG这个模型的特点是选择比较小的卷积核、选择较小的跨步,这个网络的精度高,不过计算量是Alexnet的7倍。后面为了简单起见,我们就直接选用Alexnet,并进行讲解;Alexnet特征提取部分包含了5个卷积层、2个全连接层,在Alexnet中p5层神经元个数为9216、 f6、f7的神经元个数都是4096,通过这个网络训练完毕后,最后提取特征每个输入候选框图片都能得到一个4096维的特征向量。
b、网络有监督预训练阶段
参数初始化部分:物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,这边文献采用的是有监督的预训练。所以paper在设计网络结构的时候,是直接用Alexnet的网络,然后连参数也是直接采用它的参数,作为初始的参数值,然后再fine-tuning训练。
网络优化求解:采用随机梯度下降法,学习速率大小为0.001;
C、fine-tuning阶段
我们接着采用selective search 搜索出来的候选框,然后处理到指定大小图片,继续对上面预训练的cnn模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景) (20 + 1bg),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个事正样本、96个事负样本(正负样本的定义前面已经提过,不再解释)。
类别判断
分类器
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络输出的4096维特征,输出是否属于此类。
由于负样本很多,使用hard negative mining方法。
正样本
本类的真值标定框。
负样本
考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本
结果
本文将深度学习引入检测领域,一举将PASCAL VOC上的检测率从35.1%提升到53.7%。
本文的前两个步骤(候选区域提取+特征提取)与待检测类别无关,可以在不同类之间共用。这两步在GPU上约需13秒。
同时检测多类时,需要倍增的只有后两步骤(判别+精修),都是简单的线性运算,速度很快。这两步对于100K类别只需10秒。



