TGANv2、VideoGPT、DVG…你都掌握了吗?一文总结视频生成必备经典模型(二)
机器之心专栏
本专栏由机器之心SOTA!模型资源站出品,每周日于机器之心公众号持续更新。
本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 2 期进行连载,共介绍 15 个在视频生成任务上曾取得 SOTA 的经典模型。
第 1 期:TGAN、VGAN、MoCoGAN、SVG、vid2vid、VideoVAE、DVD-GAN、SWGAN
第 2 期:TGANv2、TGANv2-ODE、VideoGPT、DVG、NÜWA、StyleGAN-V、Video Diffusion Models
您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
第1期回顾:CopyNet、SeqGAN、BERTSUM…你都掌握了吗?一文总结文本摘要必备经典模型(一)
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| TGANv2 | https://sota.jiqizhixin.com/project/tganv2-2021 收录实现数量:2 支持框架:PyTorch |
Train Sparsely, Generate Densely: Memory-efficient Unsupervised Training of High-resolution Temporal GAN |
| TGANv2-ODE | https://sota.jiqizhixin.com/project/tganv2-ode 收录实现数量:1 支持框架:PyTorch |
Latent Neural Differential Equations for Video Generation |
| VideoGPT | https://sota.jiqizhixin.com/project/videogpt 收录实现数量:1 支持框架:PyTorch |
VideoGPT: Video Generation using VQ-VAE and Transformers |
| DVG | https://sota.jiqizhixin.com/project/dvg 收录实现数量:1 支持框架:PyTorch |
Diverse Video Generation using a Gaussian Process Trigger |
| NÜWA | https://sota.jiqizhixin.com/project/nuwa 收录实现数量:1 支持框架:PyTorch |
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion |
| StyleGAN-V | https://sota.jiqizhixin.com/project/stylegan-v 收录实现数量:1 支持框架:PyTorch |
StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2 |
| Video Diffusion Models | https://sota.jiqizhixin.com/project/video-diffusion-models 收录实现数量:2 支持框架:PyTorch |
Video Diffusion Models |
TGANv2
在视频数据集上训练生成对抗网络(GAN)面临的一个挑战就是:视频数据集的规模太大,而且每个观测值都很复杂。一般来说,训练GAN的计算成本随着分辨率的提高而呈指数级增长。在这项研究中,提出了一种新型的高分辨率视频数据集无监督学习的内存效率方法,其计算成本仅与分辨率呈线性比例变化:具体的,通过将生成器模型设计成小型子生成器的堆叠,如图1所示,并以特定的方式训练模型来实现这一目标。训练时,在每一对连续的子生成器之间引入一个辅助子采样层,将帧率按一定比例降低。这个处理过程可以让每个子生成器学习不同分辨率下的视频分布情况,由此只需要几个GPU来训练一个高度复杂的生成器,该生成器在起始得分方面远远超过了前者。
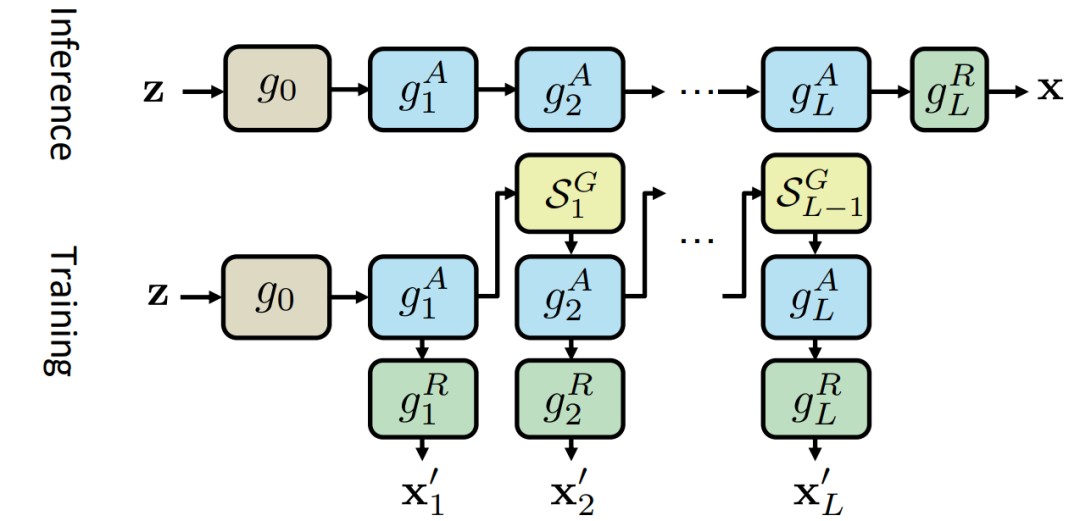
图1. 使用多个子采样层的生成器
经典temporal GAN(即TGAN和MoCoGAN)使用一个由两个子网络组成的生成器:时态生成器g0和图像生成器g1。对于T-帧视频的生成,时态生成器生成一个大小为T的潜在向量集(或潜在空间中的T-帧视频){z1, . . zT },图像生成器将潜在向量视频和噪声向量转换为图像视频,如图2所示。
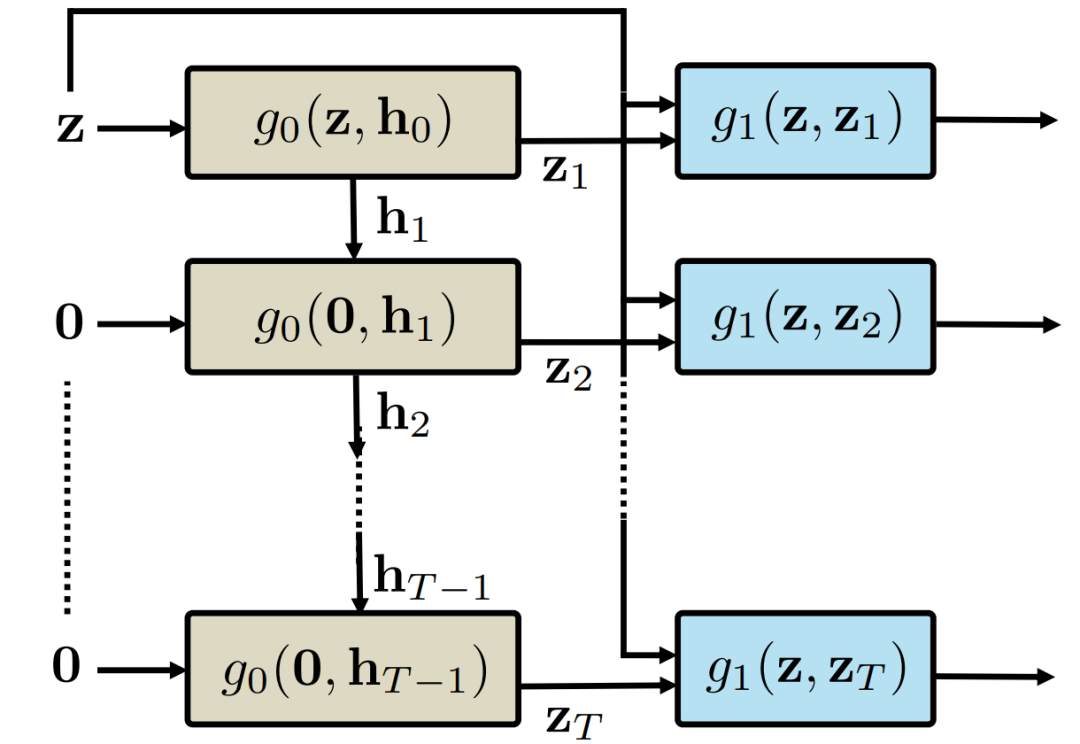
图2. 经典temporal GAN中使用的时态生成器和图像生成器之间的关系概述。为了生成一组T个潜在向量,时间生成器通常是一个递归网络
首先描述单次采样层的GAN的训练。假设一个生成器从噪声向量z输出视频x,由两个块组成:抽象块g^A和渲染块g^R。在推理过程中,该生成器的样本生成过程等同于传统GAN中的生成器,即,G(z)可以表示为
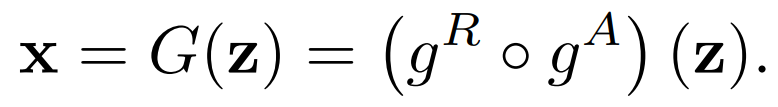
在训练阶段,将G修改为G’,在g^R和g^A之间引入一个子采样层S^G,以降低从g^A产生的abstract map的帧率。训练阶段的目标函数变为
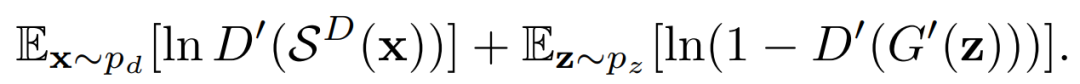
给定L个子生成器,或L个抽象块组成的模型。在训练的时候,这个架构是用L个相应的渲染块和L-1个子采样层来训练的。推理阶段,可以简单地通过连续应用抽象块来评估x:
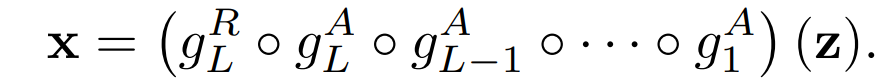
在训练时,使用L组子生成器,每个子生成器都递归地将(g_m)^A和(S_m)^G(m = 1, ... , l - 1)应用于abstract map,并通过(g_l)^R将最终抽象块(g_l)^A的输出转换为视频。
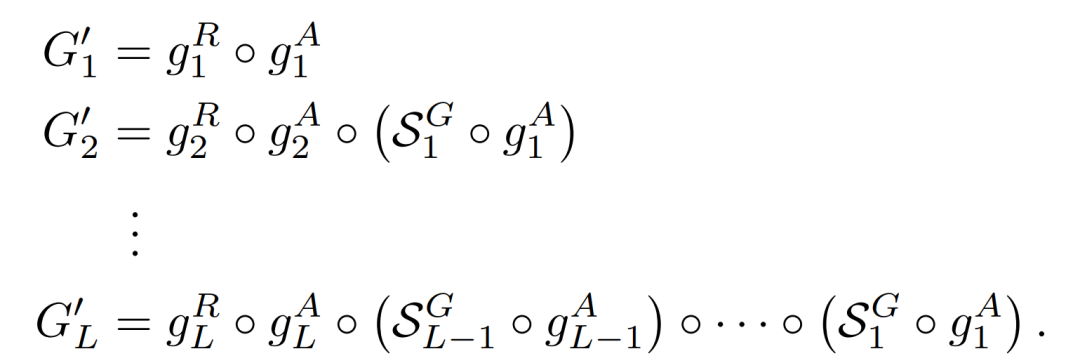
为了训练上述由多个子生成器组成的生成器,需要一个鉴别器为它们生成的视频集评估一个分数。鉴别器由多个子鉴别器组成。D’_l表征第l个子鉴别器,从第l个子生成器G’_l中获取样本x’_l并返回一个标量值。鉴别器D’利用以下公式对一组x’_l进行评分
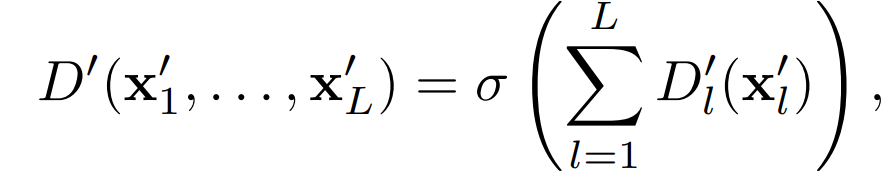
该方法的本质是 the division of roles:不是给单一的大规模模型提供密集的原始数据集,而是用数据集的选定部分来训练每个子生成器,以帮助子生成器提高模拟给定role的能力。具有low indices的子生成器的作用是在抽象层面上模仿原始视频数据集;也就是说,生成一个随时间自然流动的低分辨率视频。具有low indices的鉴别器负责评估低分辨率的高帧率视频的质量。这使得low indices的生成器能够捕捉视频中独立于高分辨率细节的整体运动。另一方面,具有high indices的子生成器的作用是模仿原始视频数据集的视觉质量。也就是说,只需要一个高分辨率的低帧率视频来训练。
论文具体介绍了一个由四个子生成器组成的生成器,它可以合成一个具有T帧和W×H像素的视频。与TGAN和MoCoGAN一样,该生成器首先从噪声向量中产生T个潜在特征图,然后将每个特征图转换为相应的帧(见图2)。具体的网络结构见图3和图4。
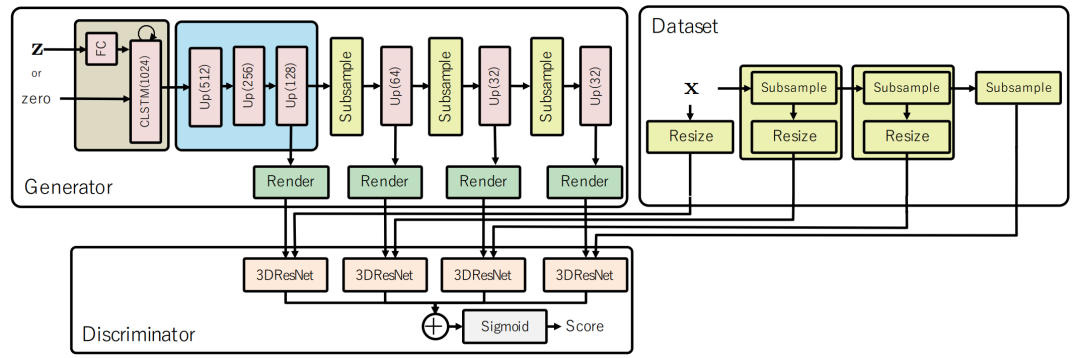
图3. 模型的网络配置。"CLSTM(C) "代表具有C通道和3×3内核的卷积LSTM。"Up(C) "指的是上采样块,它返回具有C个通道和两倍于输入分辨率的特征图
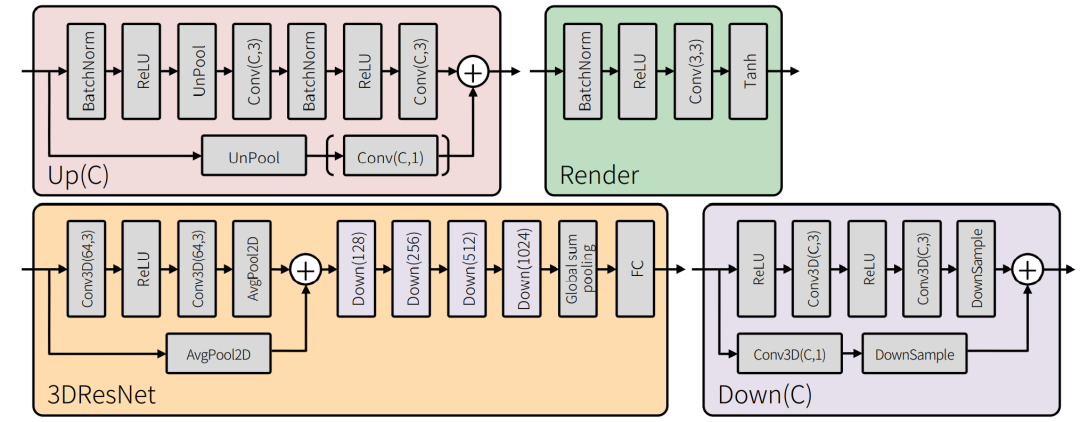
图4. 论文中使用的块细节。"Conv(C, k) "表示具有C通道和(k×k)内核的二维卷积层。"Conv3D(C, k) "表示具有C通道和(k×k×k)核的三维卷积层。"UnPool "表示一个具有(2×2)核和stride为2的二维 unpooling layer 。"AvgPool2D "表示沿空间维度的二维平均池化层,核为(2×2),stride为2。请注意,它并不沿时间维度进行池化操作。"DownSample "表示下采样操作。如果输入的三维特征图的每个维度的大小都大于1,该操作符就会沿着其轴线进行平均池化操作(如果在进行平均池化操作时大小为奇数,则目标轴的padding被设置为1)。否则,不对该轴进行 average pooling 。Up(C) "中的(-)表示,如果输入通道的数量与输出通道的数量相等,则不插入括号内的块
当前 SOTA!平台收录TGANv2共 2个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| TGANv2 | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/tganv2-2021 |
TGANv2-ODE
TGANv2-ODE研究了神经微分方程( Neural Differential Equations )对视频生成的时间动态建模的影响。神经微分方程的范式具有许多理论上的优势,包括在视频生成过程中首次对时间进行连续表示。为了解决神经微分方程的影响,作者在这项工作中研究了时间模型的变化如何影响生成的视频质量,最终支持使用神经微分方程作为经典的temporal生成器的简单替代。
TGAN用一个temporal generator G_t将一个单一的噪声向量转化为多个考虑到时间的向量,这是一系列的一维卷积。然后,将生成的向量与开始的单一噪声向量连接起来,送入图像生成器G_i中。G如图5所示:
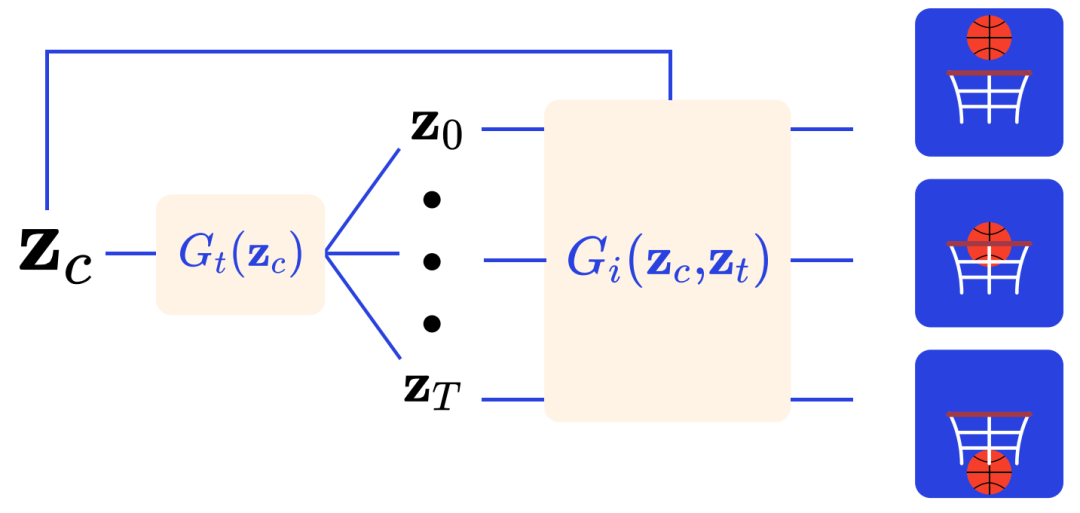
图5. G_t将潜在变量z_c转换为一系列的temporal vectors z0, z1, ..., zT。每个z_t与z_c串联并转化为一个图像。上述图像被连接起来组成一个视频
目前,讨论temporal generator的选择的文章非常少,文本提出在一般物理学常见的范式下对其进行探索:使用微分方程来表示temporal dynamics。在使用历史图像生成函数的同时,将观察不同temporal生成函数的性能指标的变化。生成函数系列之间的比较可以通过图6直观地看到。
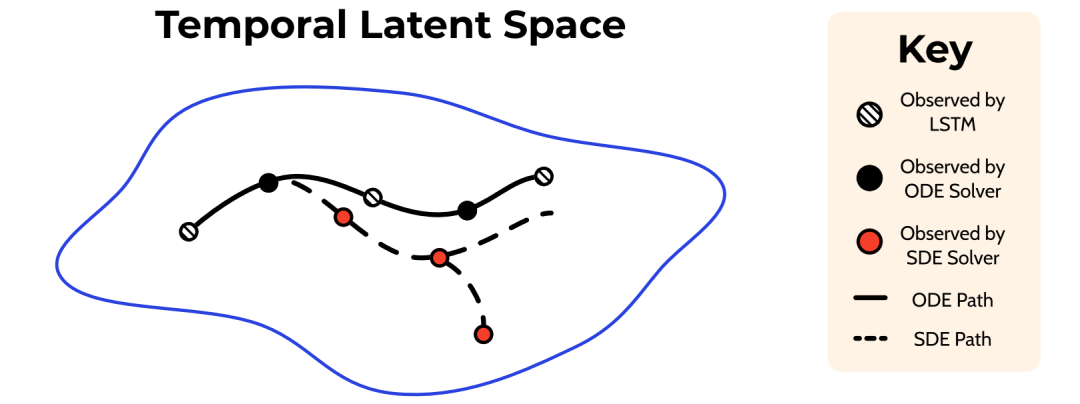
图6. 与典型的LSTM相比,神经微分方程的观察次数更多,SDE( Stochastic Differential Equations )的解决潜力更大
可以用微分方程( Ordinary Differential Equations , ODEs)代替自动回归的LSTM或1D核来模拟潜在变量z_t的演变。通过学习函数f(z_t),可以通过积分找到未来的z_T:
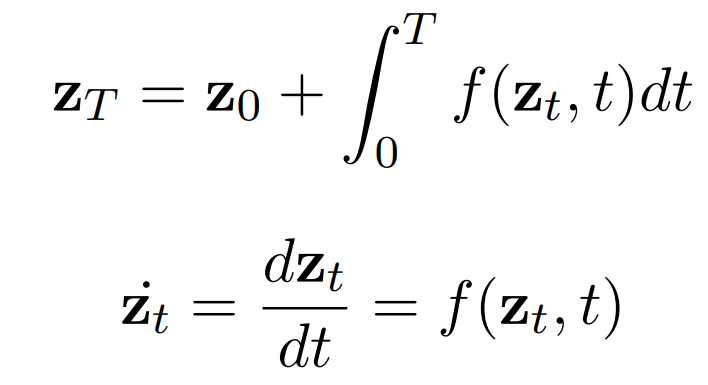
然后图像生成器G_i(z)可以从z_t产生一个图像。使用微分方程,该模型可以解释traversing潜在空间的细微差别,并说明z_(t<t+ε<t+1)的运动情况。LSTM只查看稀疏的时间步长;模型从z_t移动到z_t+1,从不考虑z_t+0.5的情况。而ODEs允许遍历中间的z_t值,这有可能导致更好的性能,因为这可以更接近于潜在的轨迹。ODE家族还允许对模型进行高阶解释。f(z_t)可以代表比简单的z˙t更高的阶数,如z¨t或更高。一阶ODE参数化了整合过程中更直接的变化,而高阶则代表潜在变量中更长期的转变,如凹陷性(concavity)。
ODE允许在确定的系统中进行路径近似。每个z_t都会产生一个z_t+1,但这并不反映视频的真正功能。SDEs可能是表征视频中存在的随机性的一个好方法,它提供了ODEs的所有好处,同时允许随机性与它们的附加噪声。令μ(z_t)和σ(z_t)分别代表漂移和扩散,我们发现z_T有:
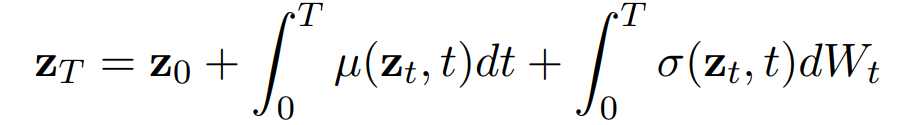
µ(z_t)和σ(z_t)中的每一个都是由一个神经网络设定的参数。W_t是一个 Wiener 过程,是一个具有高斯增量的连续数值系列。这种表述的有效性可以通过思考一个人脸表情变化的视频来体现出来。如果演员一开始是中性脸,他们之后可能会产生一个悲伤的脸。然而,微笑也是同样可能的。通过注入随机性,任何一条路径都可能被模型探索到。
微分方程由于其连续的特性,可以增加对路径traversed方式的控制。因为z_t是通过积分找到的,所以具有两个其他方式所不具备的独特特征:首先,z_t可以在时间上向后整合,允许发现z_t-n,即在第一帧之前发生的事情。第二,可以很容易实现帧率提高。微分方程求解器可以对z_(t<t+ε<t+1)进行评估。为了达到更高的帧率,图像生成器只需要对一些中间的z_t评估进行采样。像这样的控制在递归模型中是不可能的。
当前 SOTA!平台收录TGANv2-ODE共1个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| TGANv2-ODE | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/tganv2-ode |
Video-GPT
VideoGPT是一种概念简单的架构,用于扩展基于似然的生成对自然视频进行建模。Video-GPT将通常用于图像生成的VQ-VAE和Transformer模型以最小的修改改编到视频生成领域。VideoGPT使用VQVAE,VQVAE通过采用3D卷积和轴向自注意力学习降采样的原始视频离散潜在表示。然后使用简单的类似GPT的架构进行自回归,使用时空建模离散潜在位置编码。VideoGPT结构如图7:
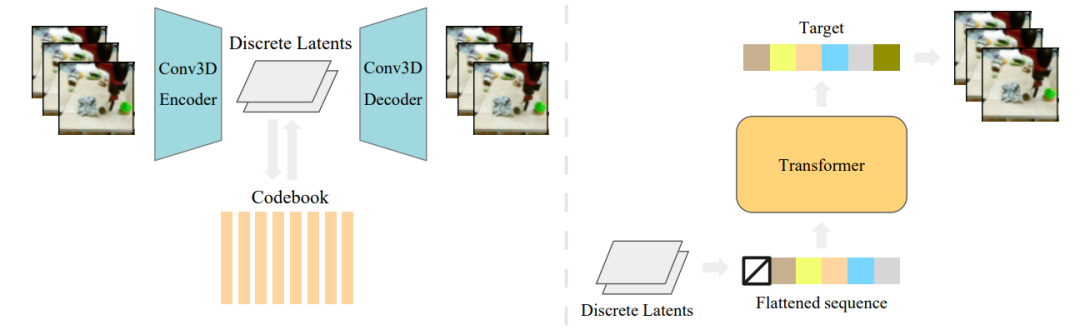
图7. 把训练管道分成两个连续的阶段:训练VQ-VAE(左)和训练潜在空间的自回归变换器(右)。第一阶段类似于原始的VQ-VAE训练程序。在第二阶段,VQ-VAE将视频数据编码为潜在序列作为先验模型的训练数据。对于推理阶段,首先从先验中抽取一个潜在序列,然后用VQ-VAE将潜在序列解码为视频样本
Learning Latent Codes
为了学习一组离散的潜在编码,首先在视频数据上训练一个VQ-VAE。编码器结构由一系列三维卷积组成,这些卷积在空间-时间上进行下采样,然后是注意力残差块。每个注意力残差块的设计如图8所示,使用LayerNorm和轴向注意力层。解码器的结构与编码器相反,注意力残差块之后是一系列的三维转置卷积,在空间-时间上进行上采样。位置编码是学习到的时空嵌入,在编码器和解码器的所有轴向注意力层之间共享。

图8. VQVAE中注意力残差块的结构
Learning a Prior
第二阶段是对第一阶段的VQ-VAE潜在编码进行先验学习。遵循Image-GPT的先验网络结构,只是在前馈层和注意力块层之后增加了dropout层,用于正则化。尽管VQ-VAE是无条件训练的,但可以通过训练一个条件先验来生成条件样本。可以使用两种类型的条件。
交叉注意力(Cross Attention)。对于video frame conditioning,首先将调整后的帧送入一个3D ResNet,然后在之前的网络训练中对ResNet的输出表示进行交叉注意力。
条件性范数(Conditional Norms)。与GANs中使用的调整方法类似,将transformer层归一化层中的增益和偏置参数化为条件向量的仿射函数。这种方法可以用于行动和类别调整模型。
当前 SOTA!平台收录 VideoGPT 共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| VideoGPT | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/videogpt |
在给定几个背景(或过去)帧的情况下,生成未来帧是一项具有挑战性的任务。它需要从潜在的未来状态的多样性方面对视频的时间一致性和多模态进行建模。目前用于视频生成的变量方法倾向于将多模态的未来结果边缘化。而多样化视频生成器(Diverse Video Generator,DVG)则是对未来结果中的多模态进行明确建模,并利用它对不同的未来进行采样,DVG使用高斯过程(Gaussian Process,GP)来学习关于过去的未来状态的先验,并保持一个关于特定样本的可能未来的概率分布。此外,利用这个分布的超时变化,通过估计正在进行的序列的结束来控制不同未来状态的采样。即,利用GP在输出函数空间上的方差来触发行动序列的变化。
使用高斯过程对未来状态的多样性进行建模,是由于高斯过程具有几个理想的特性:它们在贝叶斯公式中学习了关于给定过去背景的潜在未来的先验。这使得我们能够在提供更多的背景框架作为证据时更新可能的未来分布,并保持一个潜在的未来列表(GP的基础函数)。DVG给出了一个非常有趣的formulation:估计何时生成一个不同的输出与继续一个正在进行的行动,以及控制预测的未来的方法。
DVG利用GP在任何特定时间步长的方差作为行动序列是否正在进行或结束的指标,具体如图9,当观察到一帧(例如在时间t)可能有几种可能的未来时,GP模型的方差很高(图9(左))。不同的函数表征可以生成的潜在行动序列,从这个特定的框架开始。一旦选择了下一帧(t+2),未来状态的GP方差相对较低(图9(中)),表明一个行动序列正在进行中,模型应该继续它,而不是试图对一个不同的样本进行采样。在正在进行的序列完成后,对潜在的未来状态的GP方差又变得很高。这意味着我们可以继续这一行动。以上过程简要说明了我们如何使用GP来决定何时触发不同的行动。图9(右)显示了一个使用GP触发器的例子,每隔几帧就触发一个不同的动作。
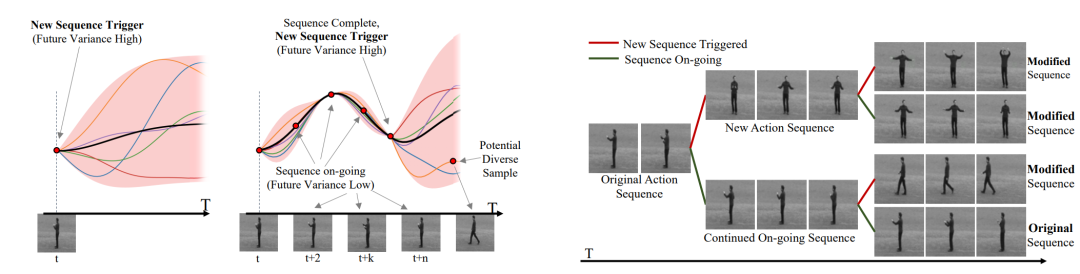
图19. 使用GP差异来控制正在进行的行动与新行动的抽样说明
给定一组观察到的帧,目标是生成一组多样化的未来帧。DVG模型有三个模块:(a)一个帧自动编码器(或编码器生成器),(b)一个LSTM时间动态编码器,(c)一个GP时间动态编码器,用于对各种潜在的未来状态进行先验和概率建模。帧编码器将帧映射到一个潜在的空间,随后被时间动力学编码器和帧发生器利用来合成未来帧。对于推理阶段,使用所有三个模块一起生成未来帧,并使用GP作为触发器来切换到不同的未来状态。
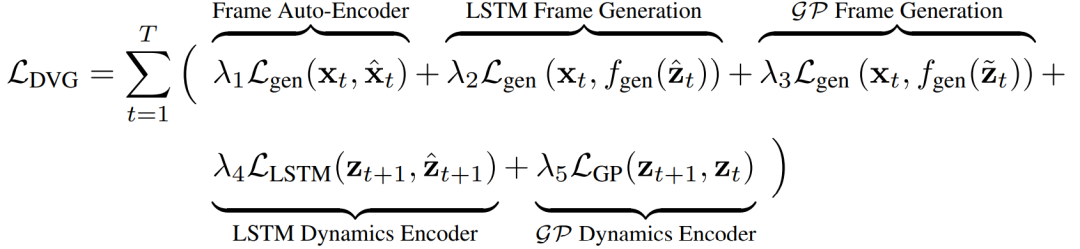
所有三个模块,帧自动编码器、LSTM及GP时间编码器,是使用以下目标函数联合训练的:
在推理过程中,将上述的三个模块组合在一起,将帧编码器的输出z_t输入给LSTM和GP编码器。LSTM输出zˆt+1,GP输出一个平均值和方差。GP的方差可以用来决定我们是否要继续一个正在进行的动作或产生新的多样化的输出,这个过程称之为触发开关。如果决定继续进行正在进行的动作,将LSTM的输出zˆt+1提供给解码器以生成下一帧;如果决定切换,就从GP中取样z˜t+1并将其作为输入提供给解码器。这个过程如图10所示(stage 3)。将生成的未来帧用作编码器的输入,以输出下一个z_(t+1);这个过程重复进行,直到得到我们想要的生成帧。
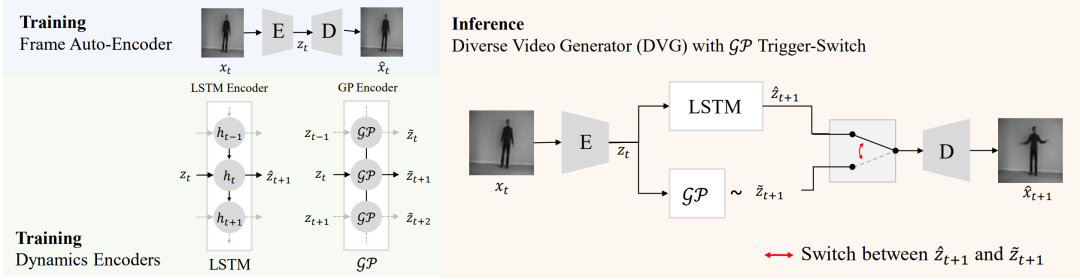
图10. DVG模型架构
当前 SOTA!平台收录 DVG 共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| DVG | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/dvg |
NÜWA
NÜWA不是一个单纯的视频生成模型,而是一个多模态预训练模型。为了同时覆盖语言、图像和视频的不同场景,NÜWA是一个三维变换器编码器-解码器框架,它不仅可以处理作为三维数据的视频,还可以分别用于处理一维和二维数据的文本和图像。
为了涵盖所有的文本、图像和视频或其草图,将它们全部视为token,并定义了一个统一的三维符号X∈R_h×w×s×d,其中,h和w表示空间轴上的token数量(分别为高度和宽度),s表示时间轴上的token数量,d是每个token的尺寸。文本自然是离散的,继Transformer之后,使用小写的 byte pair encoding 字节对编码(BPE)将其标记化并嵌入到R_1×1×s×d。由于文本没有空间维度,使用占位符1。图像是自然的连续像素。输入一个高度为H、宽度为W、通道为C的原始图像I∈R_H×W×C,VQ-VAE训练一个可学习的 codebook ,在原始连续像素和离散token之间建立一个桥梁。
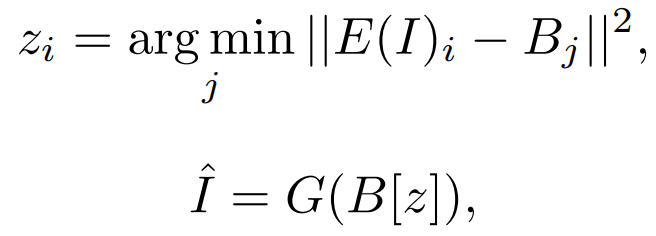
其中,E为编码器。搜索到的结果z∈{0, 1, . . . , N - 1}_h×w被B嵌入,并由解码器G重构回Iˆ。VQ-VAE的训练损失函数为
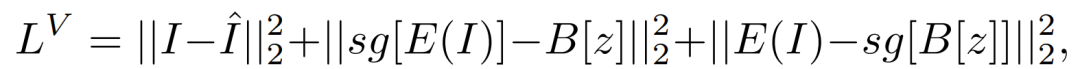
VQ-GAN增强了VQ-VAE的训练,增加了感知损失和GAN损失,以减轻I和Iˆ之间的精确约束,并专注于高层次的语义匹配。
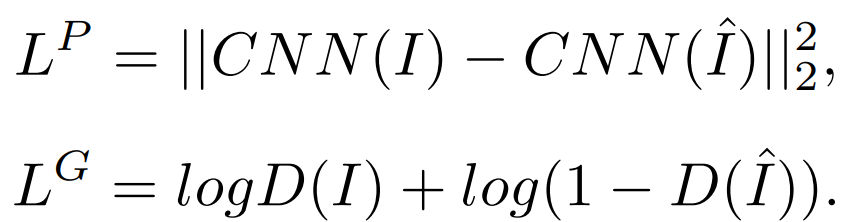
VQ-VAE训练后,B[z]为最终得到的图像表征。
对于视频,使用二维VQ-GAN对视频的每一帧进行编码,也可以产生时间上的一致性视频,并同时受益于图像和视频数据。由此生成的表征表示为R_h×w×s×d,其中,s表示帧的数量。
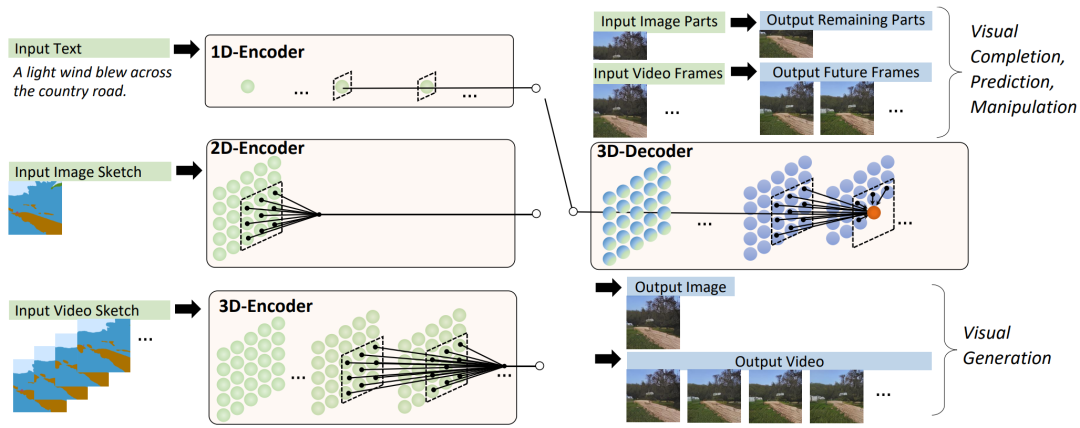
图11. NUWA的结构概述。它包含一个支持不同条件的自适应编码器和一个受益于图像和视频数据的预训练的解码器。对于图像补全、视频预测、图像操作和视频操作任务,输入的部分图像或视频被直接送入解码器
进一步,引入一个3D近距离关注(3DNA)机制,以考虑空间和时间轴的定位特性。3DNA不仅降低了计算的复杂性,而且还提高了生成结果的视觉质量。基于3DNA机制,引入一个3D encoder-decorder架构。为了在C的条件下生成一个目标Y,Y和C的位置编码由三个不同的可学习词汇更新,考虑到高度、宽度和时间轴:
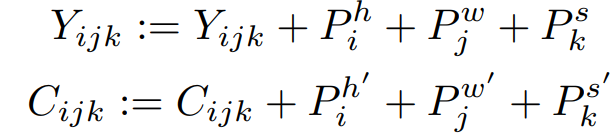
然后,将条件送入一个由L个3DNA层堆叠而成的编码器,以模拟自注意力的相互作用,其中第l层为:
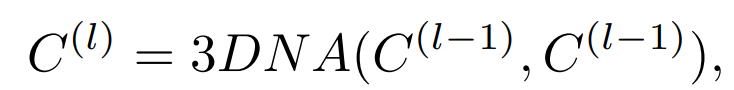
同样,解码器也是一个由L个3DNA层组成的堆栈。解码器同时计算生成结果的自注意力和生成结果与条件之间的交叉注意力:
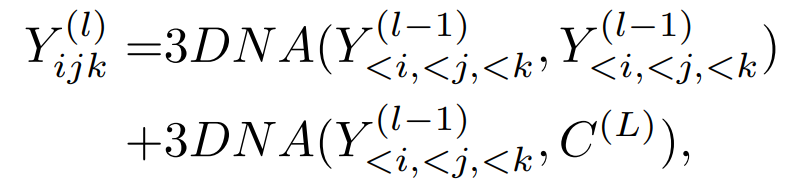
在三个任务上训练模型时(文本到图像( Text-to-Image,T2I)、视频预测( Video Prediction ,V2V)和文本到视频( Text-t,o-Video T2V)),训练目标为交叉熵函数,分别表示为三个部分:
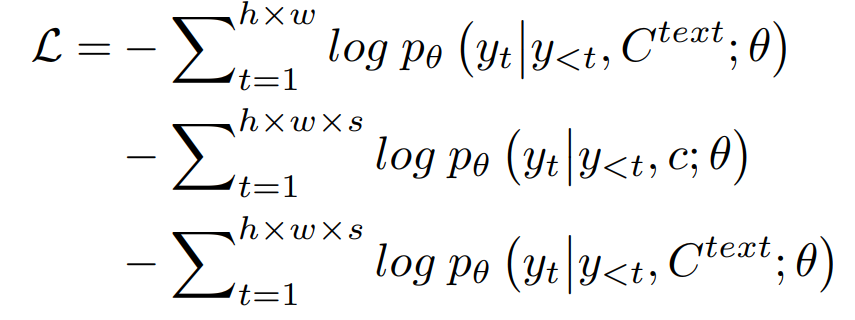
当前 SOTA!平台收录 NÜWA 共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
NÜWA |
前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/nuwa |
StyleGAN-v
常用于视频生成的Conv3D层有很多限制,比如计算成本相当高。规避对3D卷积的需求的一个方法是将视频作为一个具有时间坐标的连续信号。为了使这种方法奏效,必须解决几个问题:首先,现有的基于正弦/余弦的位置编码是循环的,不依赖于输入,这对视频是不利的,因为我们希望不同的视频在帧之间有不同的运动,而且视频不应该循环。其次,对完整视频的训练在计算上是很昂贵的,因此生成器必须能够从每个片段只有几帧的稀疏输入中学习。最后,鉴别器需要处理以不同时间距离采样的帧,以应对稀疏的输入问题。总之,StyleGAN-V不是自回归的,不使用Conv3D,而是在稀疏的输入上进行训练,并且对图像和视频使用单一的鉴别器而不是两个单独的鉴别器。
StyleGAN-v是在StyleGAN2的基础上建立的模型,并为视频合成重新设计其生成器和鉴别器网络,只做了最小的修改。在StyleGAN2的生成器上所做的唯一修改是将连续运动编码v_t与它的恒定输入张量连接起来。将这些特征按通道串联成一个全局视频描述符h,并据此预测真/假。以帧之间的时间距离δxi = ti+1 - ti作为D的条件,以使它更容易在不同的帧率上操作。
1)生成器结构。
生成器由三个子模块组成:内容映射网络Fc、运动映射网络Fm、Synthesis网络 S。Fc和S从StyleGAN2中照搬,只对S进行了修改,将运动编码v_t拼接到它的恒定输入张量上。通过对一些内容的噪声进行采样并通过映射网络得到视频的风格代码,从而生成一个样本视频。然后,对于每个时间段取样一个噪声向量序列,该序列对应于足够长的等距时间段以覆盖目标时间段,通过两个无填充的Conv1D层,并从输出序列中对应于目标时间段左右两个随机时间段的两个向量中计算出非循环位置编码。由此产生的运动编码被插入到生成器中。
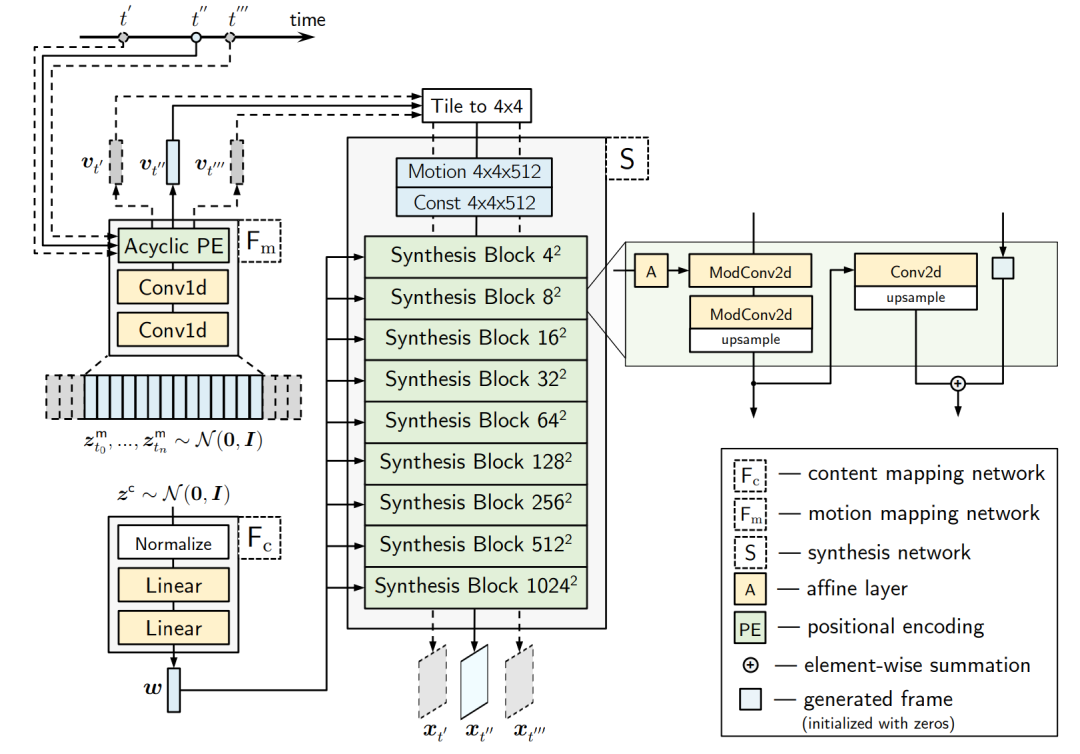
图12. 生成器架构:在StyleGAN2生成器的合成网络S之上所做的唯一修改是将运动编码与常量输入张量相连接。S使用内容编码w和运动编码v_t生成帧x_t
2)非周期性的位置编码。
StyleGAN-V的位置编码基本上是一个转换的正弦函数,具有可学习的波幅、周期、相位,首先预测来自目标时间段左侧的 "原始 "运动编码。然而,这本身就导致了不相干的运动编码,这就是为什么他们通过减去左右编码之间的线性插值来缝合,以便在每个离散的时间步长(0,1,2,...)将嵌入归零。这在一定程度上限制了位置编码的表现力,所以为了弥补这一点,将左右运动矢量之间的线性插值乘以一个可学习矩阵再加回去。它对向量进行归一化处理,然后用一个学习到的参数对其进行归一化处理。
3) 鉴别器结构。
鉴别器独立地从每一帧中提取特征,将结果连接起来,并从该张量中预测出一个单一的真/假逻辑。为了能够处理稀疏的输入,鉴别器以帧之间的时间距离为条件。这些距离通过位置编码进行预处理,然后通过MLP进行处理,并串联成一个单一的向量,用于调节每个鉴别器块第一层的权重,以及最后一层的投影条件(点乘)。
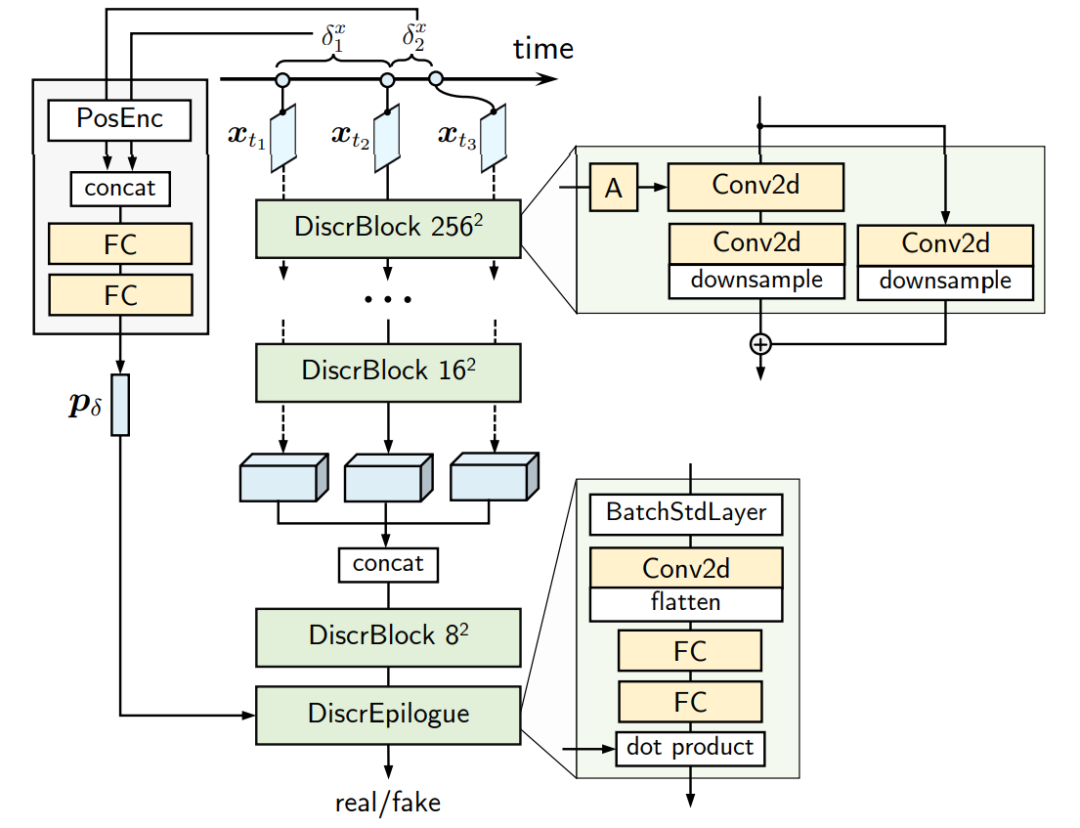
图13. 每段视频k=3帧的鉴别器结构。在StyleGAN2鉴别器的基础上所做的唯一变化是在16个分辨率下串联激活通道,并在帧间时间距离的位置嵌入上调节模型
4) 稀疏训练的隐含假设。
在一个视频中,帧的变化不大(人脸、延时摄影等)。因此,仅仅几帧就包含了足够的信息来了解整个视频的情况。例如,如果你看过两帧,你就已经看到了它们的全部。
当前 SOTA!平台收录 StyleGAN-v 共1个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| StyleGAN-v | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/stylegan-v |
Video Diffusion Models
生成时间上连贯的高保真视频是生成式模型研究的一个重要里程碑。Video Diffusion Models 是一个用于视频生成的扩散模型,它是标准图像扩散架构的自然扩展,能够从图像和视频数据中进行联合训练,从而减少mini-batch梯度的方差并加快优化速度。为了生成长的和更高分辨率的视频,Video Diffusion Models中引入了一种新的条件采样技术,用于空间和时间上的视频扩展,比以前提出的方法表现得更好。
在图像生成TOP模型的文章中,我们介绍过Unet,这是一个神经网络架构,构建为一个空间下采样通道,然后是一个空间上采样通道,与下采样通道的激活有 skip connections 。该网络是由二维卷积块层构建的。Video Diffusion Models将这种图像扩散模型架构扩展到视频数据,由固定数量的帧块给出,使用一种特殊类型的3D U-Net,在空间和时间上进行因子化。首先,修改了图像模型结构,将每个二维卷积改变为纯空间的三维卷积,例如,将每个3x3卷积改变为1x3x3卷积(第一个索引视频帧,第二个和第三个索引空间高度和宽度)。每个空间注意力块中的注意力仍然是对空间的注意力。也就是说,第一轴被当作一个batch axis。其次,在每个空间注意力块之后,插入一个时间注意力块,对第一个轴进行注意力,并将空间轴视为批处理轴。在每个时间注意力块中使用相对位置嵌入,以便网络能够以不需要视频时间的绝对概念的方式区分帧的排序。图24中可视化了模型的结构。
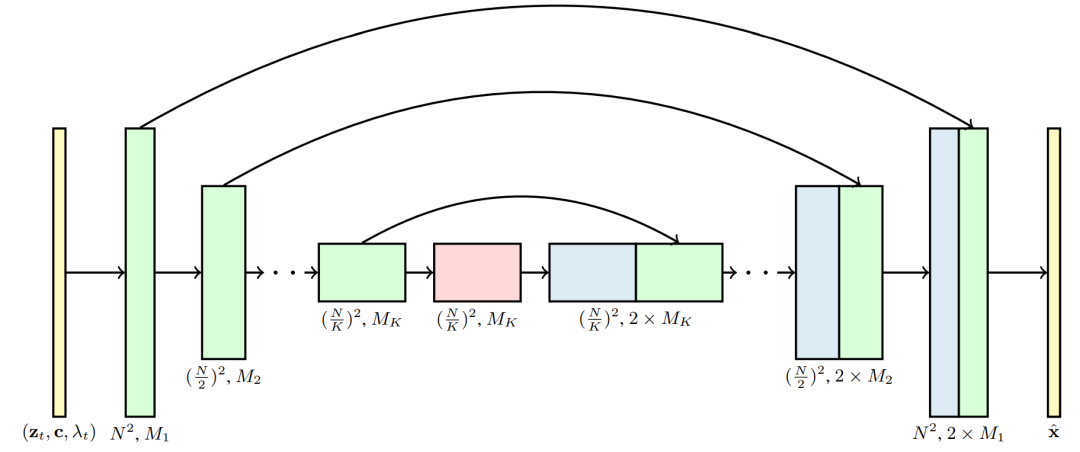
图24. 扩散模型中xˆθ的三维U-Net结构。每个区块代表一个4D张量,其轴标记为帧×高×宽×通道,以时空因子的方式处理。输入为噪声视频z_t、调节c和log SNR λ_t。下采样/上采样块通过每个K块调整空间输入分辨率的高度×宽度,系数为2。通道数用通道乘法器M1、M2、...、MK指定,上采样通道与下采样通道有skip connections连接
当前 SOTA!平台收录 Video Diffusion Models 共2个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| Video Diffusion Models | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/video-diffusion-models |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。


