CopyNet、SeqGAN、BERTSUM…你都掌握了吗?一文总结文本摘要必备经典模型(一)
机器之心专栏
本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 2 期进行连载,共介绍 17 个在文本摘要任务上曾取得 SOTA 的经典模型。
第 1 期:CopyNet、SummaRuNNer、SeqGAN、Latent Extractive、NEUSUM、BERTSUM、BRIO
第 2 期:NAM、RAS、PGN、Re3Sum、MTLSum、KGSum、PEGASUS、FASum、RNN(ext) + ABS + RL + Rerank、BottleSUM
您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| CopyNet | https://sota.jiqizhixin.com/models/models/286c465a-178c-4106-8436-7130accccdf1 收录实现数量:2 支持框架:TensorFlow、PyTorch |
Incorporating Copying Mechanism in Sequence-to-Sequence Learning |
| SummaRuNNer | https://sota.jiqizhixin.com/models/models/2a859c7f-b677-45d1-8bef-2c743efbff55 收录实现数量:1 支持框架:PyTorch |
SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documen |
| SeqGAN | https://sota.jiqizhixin.com/models/models/eed884d0-4497-43f8-99b8-22d418455bac 收录实现数量:22 支持框架:TensorFlow、PyTorch |
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient |
| Latent Extractive | https://sota.jiqizhixin.com/models/models/0dab4348-ff0f-48af-847e-87687e2b4fb3 | Neural latent extractive document summarization |
| NEUSUM | https://sota.jiqizhixin.com/models/models/6ffe7d4b-c16f-4058-991b-3fb7c785c45b 收录实现数量:1 支持框架:PyTorch |
Neural Document Summarization by Jointly Learning to Score and Select Sentences |
| BERTSUM | https://sota.jiqizhixin.com/models/models/e27d5e70-18ab-4576-9299-26bad528c4b4 收录实现数量:15 支持框架:PyTorch、TensorFlow |
Text Summarization with Pretrained Encoders |
| BRIO | https://sota.jiqizhixin.com/models/models/7de76bc7-f55c-465c-9a81-ff175a623a6d 收录实现数量:1 支持框架:PyTorch |
BRIO: Bringing Order to Abstractive Summarization |
文本摘要可以看做是一种信息压缩技术,具体是指利用技术从单个文本或多个文本(文本集合)中抽取、总结或提炼要点信息,以概括展示原始文本(集)中的主要信息。 在互联网快速发展的现代社会,文本摘要的作用越来越重要,可以帮助人们从海量数据中快速发现所需要的信息。 文本摘要成为了自然语言处理(NLP)领域的一项重要技术。
传统的文本摘要可以分为抽取式摘要和生成式摘要两种方法。抽取式摘要是通过抽取拼接源文本中的关键句子来生成摘要,优点是不会偏离原文的信息,缺点是有可能提取信息错误,或者出现信息冗余、信息缺失。生成式摘要则是系统根据文本表达的重要内容自行组织语言,对源文本进行概括,整个过程是一个端到端的过程,类似于翻译任务和对话任务,因此,生成式摘要方法可以吸收、借鉴翻译任务和对话任务的成功经验。与传统方法对应的,应用于文本摘要的神经网络模型也有抽取式模型、生成式模型以及压缩式模型三类。其中,抽取式模型主要是将问题建模为序列标注和句子排序两类任务,包括序列标注方法、句子排序方法、seq2seq三种;生成式模型则主要是以seq2seq、transformer为基础的引入各类辅助信息的生成式模型;压缩式模型主要是基于information bottleneck的模型,也可称为是抽取式和生成式混合的模型。
第一,抽取式模型的核心思想是:为原文中的每一个句子打一个二分类标签(0 或 1),0 代表该句不属于摘要,1 代表该句属于摘要,最终由所有标签为 1 的句子进行排序后生成摘要。这种方法的首要要求就是将自然语言转化为机器可以理解的语言,即对文本进行符号数字化处理,为了能表示多维特征,增强其泛化能力,可以引入向量的表征形式,即词向量、句向量。基于seq2seq的抽取式模型的文本摘要需要解决的问题是从原文本到摘要文本的映射问题。摘要相对于原文具有大量的信息损失,而且摘要长度并不会依赖于原文本的长度,所以,如何用简短精炼的文字概括描述一段长文本是seq2seq文本摘要需要解决的问题。
第二,生成式模型主要是依托自然语言理解技术,由模型根据原始文本的内容自己生成语言描述,而非提取原文中的句子。生成式模型的工作主要是基于seq2seq模型实现的,通过添加额外的attention机制来提高其效果。此外,还有一些模型以自编码为框架利用深度无监督模型去完成生成式摘要任务。再者,还可以引入GPT等预训练模型做fine-tune,改进摘要的生成效果。
第三,压缩式模型则是先通过某种方法将源文档做一个压缩,得到一个长度较为合适的文本。然后以压缩后的文本为目标,训练生成式模型最终得到目标模型。压缩式模型也可以看作是抽取式模型和生成式模型的结合。我们在这篇文章介绍文本摘要中必备的TOP模型,介绍是根据不同类型的模型分组进行的,同一类别的模型介绍则是按照模型提出的时间顺序来完成的。
一、抽取式摘要模型
1.1 CopyNet
CopyNet目标是解决seq2seq模型的复制问题,即输入序列中的某些片段被选择性地复制到输出序列中。在人类的语言交流中也可以观察到类似的现象。例如,人类倾向于在对话中重复实体名称或甚至长短语。在Seq2Seq中复制的挑战是需要新的机器来决定何时执行该操作,即选择性的将输入序列中的某些片段复制到输出序列中。CopyNet可以很好地将解码器中的常规字生成方式与新的copy机制结合起来,后者可以在输入序列中选择子序列,并将它们放在输出序列的适当位置。
从认知的角度看,copy机制与死记硬背有关,只需要较少的理解就能保证较高的字面保真度。从建模的角度来看,copy的操作更加僵化和符号化,使得它比soft attention机制更难整合到一个完全可区分的神经模型中去。如图1所示,CopyNet是一个编码器-解码器。源序列被编码器转换为表征,然后被解码器读取以生成目标序列。
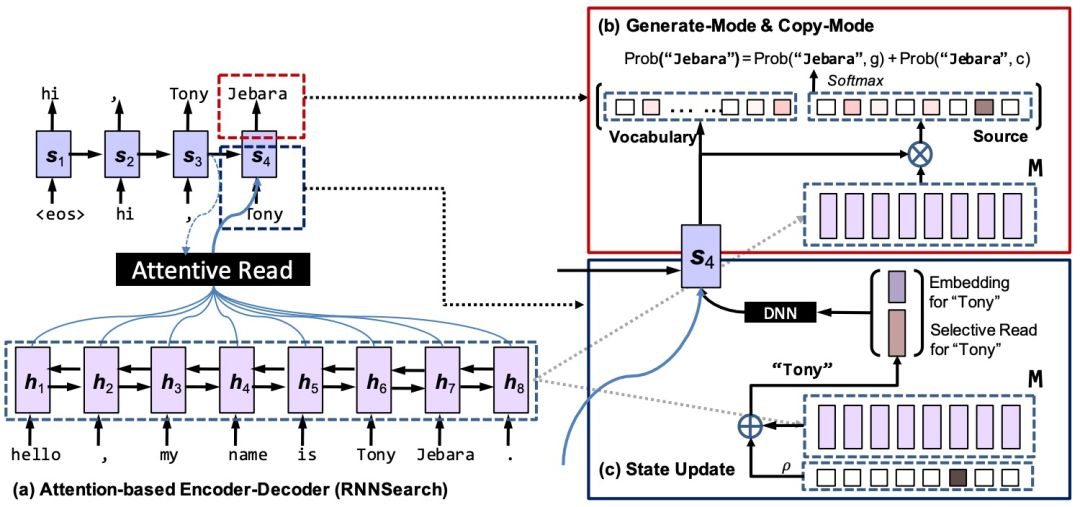
图1 CopyNet架构
编码器(encoder)部分是一个标准的双向 LSTM,每一个时间步长对应一个输入。一般会先对字(词)进行one hot编码,然后去查找嵌入,输入的是embedding size大小的向量。如图1所示,h_t 对应的是每个时间步长的 encoder 输出,代表了输入的一些高维度特征(隐状态)。对h_t 进行变化后将结果送给解码器(decoder)解码,一般来说送的是最后一个时间步长的输出。编码器的输出是隐状态M。
解码器是一个读取M并预测目标序列的RNN。解码器与标准RNN的区别包括:1)预测。COPYNET根据两种模式的混合概率模型来预测单词,即生成模式和复制模式,后者从源序列中挑选单词。2)状态更新:时间t-1的预测词被用于更新t的状态,但COPYNET不仅使用它的词嵌入,而且还使用它在M中相应的特定位置的隐藏状态。3)读取M:COPYNET对M进行 "选择性读取",这导致了基于内容的寻址和基于位置的寻址的强大混合。解码器有两个模式,1.生成模式。2. copy模式。
对于decoder,作者并没有向传统的decoder那样用softmax求概率,在这里作者用了两个词表X,V. V 表示频率大的topK的词,和一般选取的词表方法一样。而X则表示所有在源端出现一次的词,X和V有交集,如下图。
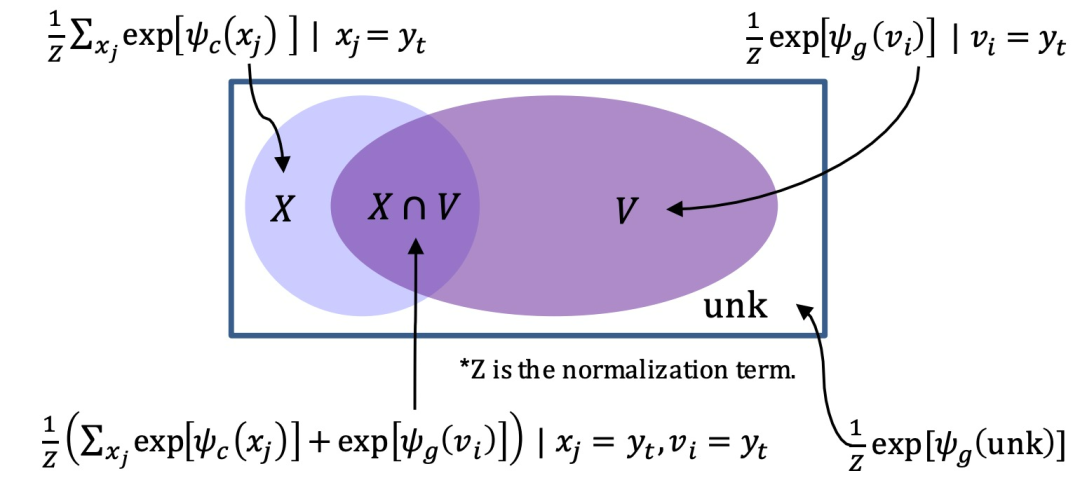
图2 作为4类分类器的解码概率的说明
给定解码器RNN在时间t的状态s_t和M,下述概率公式生成任何目标词y_t的概率:
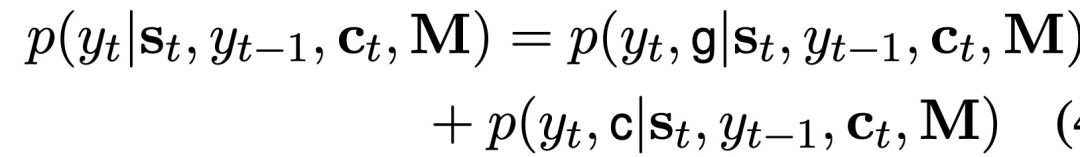
其中g代表生成模式,c代表copy模式。这两种模式的概率分别为:
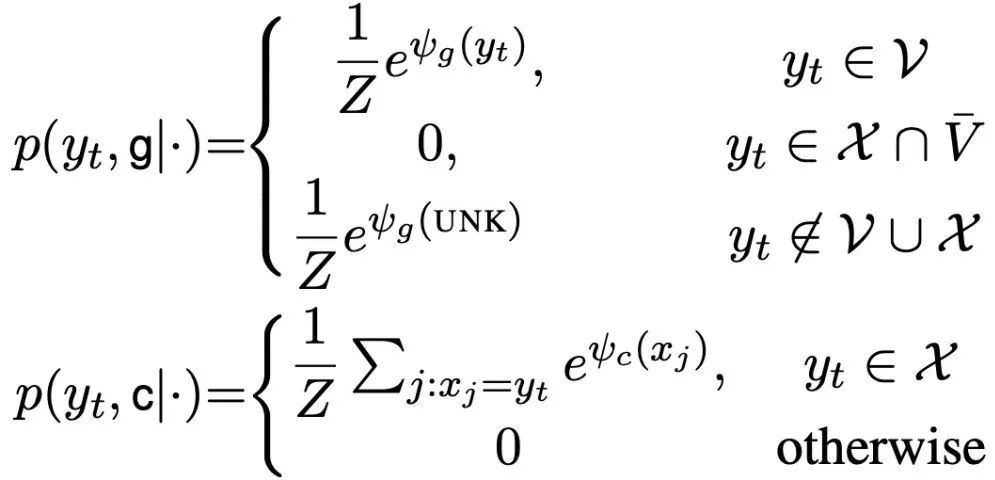
其中,对应于生成模式,与通用RNN编码器-解码器中的评分函数相同,使用经典的线性映射;对应于Copy模式,Copy某词x_i的概率为:
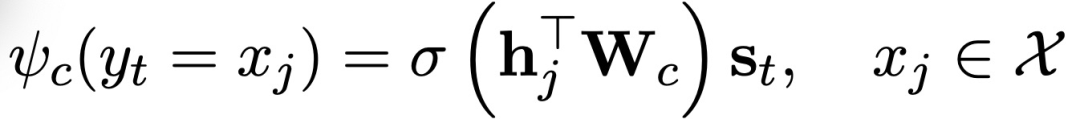
其中,W_c和σ表征非线性激活函数,可以帮助在同一语义空间中投射s_t和h_j。
此外,进一步对传统的解码器的输入进行改进。除了输入s_t-1和y_t-1、c_t ,作者对y_t-1进行改进,除了自身的嵌入外,还加入了类似attention的机制,对M进行加权求和,并且与y_t-1的向量合并,共同作为输入,这样将包含在M中的位置信息以加权和的方式输入编码器,这种改进对于copy机制选择从哪里开始copy有很大的帮助,即图1中蓝色框内的State Update。
当前 SOTA!平台收录CopyNet共 2 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
CopyNet |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/286c465a-178c-4106-8436-7130accccdf1 |
1.2 SummaRuNNer
SummaRuNNer是一种有监督的抽取式文本摘要模型,具体是一种基于递归神经网络RNN的抽取式摘要的序列模型。该模型的优点是非常容易解释,因为它允许将其预测按照抽象的特征(如信息内容、突出性和新颖性)进行可视化分解。此外,通过对提取模型进行抽象化训练,它可以单独对人类产生的参考文献进行训练,消除了对句子级提取标签的需要。SummaRuNNer的具体结构见图3,它是一个基于两层RNN的序列分类器:底层在每个句子中的word level上工作,而顶层运行在sentence level。图3中的双指向箭头表示双向RNN。1和0的顶层是基于sigmoid的分类层,它决定了每个句子是否属于摘要。每句话的决定取决于第二句。
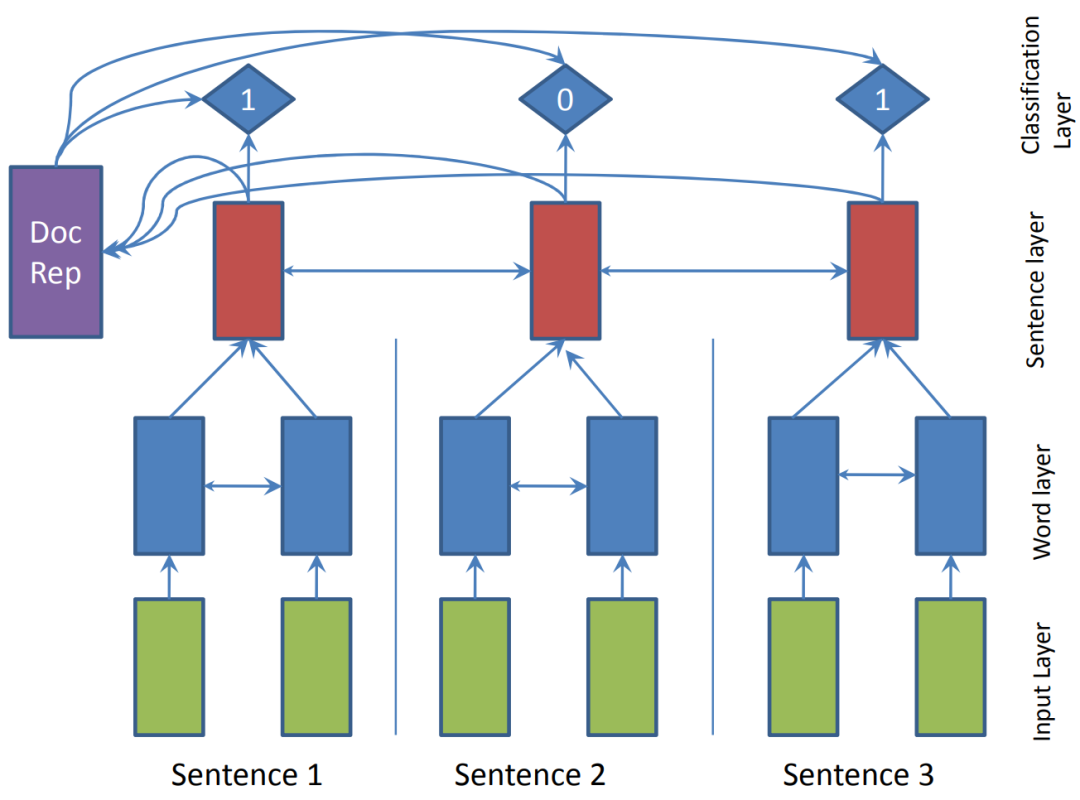
图3 SummaRuNNer。一个基于两层RNN的序列分类器:底层在每个句子中的word level上运行,而顶层在sentence level中运行。双箭头表示一个双向的RNN。带有1和0的顶层是基于sigmoid激活的分类层,决定每个句子是否属于摘要。每个句子的决定取决于该句子的内容丰富程度、它在文件中的突出性、它在累积的摘要表征中的新颖性以及其他位置特征
在这项工作中,作者将抽取式总结视为一个序列分类问题,其中,按原始文件的顺序访问每个句子,并作出二元决定(考虑到以前作出的决定),即是否应将其列入在摘要中。使用基于GRU的递归神经网络作为序列分类器的基本构件。GRU-RNN是一个具有两个门的递归网络,u称为更新门,r为复位门,可以用以下公式描述:
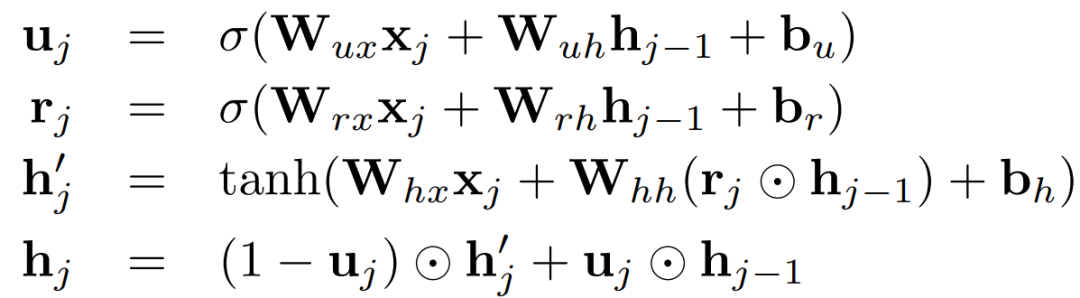
其中W和b是GRU-RNN的参数,h_j是时间步长j的实值隐状态向量,x_j是对应的输入向量,⊙表示哈达玛德积。RNN的第一层运行在Word level,并计算隐状态表征。根据当前单词嵌入和先前的隐状态,顺序地在每个单词位置进行调整。Word level还使用了另一个RNN,它从最后一个word向后运行到第一个,这样的正反向RNN称为双向RNN。第二层RNN运行在sentence level,双向网络,并接受双向word-level RNN的平均池化与隐状态链接作为输入,即文档中的sentence level作为编码。整个文本的表征被建模为双向句子级RNN的平均集合隐状态的非线性变换,如下所示:
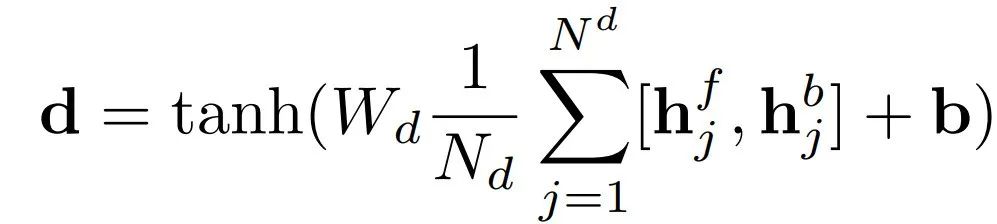
其中(h_j)^f和(h_j)^b分别是对应于前向和后向sentence level RNN的第j句的隐状态,N_d是文本中的句子数量,'[]'代表矢量连接。对于分类,每个句子都会被重新访问,在第二遍中,逻辑层会对该句子是否属于摘要做出二元决定,如下式所示:
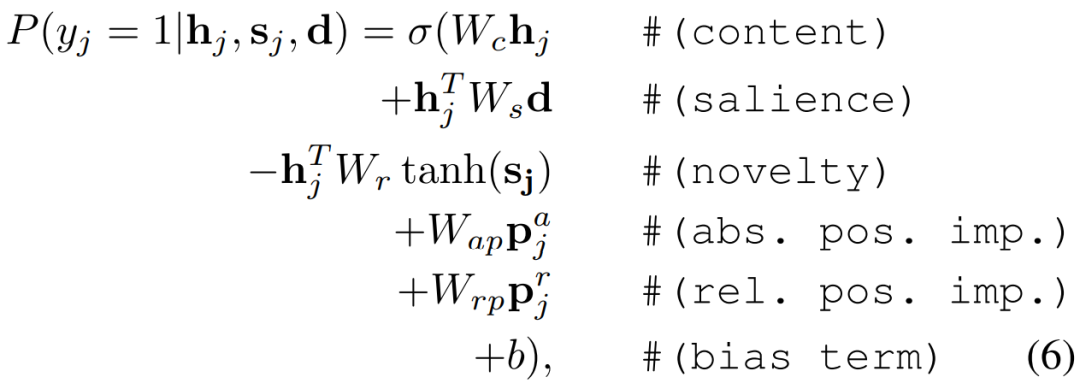
其中,y_j是一个二元变量,表示第j个句子是否是摘要的一部分。句子的表征h_j是由双向句子级RNN第j个时间步长的联合隐状态的非线性变换得到的。s_j是摘要在第j个句子位置的动态表征。
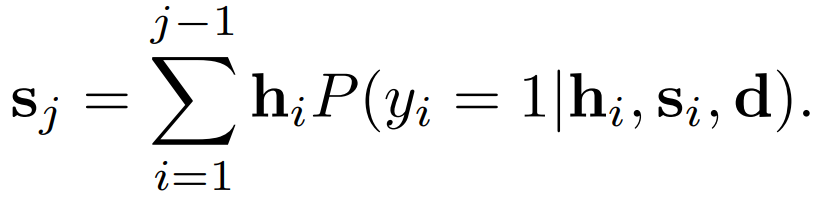
当前 SOTA!平台收录SummaRuNNer共 1 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
SummaRuNNer |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/2a859c7f-b677-45d1-8bef-2c743efbff55 |
1.3 SeqGAN
SeqGAN将GAN引入到序列标注中,整个算法在GAN的框架下,结合强化学习来做文本摘要生成。这是第一个扩展GANs以生成离散标记序列的工作。生成式对抗网(GAN)使用判别模型来指导生成式模型的训练,在生成实值数据方面取得了相当大的成功。然而,当目标是生成离散的标记序列时,GAN有局限性。一个主要原因是,生成模型的离散输出使得梯度更新很难从判别模型传递到生成模型。另外,判别模型只能评估一个完整的序列,而对于一个部分生成的序列,一旦整个序列生成,要平衡其当前的分数和未来的分数是不难的。本文提出了一个序列生成框架,称为SeqGAN,以解决这些问题。
SeqGAN将数据发生器建模为强化学习(RL)中的随机策略,通过直接执行梯度策略更新绕过了发生器的分类问题。强化学习的奖励信号来自于对完整序列进行判断的GAN判别器,并通过蒙特卡洛搜索传递回中间的状态动作步骤。
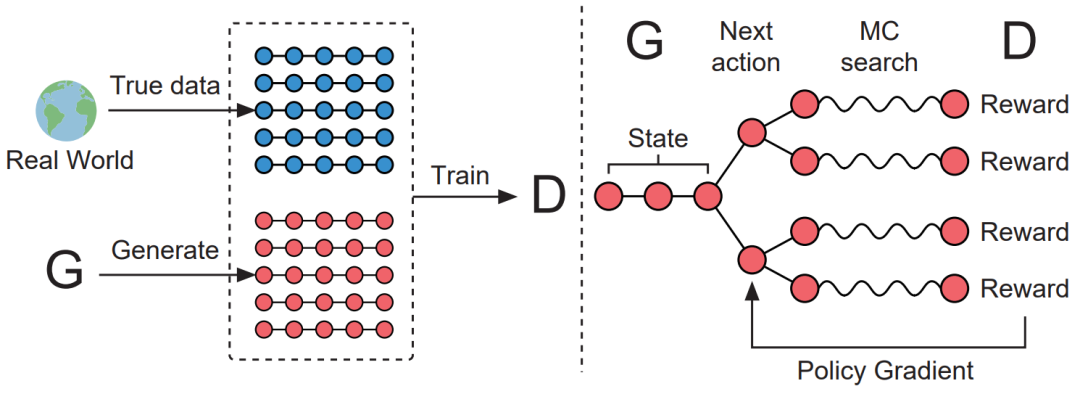
图4 SeqGAN图示。左图:D通过真实数据和G生成的数据进行训练。G通过策略梯度进行训练,最终的奖励信号由D提供,并通过蒙特卡洛搜索传递回中间的行动值
如图4所示,左图为GAN网络训练的步骤1,即根据真实样本和G生成的伪造样本训练判别器D网络,这里的D网络用的CNN实现。G通过策略梯度进行训练,最终的奖励信号由D提供,并通过蒙特卡洛搜索传递回中间的行动值。右图为GAN网络训练的步骤2,根据D网络回传的判别概率通过增强学习更新G网络,这里的G网络用的LSTM实现。
G网络的更新策略是增强学习,而增强学习的三个要素点状态state,action,reward。本文state指的是当前时间步长之前的解码结果,action指的当前待解码词,D网络判别伪造数据的置信度即为奖励reward,伪造数据越逼真则相应奖励越大,但该奖励是总的奖励,分配到每个词选择上的reward则采用了以下的近似方法:
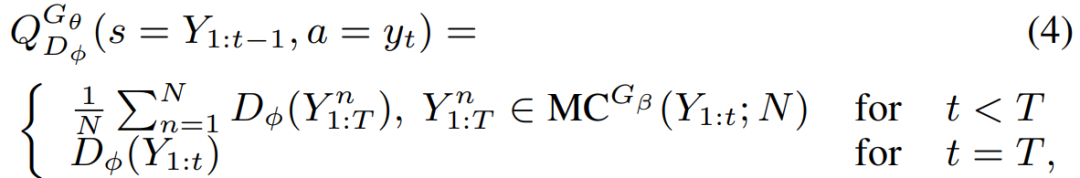
完整的算法流程如Algorithm 1。首先,随机初始化G网络和D网络参数。其次,通过MLE预训练G网络,目的是提高G网络的搜索效率。然后,通过G网络生成部分负样预训练D网络。再然后,通过G网络生成sequence用D网络去评判,得到reward。训练目标是最大化识别真实样本的概率,最小化误识别伪造样本的概率:
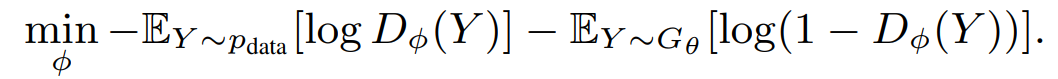
最后,循环以上过程直至收敛。

当前 SOTA!平台收录 SeqGAN 共 22 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
SeqGAN |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/eed884d0-4497-43f8-99b8-22d418455bac |
1.4 Latent Extractive
隐变量提取(latent extractive)的相关工作发表在ACL2018中,是第一个提出把句子作为隐变量的抽取式摘要模型,其思路是把句子对应的label视为句子的二元隐变量(即0和1),不是最大化每个句子到训练数据(gold label)的可能性,而是最大化生成摘要是这个人工摘要整体的可能性。这与序列标注的方法的思路有着根本性的不同。从模型结构角度来讲,隐变量提取采用的是经典的深层双向LSTM网络+强化学习算法,架构方面改进不大,其主要贡献在于将句子看作隐变量的思想。
图5 隐变量提取模型。sent_i是文件中的一个句子,sum_sent_i是文件的gold摘要中的一个句子
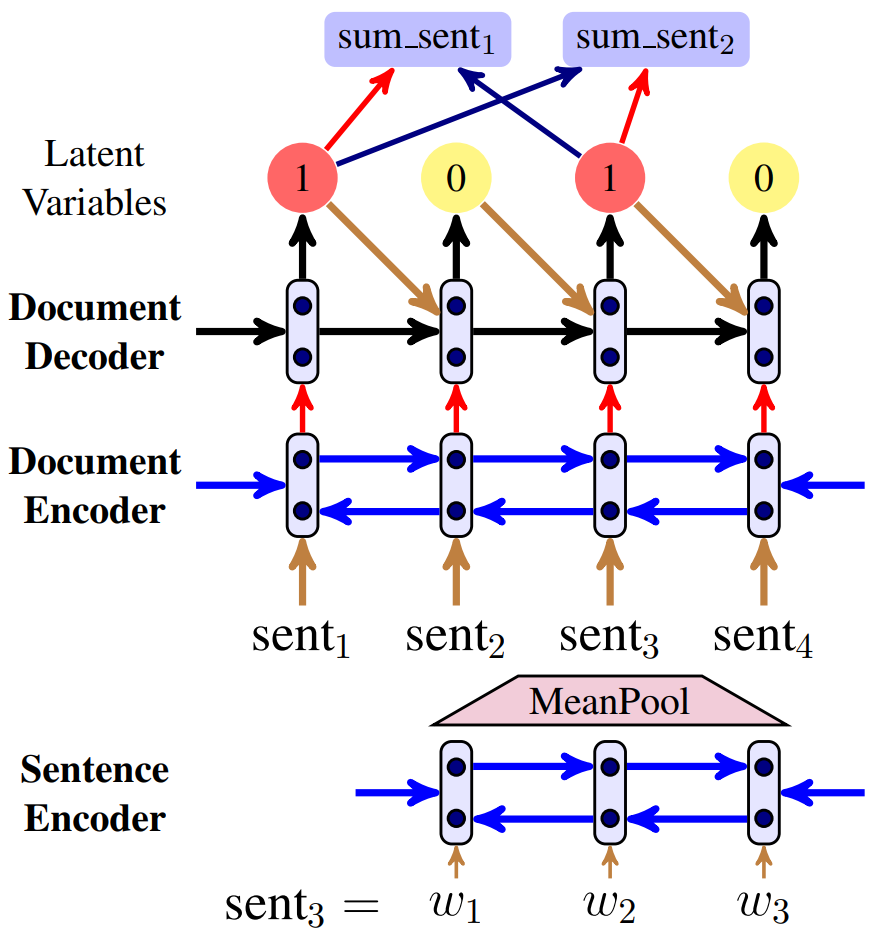
如图5所示,提取模型有三个部分:一个句子编码器,将每个句子转换为一个向量;一个文档编码器,根据周围的句子作为上下文学习句子表征;一个文本解码器,根据文本编码器学习的表征预测句子标签。整个模型和SummaRunner非常相似,都是双层双向LSTM网络最后加个softmax。
然后,训练一个句子压缩模型,将提取模型选择的句子映射到摘要中的句子。该模型可用于评估所选句子相对于摘要的质量(即其相似程度),或根据摘要的风格重写一个提取的句子。该模型是一个标准的基于注意力机制的seq2seq架构,使用的数据集和抽取式摘要模型使用的数据集一样,使用ROUGE度量来衡量句子间的相似度。压缩模型的最终输出是从原文本"原句"到摘要句子的条件概率。
最后,使用隐变量做抽取式摘要。使用隐变量提取模型来生成隐变量的概率分布:
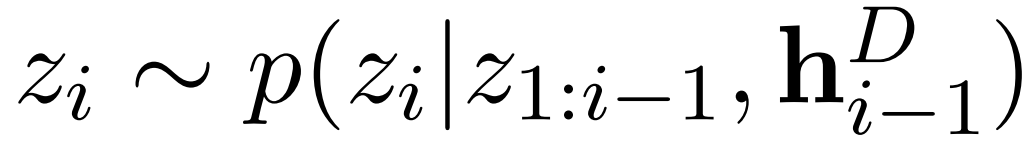
即根据前面i − 1个句子的评估结果,结合模型句子层的中间隐状态,做出判断: 当前句子是否应该纳入最后的摘要中。使用压缩模型估计给定文档句子C_k的摘要句H_l的可能性,并计算归一化概率s_kl:
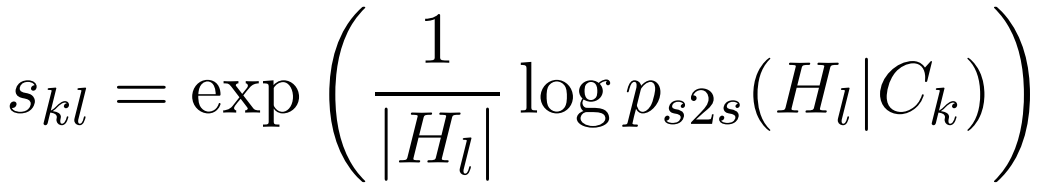
作者做了个假设,对每一条原文本中的句子,只对应一条摘要中的句子,举例: 摘要句子为H_l ,则对应于文档中的句子s_kl。用下面的公式表征用原文本中的句子取代摘要中这条句子的概率:
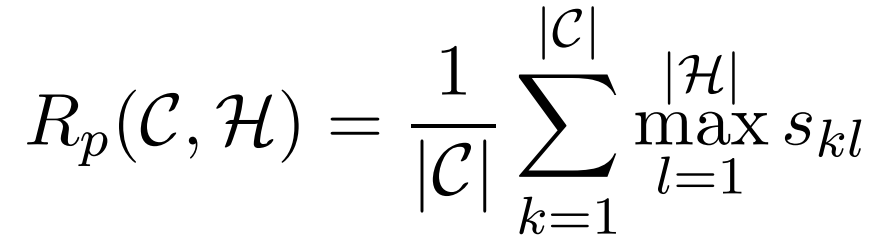
这可以视为摘要对应于文档的召回率(recall),准确率用R_p(C,H)表示,最终的R(C,H)计算为:
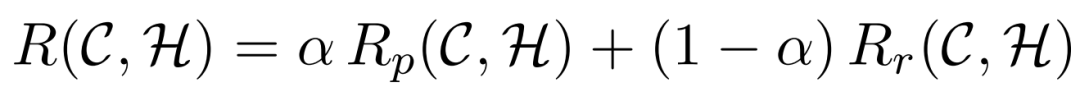
| 模型 | SOTA!平台模型详情页 |
|---|---|
Latent Extractive |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/0dab4348-ff0f-48af-847e-87687e2b4fb3 |
1.5 NEUSUM
NEUSUM属于基于Seq2Seq的抽取式方法。句子评分和句子选择是抽取式文本摘要系统的两个主要步骤,以往的抽取式摘要,句子评分和选择是独立的两个部分。NEUSUM则训练一个新的端到端神经网络框架,将评分以及选择联合在一起同时将他们的信息关联起来取得了较好的成绩。它首先用分层编码器读取文本中的句子,以获得句子的表征。然后,通过逐一提取句子来建立输出摘要。与之前的方法不同,NEUSUM将选择策略整合到评分模型中,直接预测之前选择的句子的相对重要性。这样的好处是:a)句子评分可以意识到以前选择的句子;b)可以简化句子选择,因为评分函数被学习为ROUGE分数增益。
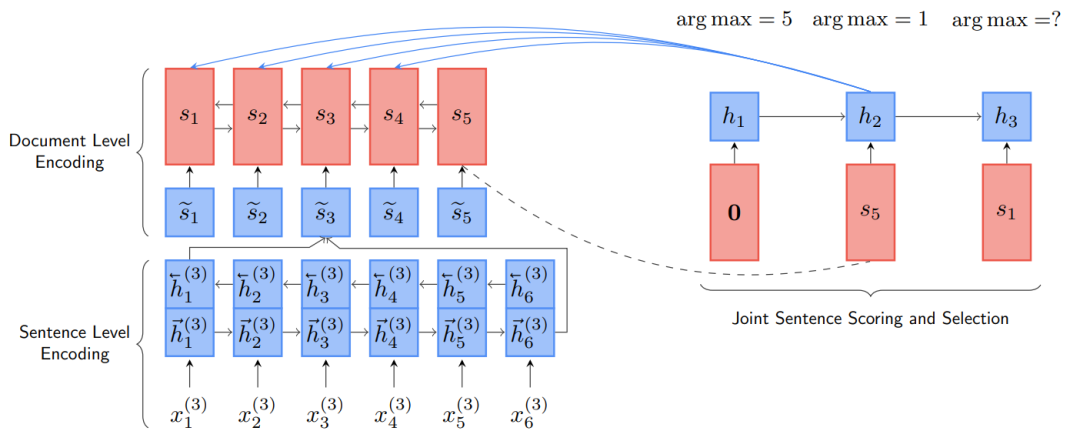
图6 NEUSUM模型概述。在前两步提取S_5和S_1。在第一步,给模型输入一个零向量0,代表空的部分输出摘要。在第二和第三步,将先前选定的句子S_5和S_1的表征,即s_5和s_1,送入提取器RNN。在第二步,该模型只对前4个句子进行评分,因为第5个句子已经包含在部分输出摘要中
NEUSUM模型架构如图6所示。首先将原始文本通过一个层次的Encoder(句子级和文档级)。将输入的文本D的每个句子S_j输入一个双向GRU网络(初始状态设为0),得到句子的向量表征。将sentence level编码后的表征作为输入传入另一个双向GRU网络,得到双向的隐状态,将隐状态合并后得到每个句子的文本级表征s_i。
考虑到最后抽取的句子Sˆt-1,句子抽取器通过对剩余的文本句子打分来决定下一个句子Sˆt。为了在考虑到文本句子的重要性和部分输出摘要的情况下对其进行评分,该模型应该有两个关键能力:1)记住以前选择的句子的信息;2)根据以前选择的句子和剩余句子的重要性对剩余的文本句子进行评分。因此,采用另一个GRU作为递归单元来记忆部分输出摘要,并使用多层感知器(MLP)来对文本句子进行评分。具体的,GRU将上文中最后提取的句子的文本级表征s_i作为输入,产生其当前的隐状态h_t。句子评分器是一个两层的MLP,需要两个输入向量,即当前的隐状态h_t和句子表征向量s_i,以计算句子S_i的得分δ(S_i):
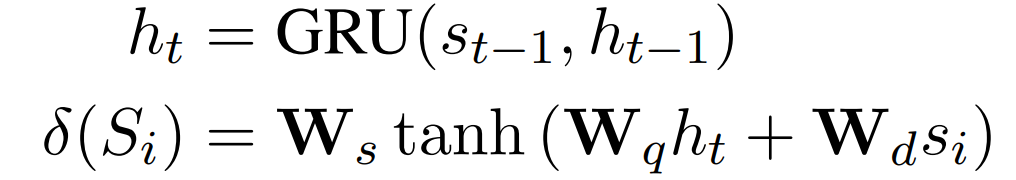
在抽取第一句话时,用一个带有tanh激活函数的线性层初始化GRU的隐状态h_0:
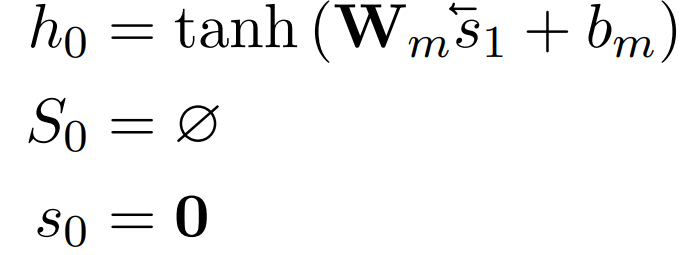
有了所有句子在时间t的得分,我们选择具有最大增益得分的句子:
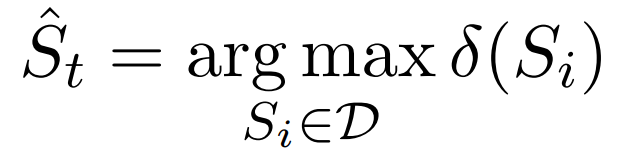
当前 SOTA!平台收录 NEUSUM 共 1 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
NEUSUM |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/6ffe7d4b-c16f-4058-991b-3fb7c785c45b |
1.6 BERTSUM
应用于抽取式文本摘要生成的传统深度学习方法(上述1.1-1.5介绍到的模型)一般采用LSTM或GRU模型进行重要句子的判断与选择,而本文采用预训练语言模型BERT进行抽取式摘要。BERTSUM首次将BERT用于摘要抽取中,充分利用了BERT预训练产生的先验知识。
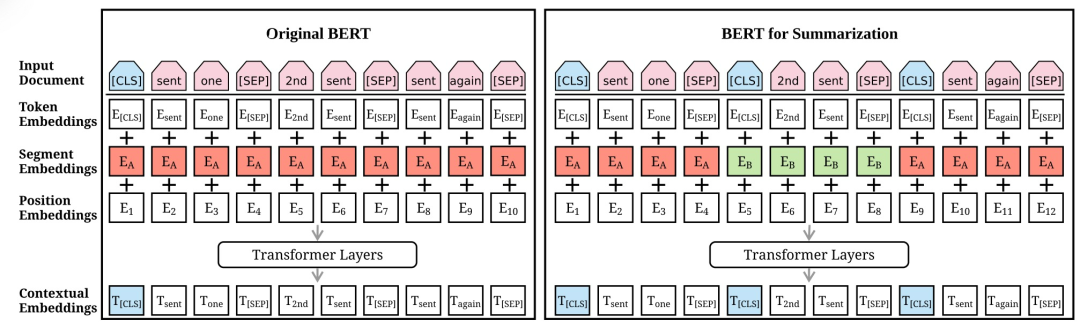
图7 原始BERT模型(左)和BERTSUM(右)的结构
BERTSUM的结构是比较简单的,基本就是将BERT引入到文本摘要任务中,模型主要由句子编码层和摘要判断层组成,其中,句子编码层通过BERT模型获取文本中每个句子的句向量编码,摘要判断层通过三种不同的结构进行选择判断,为每个句子进行打分,最终选取最优的top-n个句子作为文本摘要。如图7所示,上面的序列是输入文本,然后是每个token的三种嵌入的总和。求和后的向量被用作几个双向转化器层的输入嵌入,为每个token生成上下文向量。BERTSUM通过插入多个[CLS]符号来学习句子表征,并使用区间分割嵌入(用红色和绿色说明)来区分多个句子,从而扩展了BERT。
句子编码层。由于BERT模型MLM预训练机制,使得其输出向量为每个token的向量;即使分隔符可以区分输入的不同句子,但是仅有两个标签(句子A或句子B),与抽取式摘要需要分隔多个句子大不相同;因此对BERT模型的输入进行了修改:1)将文本中的每个句子前后均插入[CLS]和[SEP],并将每个句子前的[CLS]token经由模型后的输出向量,作为该句子的句向量表征。2)采用Segment Embeddings区分文本中的多个句子,将奇数句子和偶数句子的Segment Embeddings分别设置为EA和EB。
摘要判断层。从句子编码层获取文本中每个句子的句向量后,构建了3中摘要判断层,以通过获取每个句子在文本级特征下的重要性。对于每个句子sen_i,计算出最终的预测分数Y^i,模型的损失是Y^i相对于gold标签Yi的二元交叉熵。具体到预测分数阶段,可以有如下几种选择:
1. Simple Classifier:仅在BERT输出上添加一个线性全连接层,并使用一个sigmoid函数获得预测分数,如下:

2. Transformer:在BERT输出后增加额外的Transformer层,进一步提取专注于摘要任务的文本级特征,如下:
最后仍然接一个sigmoid函数的全连接层(simple classifier)。
3. LSTM:如果在BERT输出增加额外的LSTM层,则可以进一步提取专注于摘要任务的文本级特征。当然,最后仍然接一个sigmoid函数的全连接层(simple classifier)。
当前 SOTA!平台收录 BERTSUM 共 15 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
BERTSUM |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/e27d5e70-18ab-4576-9299-26bad528c4b4 |
1.7 BRIO
BRIO最大创新之处是在常见的seq2seq框架下,加一个 evaluation model 评估模型。在文本摘要抽取任务上,对生成的候选序列进行排序,并以对损失的方式将排序过程间接融于到优化目标中,形成一个多任务学习框架,促使模型偏向非固定的目标分布训练方式,缓解曝光偏差的问题。下图显示 seq2seq 架构中使用的传统 MLE 损失与无参考对比损失之间的差异:
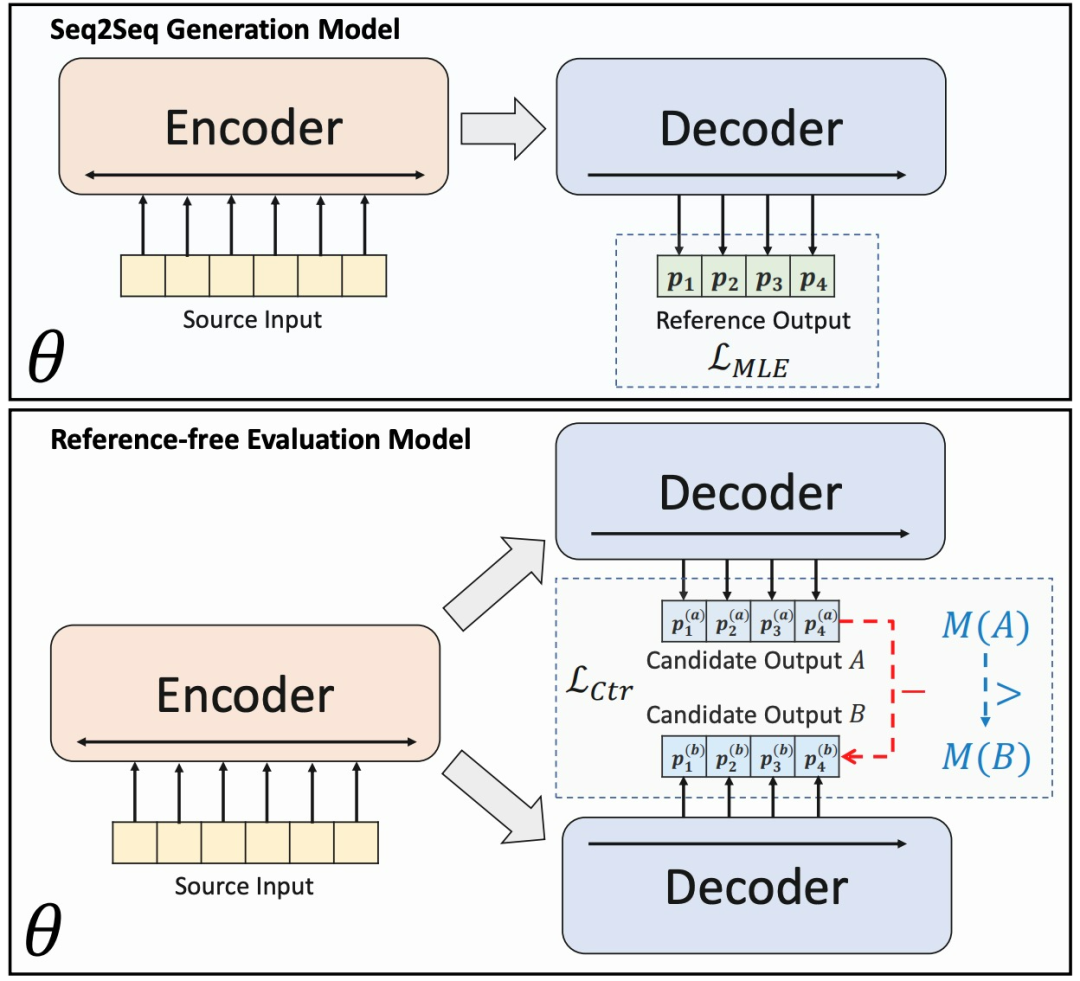
图8 BRIO中的MLE损失(L_MLE)和对比性损失(L_Ctr)的比较。MLE假设了一个确定性的分布,在这个分布中,参考摘要得到了所有的probability mass。BRIO假设了一个非决定性的分布,在这个分布中,系统生成的摘要也根据其质量得到probability mass。对比性损失鼓励候选摘要的模型预测概率的顺序与实际的质量指标M相协调,摘要将根据该指标进行评估。我们赋予抽象化模型以双重角色—一个单一的模型可以同时作为生成模型和无参考价值的评价模型
通常使用最大似然估计(Maximum Likelihood Estimation, MLE)损失来训练序列模型。但是BRIO认为我们使用的损失函数将把一个本质上可能有多个正确输出(非确定性)的任务的“正确”输出(确定性)赋值为零。训练和推理过程之间也存在差异,在生成过程中模型是基于自己之前的预测步骤,而不是目标摘要。在推理过程中,当模型开始偏离目标(并变得更加混乱)时,就会造成更严重的偏差。
BRIO引入了一个合并评价指标的想法,这样模型就可以学习如何对摘要进行排序。这是通过使用多样化Beam Search和生成多个候选来完成的。具体,这是一个两阶段的工作:
1)使用一个预先训练的网络(BART)生成候选人;
2)从中选择最好的一个。
对比性损失负责指导模型学习如何对给定文本的多个候选者进行排名。它将在微调过程中用于改进序列级别的协调。论文也说明了仅针对对比性损失的微调模型不能用于生成摘要,因此将上述损失的加权值与交叉熵(xnet)损失相加,以确保token级别的预测准确性。如图8, BRIO被描述为“双重角色”模型,但它其实是一个单一的模型,既可以生成摘要,也可以评估生成的候选者的质量。
当前 SOTA!平台收录 BRIO 共 1 个模型实现资源。
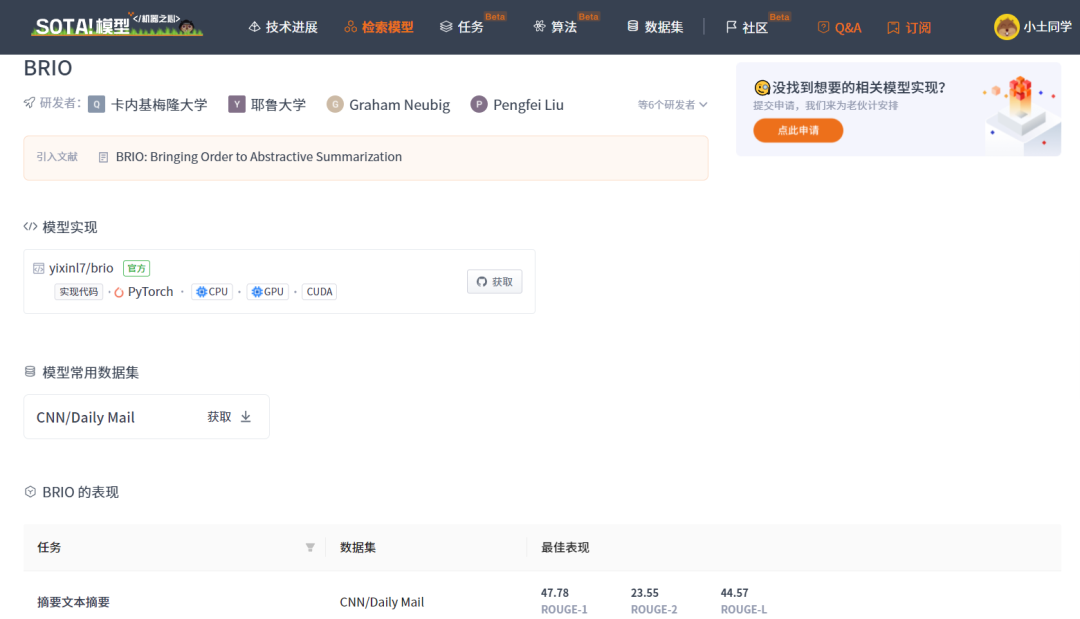
| 模型 | SOTA!平台模型详情页 |
|---|---|
BRIO |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/7de76bc7-f55c-465c-9a81-ff175a623a6d |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。


