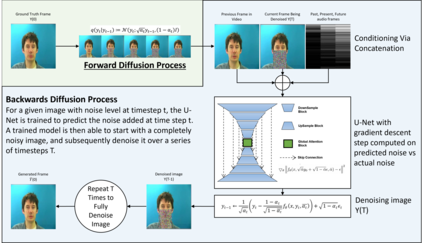
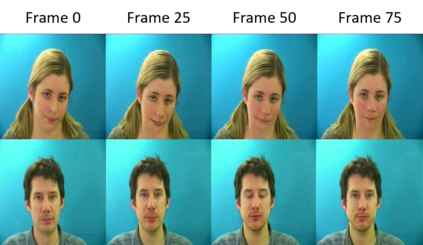
In this paper we propose a method for end-to-end speech driven video editing using a denoising diffusion model. Given a video of a person speaking, we aim to re-synchronise the lip and jaw motion of the person in response to a separate auditory speech recording without relying on intermediate structural representations such as facial landmarks or a 3D face model. We show this is possible by conditioning a denoising diffusion model with audio spectral features to generate synchronised facial motion. We achieve convincing results on the task of unstructured single-speaker video editing, achieving a word error rate of 45% using an off the shelf lip reading model. We further demonstrate how our approach can be extended to the multi-speaker domain. To our knowledge, this is the first work to explore the feasibility of applying denoising diffusion models to the task of audio-driven video editing.
翻译:在本文中,我们提出了一个使用分解的传播模式进行端到端语音驱动视频编辑的方法。根据一个人说话的视频,我们的目标是对一个人的嘴唇和下巴运动进行重新同步,以回应一个单独的听力语音记录,而不必依赖中间结构表象,如面部标志或3D面部模型。我们用音频光谱特性来调整一个分解的传播模型,以产生同步的面部运动,这样可以做到这一点。我们在非结构的单声频视频编辑任务上取得了令人信服的结果,在使用架子上唇读模型实现45%的字误差率。我们进一步展示了如何将我们的方法扩大到多声区。据我们所知,这是探索将分解扩散模型应用于音频驱动视频编辑任务的可行性的第一项工作。