DQN、A3C、DDPG、IQN…你都掌握了吗?一文总结强化学习必备经典模型(一)
机器之心专栏
本专栏由机器之心SOTA!模型资源站出品,每周日于机器之心公众号持续更新。
本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 2 期进行连载,共介绍 13 个在强化学习任务上曾取得 SOTA 的经典模型。
第 1 期:DQN、DDQN、DDPG、A3C、PPO、HER、DPPO、IQN
第 2 期:I2A、MBMF、MVE、ME-TRPO、DMVE
您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| DQN | https://sota.jiqizhixin.com/project/dqn-2 收录实现数量:92 支持框架:PyTorch、TensorFlow等 |
Playing Atari with Deep Reinforcement Learning |
| DDQN | https://sota.jiqizhixin.com/project/ddqn-tuned-hs 收录实现数量:80 支持框架:PyTorch、TensorFlow等 |
Deep Reinforcement Learning with Double Q-learning |
| DDPG | https://sota.jiqizhixin.com/project/ddpg 收录实现数量:3 支持框架:PyTorch、TensorFlow |
Continuous control with deep reinforcement learning |
| A3C | https://sota.jiqizhixin.com/project/a3c-ff-1-day-hs 收录实现数量:60 支持框架:PyTorch、TensorFlow等 |
Asynchronous Methods for Deep Reinforcement Learning |
| PPO | https://sota.jiqizhixin.com/project/ppo-3 收录实现数量:3 支持框架:PyTorch、TensorFlow |
Proximal Policy Optimization Algorithms |
| HER | https://sota.jiqizhixin.com/project/her 收录实现数量:3 支持框架:PyTorch、TensorFlow |
Hindsight Experience Replay |
| DPPO | https://sota.jiqizhixin.com/project/dppo 收录实现数量:3 支持框架:PyTorch、TensorFlow |
Emergence of Locomotion Behaviours in Rich Environments |
| IQN | https://sota.jiqizhixin.com/project/iqn 收录实现数量:20 支持框架:PyTorch、TensorFlow等 |
ImplicitQuantile Networks for Distributional Reinforcement Learning |
强化学习有四个基本组件:环境(States)、动作(Actions)、奖励(Rewards)、策略(Policy)。其中,前三项为输入,最后一项为输出。
强化学习一种普遍的分类方式是根据询问环境会否响应agent的行为进行分类,即无模型(model-free)和基于模型(model-based)两类。其中,model-free RL算法通过agent反复测试选择最佳策略,这也是研究比较多的领域,这些算法是agent直接和环境互动获得数据,不需要拟合环境模型,agent对环境的认知只能通过和环境大量的交互来实现。这样做的优点是通过无数次与环境的交互可以保证agent得到最优解。往往在游戏这样的没有采样成本的环境中都可以用model-free;model-based RL算法根据环境的学习模型来选择最佳策略,agent通过与环境进行交互获得数据,根据这些数据对环境进行建模拟合出一个模型,然后agent根据模型来生成样本并利用RL算法优化自身。一旦模型拟合出来,agent就可以根据该模型来生成样本,因此agent和环境直接的交互次数会急剧减少,缺点是拟合的模型往往存在偏差,因此model-based的算法通常不保证能收敛到最优解。但是在现实生活中是需要一定的采样成本的,采样效率至关重要,因此,向model-based方法引入model-free是一个提升采样效率的重要方式。在model-based RL中不仅仅有原来model-free中的结构,还多了一个model,原本在model-free中用来训练值函数和策略函数的经验有了第二个用处,那就是model learning,拟合出一个适当的环境模型。
本文对经典的强化学习模型是分别从model-free和model-based这两个类别进行介绍的。除了经典的强化学习问题外,还有多个不同的强化学习分支方法,包括分层强化学习、多任务强化学习、分布式强化学习、可解释的强化学习、安全强化学习、迁移学习强化学习、元学习强化学习、多智能体强化学习,以及强化学习在特定领域中的应用等等,这些方法均不在本文讨论范围内。我们将在后续其它专题中具体探讨。
一、Model-free
1.1 DQN
DQN是第一个可以从高维输入中直接学习到控制策略的深度学习模型。DQN是一个卷积神经网络,基于Q-learning进行训练,其输入是像素点,输出是一个可以预估未来奖励的值函数(value function)。Q-learning是非常有效的强化学习方法,但是它不适宜处理高维数据,奖励函数需要人为的去设定。DQN的思路是用神经网络去拟合一个奖励函数,从而构建一个比较通用的模型去处理不同的问题,以解决Q-learning的通用性的问题。
DQN使用 Q-learning 算法的变体进行训练,使用随机梯度下降更新权重。为了缓解相关数据和非平稳分布的问题,引入一种经验重放机制,它随机采样先前的transitions,从而使过去的许多行为的训练分布变得平滑。
直接处理原始的Atari帧,即210×160像素的图像、有128种颜色的调色板,在计算上要求很高,DQN采用了一个旨在降低输入维度的预处理步骤。DQN首先将原始帧的RGB表示转换为灰度,并将其下采样为110×84的图像。最终的输入表征是通过裁剪一个84×84的图像区域得到的,该区域大致上捕获了游戏区域。最后保留裁剪阶段,这是因为DQN使用了二维卷积的GPU实现,它要求方形的输入。有几种使用神经网络参数化 Q 的可能方法。由于 Q 将历史-动作对( history-action pairs)映射到其 Q 值的估计,因此历史和动作已被某些先前的方法用作神经网络的输入。这种架构的主要缺点是需要单独的前向传播来计算每个动作的 Q 值,导致成本与动作数量成线性比例。作者改为使用一种架构,其中每个可能的动作都有一个单独的输出单元,只有状态表示是神经网络的输入。输出对应于输入状态的单个动作的预测 Q 值。这种架构的主要优点是能够计算给定状态下所有可能动作的 Q 值,只需通过网络进行一次前向传递。
具体的,作者在文章中介绍了用于所有七款 Atari 游戏的具体架构。神经网络的输入是由ϕ 生成的84×84×4 图像。第一个隐藏层将16 个步长为 4 的 8×8 滤波器与输入图像进行卷积,并应用激活函数。第二个隐藏层卷积 32 个 4×4 的滤波器,步长为 2,再次跟随激活函数。最后的隐藏层是全连接层,由256 个神经元组成。输出层是一个全连接层,每个有效动作都有一个输出。在作者考虑的游戏中,有效动作的数量在 4 到18 之间。作者将使用该方法训练的卷积网络称为 Deep Q-Networks (DQN)。
DQN的执行过程如Algorithm 1:

DQN中使用的经验重放(experience replay)方法 ,在每个时间步长将agent的经验 e_t=(s_t,a_t,r_t,s_t+1) 存储在数据集 D=e_1,...,e_N 中。在算法的内部循环期间,将 Q-learning 更新或mini-batch更新应用于从存储样本池中随机抽取的经验样本e∼D。执行经验重放后,agent根据ϵ−greedy 策略选择并执行动作。由于使用任意长度的历史作为神经网络的输入可能很困难,作者的 Q 函数改为使用由函数ϕ 产生的固定长度的历史表示。
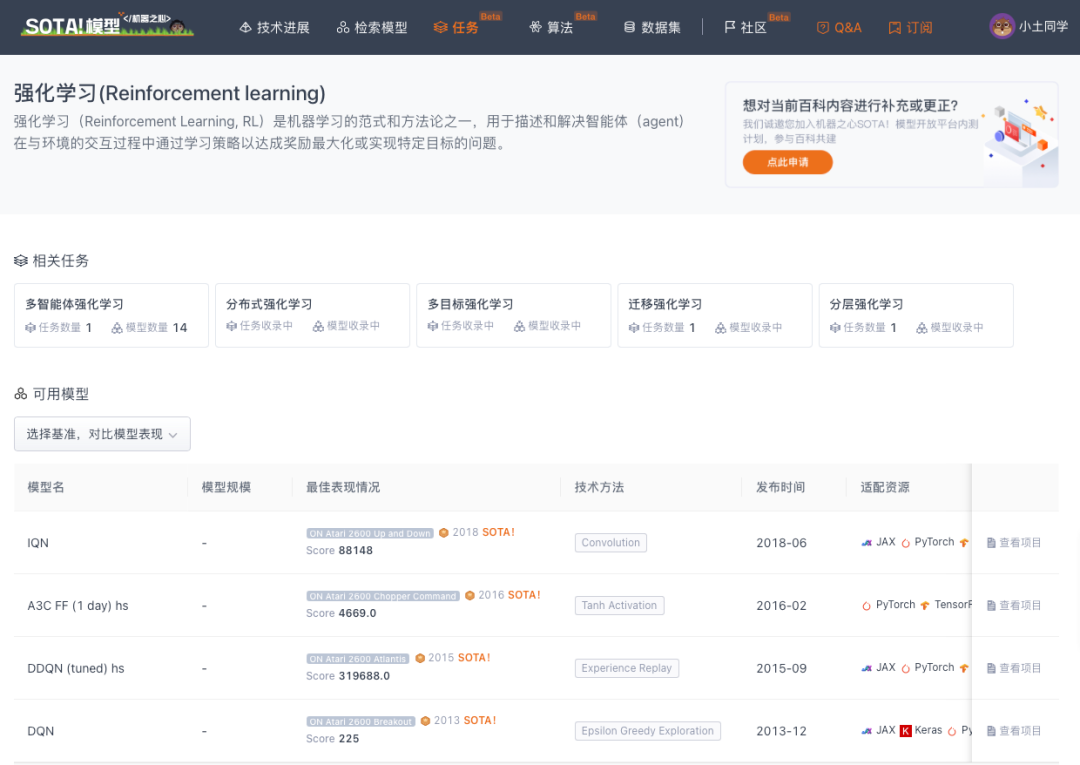
当前 SOTA!平台收录 DQN 共 92 个模型实现资源。
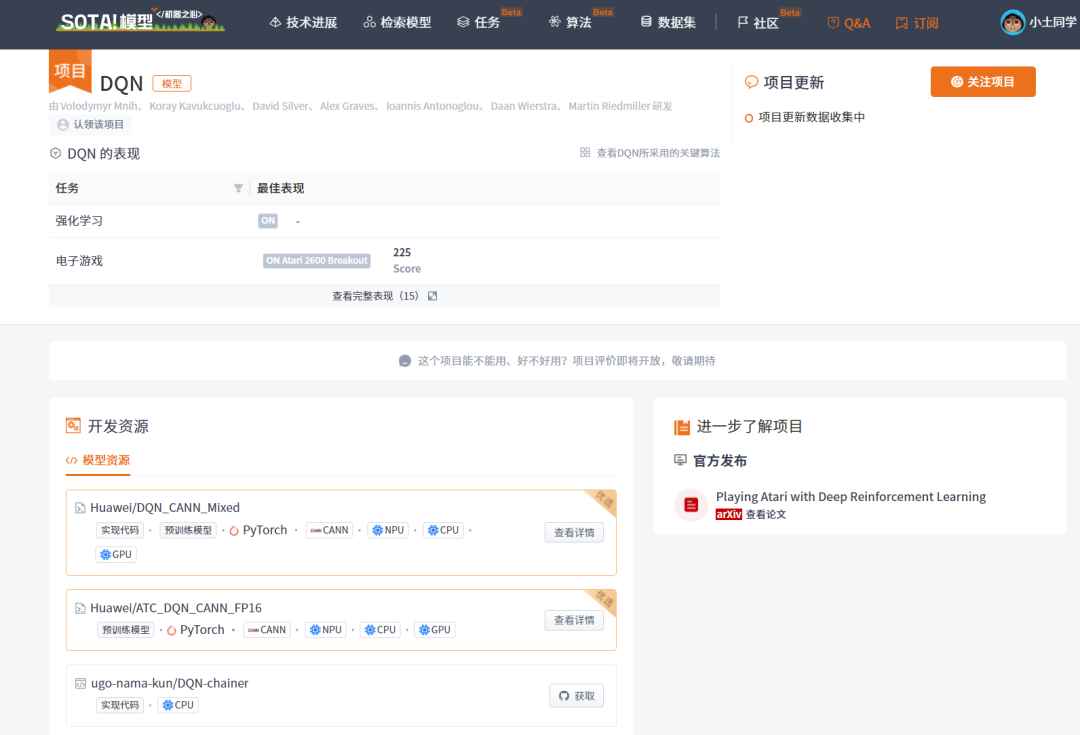
| 项目 | SOTA!平台项目详情页 |
|---|---|
| DQN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/dqn-2 |
1.2 DDQN
为了介绍DDQN,首先介绍Double Q-learning。Q-learning学习是使用单估计器(single estimate)去估计下一个状态,Double Q-learning则是使用两个函数QA 和QB (对应两个估计器),并且每个Q 函数都会使用另一个 Q 函数的值更新下一个状态。两个Q 函数都必须从不同的经验子集中学习,但是选择要执行的动作可以同时使用两个值函数。该算法的数据效率不低于Q学习。对于每次更新,一组权重用于确定贪婪策略,另一组用于确定其值。为了清楚地进行比较,可以首先解除Q-learning中的选择和评估,并将目标写为:
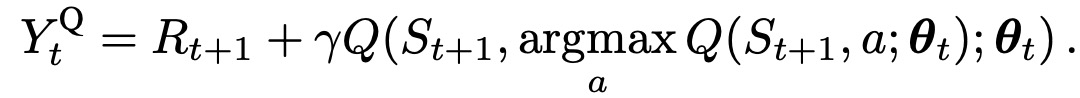
Double Q-leanring学习误差可以写为:
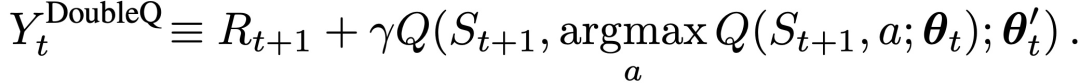
在argmax中,行动的选择仍然是受在线权重θ_t的影响。这意味着,和Q-learning一样,仍然是根据当前的值来估计贪婪策略的值。使用第二套权重θ't来公平地评估这个策略的价值。这第二套权重可以通过交换θ和θ'的角色来对称地更新。
Double Q学习通过将目标中的最大操作分解为行动选择和行动评估来减少高估的情况。虽然没有完全解耦,但DQN架构中的目标网络为第二个值函数提供了一个自然的候选者,而不必引入额外的网络。因此,可以根据在线网络来评估贪婪策略,但使用目标网络来估计其价值。参照Double Q-learning和DQN,把由此生成的算法称为Double DQN(DDQN)。它的更新方式与DQN相同,但将目标(Y_t)^DQN替换为:
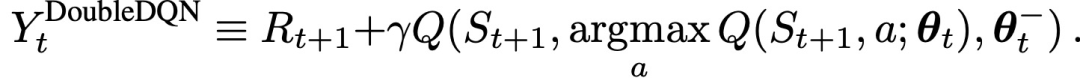
Double DQN在实现的时候直接利用DQN网络,θ_t、θ_t′每隔N次替换为θ_t ,如下图算法流程所示。这是DQN使用Double Q-learning代价最小的方式:

当前 SOTA!平台收录DDQN共 80 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
DDQN |
前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/ddqn-tuned-hs |
1.3 DDPG
DDPG是Google DeepMind团队提出的一种用于输出确定性动作的算法,它解决了Actor-Critic神经网络每次参数更新前后都存在相关性导致神经网络只能片面的看待问题这一缺点,同时也解决了DQN不能用于连续性动作的缺点,属于model-free、off-policy、policy-based的方法。简单来说:DQN+Actor-Critic =>Deep Deterministic Policy Gradient (DDPG)。
DDPG包括如下特点:
actor和critic分别由训练网络和目标网络构成,相当于总共含有4个网络,目的是增强学习过程的稳定性;
引入experience buffer的机制,用于存储agent与环境交互的数据(s_t,a_t,r_t,s_t+1)。experience buffer的容量置为某个值,当experience buffer充满数据时,则需要删掉最旧的样本数据,保证experience buffer中永远存放着最新的转换序列。每次更新时,actor和critic都会从中随机地抽取一部分样本进行优化,来减少一些不稳定性;
DDPG采用soft update缓慢地更新两个目标网络中的参数;
在神经网络中加入batch normalization,以应对不同量纲的问题;
DDPG算法采用向动作网络的输出中添加随机噪声的方式实现exploration。
DDPG具体的算法如下:

首先是定义actor和critic的两个网络结构并初始化网络中的参数(网络模型均一致),之后定义经验池(experience buffer)的存放和采样过程,最后是将完整的DDPG算法过程放到一个大的类中。对于actor网络来说,模型更新方法是基于梯度上升的。该网络的损失函数就是从critic网络中获取的Q值的平均值,在实现的过程中,需要加入负号,即最小化损失函数,来与深度学习框架保持一致。而critic网络的参数更新方式是与DQN算法一样的,就是通过最小化目标网络与现有网络之间的均方误差来更新现有网络的参数,只不过唯一不同的地方在于目标网络的参数在DDPG算法中是缓慢更新的,而不是像DQN中一样每隔N步就将现有网络的参数直接复制过来。
当前 SOTA!平台收录DDPG共3个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| DDPG | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/ddpg |
1.4 A3C
Asynchronous Advantage Actor-Critic(A3C)是强化学习中的一种有效利用计算资源, 并且能提升训练效用的算法。A3C包括三个核心点:异步训练框架、网络结构优化、Critic评估点的优化,通过多个agent和环境进行互动,每个agent都能生成数据,然后将数据一起送给模型进行学习。因此,A3C的主要贡献是一种异步并发的强化学习框架。
首先,异步训练框架是指构建一个公共的神经网络模型,包括Actor网络和Critic网络两部分的功能。公共模型下面有n个worker线程,每个线程里有和公共模型相同的网络结构,每个线程会独立的和环境进行交互得到经验数据,这些线程之间互不干扰,独立运行。每个线程和环境交互到一定量的数据后,计算在自己线程里的神经网络损失函数的梯度,但是这些梯度却并不更新自己线程里的神经网络,而是去更新公共模型。也就是n个线程会独立的使用累积的梯度分别更新公共部分的神经网络模型参数。每隔一段时间,线程会将自己的神经网络的参数更新为公共神经网络的参数,进而指导后面的环境交互。
其次,网络结构优化是指,将Actor和Critic放在一起,即输入状态后,同时得到状态价值和对应的策略。然后,关于Critic评估点的优化,使用了N步采样,以加速收敛。具体伪代码如下:

与基于价值的方法一样,A3C依靠平行的actor learner和累积更新来提高训练的稳定性。虽然策略的参数θ和值函数的参数θ_v是独立的,但在实践中,总是会共享一些参数,通常使用一个卷积神经网络,它有一个策略π(a_t|s_t; θ)的softmax输出和一个值函数V(s_t; θ_v)的线性输出,所有非输出层共享。
A3C将策略π的熵加入到目标函数中,通过阻止过早收敛到次优的确定性策略来改善 exploration。包括熵正则化项在内的全部目标函数的梯度与策略参数有关,其形式为:
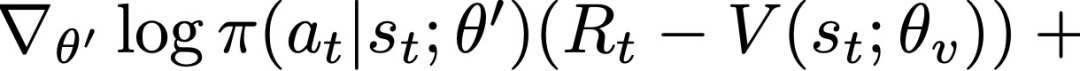
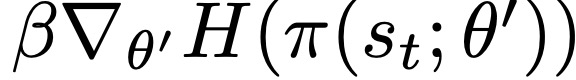
当前 SOTA!平台收录A3C共60个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| A3C | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/a3c-ff-1-day-hs |
1.5 PPO
PPO(Proximal Policy Optimization)近端策略优化算法和DDPG一样,也是Actor-Critic的架构,但是和DDPG的不同点是:PPO的actor输出的不是一个动作,而是一个策略。为了解决数据使用效率低的问题,PPO通过重要性采样方案重复使用样本。
重要性采样是指,当从一个分布中采样比较困难时,可以从另一个容易的分布中采样,两种采样分布不同,所以需要将采样到的样本进行修正。在PPO中,如果我们想使用策略B抽样出来的数据来更新策略P,可以将td_error乘一个重要性权重:IW=P(a)/B(a),就是目标策略动作概率a的概率除以行为策略出现a的概率。通过引入重要性采用方法,PPO将Actor-Critic架构中的On-policy变为Off-policy。
为了解决新旧策略差异大导致的更新不稳定问题,PPO在策略梯度更新的基础上添加了一个约束,希望每次更新策略差异不要太大。PPO算法的优化使用了如下公式:
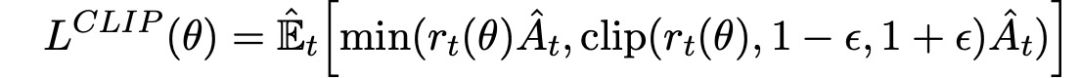
另一种方法,可以作为clipped surrogate objective的替代方法,或者作为其补充,是使用引入KL-divergence的惩罚并调整惩罚系数,使得在每次策略更新时达到KL-divergence的一些目标值d_targ。在这个算法的最简单的实例中,在每次策略更新中执行以下步骤:
使用mini-batch SGD的几个epoch,优化KL惩罚的目标。
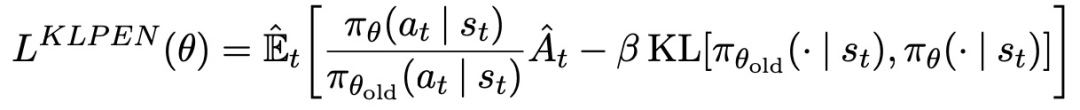
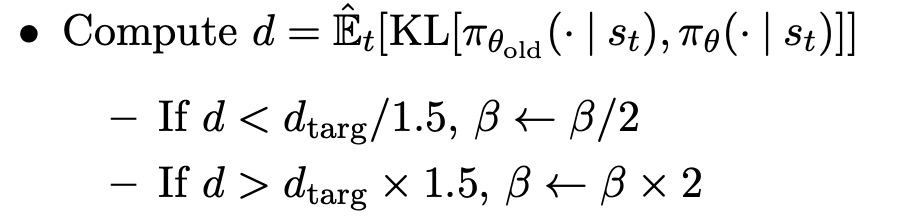
只要对典型的策略梯度实施稍作改动,就可以计算和区分上述代用损失。对于使用自动差异化的实现方式,只需构建损失L^CLIP或L^KLPEN,并对这个目标进行多步随机梯度上升。优化目标函数如下:
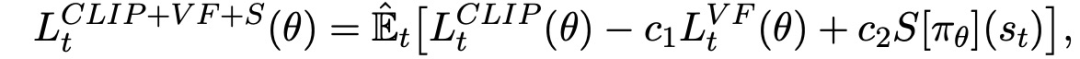
PPO引入一种适用于递归神经网络的策略梯度实施方式,在T个时间段内运行策略(T远小于episode长度),并使用收集的样本进行更新。这种方式需要一个优势估计器,该估计器不会超出时间步长T。估计器为:
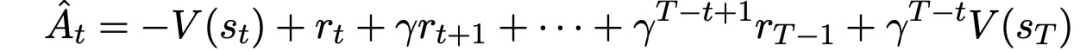
推广这一方式,可以使用广义优势估计的截断版本:
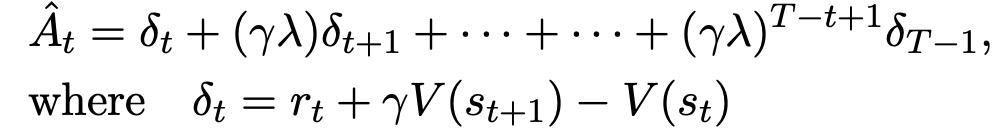
由此,得到完整的使用固定长度轨迹段的PPO算法如下Algorithm 1 所示。每次迭代中,N个(平行的)actor中的每一个都收集T个时间段的数据。然后,在这N*T个时间段的数据上构建代用损失,并在K个epoch中用mini-batch SGD对其进行优化:

| 项目 | SOTA!平台项目详情页 |
|---|---|
| PPO | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/ppo-3 |
1.6 HER
HER针对的是一种特殊场景的问题,即环境中只存在稀疏的二元奖励,该奖励用于表示任务是否完成,即只有任务完成的时候agent才会得到一个奖励。在这种场景下,策略的学习十分困难。为了辅助agent快速找到策略,一种常用的方法是 reward shaping,即根据对环境的先验信息人为设计奖励,但这种方法需要具备对特定场景的知识,并根据这些知识精心设计奖励。另外,这些reward所表示的含义有可能与原本的目标是相悖的,因此并不适用于某些不知道合理行为是何种行为的场景中。研究如何从 unshaped reward 中学习策略具有十分重要的意义,例如反映任务是否成功完成的二元奖励。Hindsight Experience Replay (HER)方法可以与任意 off-policy 算法结合,适用于有多个目标需要实现的场景。HER不仅可以提升训练的样本效率,还可以在奖励是二元且稀疏的情况下学习到好的策略。HER的基本思想是:在重放每个episode时,用一个新的目标替代原本agent需要完成的目标,这个新的目标是当前episode中实现过的目标。
具体来说,经过了一个episode: s_0,s_1,...,s_T 之后,将每个transition s_t→s_t+1 存储起来,每个experience里的目标不仅包含初始设定的目标,还包含一些重新设定的目标。当采用off-policy算法时(所学习的策略与正在执行的策略不一致),可以将trajectory里的目标更改为任意其他目标。
对于如何选取用于replay的目标,论文中提出了三种方案:
final:goal corresponding to the final state in each episode:把相应序列的最后时刻的状态作为新的目标goal。
future:replay with k random states which come from the same episode as the transition being replayed and were observed after it:从该时刻起往后的同一序列中的状态,随机采样k个作为新的目标goal。
episode:replay with k random states coming from the same episode as the transition being replayed:对于同一序列中的状态,随机采样k个作为新的目标goal。
random:replay with k random states encountered so far in the whole training procedure:从全局出现过的state中,随机选择k个作为新的目标goal。
经验池(Replay Buffer)中同时包含原本目标所对应的transition以及重新设定的目标所对应的transition,算法流程如下:

HER重点是Replay Buffer的构建,而模型本身可以选择任意off-policy的强化学习模型,如DQN、DDPG等。
当前 SOTA!平台收录HER共3个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| HER | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/her |
1.7 DPPO
原则上,强化学习范式允许直接从简单的奖励信号中学习复杂的行为。然而,在实践中,通常要专门地设计奖励函数,以鼓励一个特定的解决方案,或从示范数据中推导得出方案。本文探讨了丰富的环境如何能帮助促进复杂行为的学习。DPPO(Distributed Proximal Policy Optimization)简单来说就是多线程并行版的 PPO。不过与上面介绍的A3C情况不同,A3C 也是分布式的方法,副网络与主网络有着相同的网络结构,并用副网络计算出来的梯度更新主网络的参数,更新完后再将主网络的参数同步给副网络。DPPO的副网络不必拥有和主网络相同网络结构,每个副网络只需要有自己独立的环境就好了。副网络在不同的环境中收集数据,然后交给主网络来更新参数。
稳健的策略梯度与PPO。策略梯度算法为连续控制提供了一个有效范式。它们的运作方式是直接将预期的奖励之和最大化:
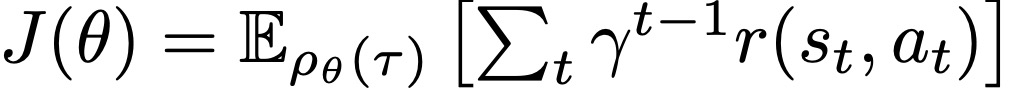
预期是关于由策略π_θ和系统动态共同引起的轨迹分布τ的:
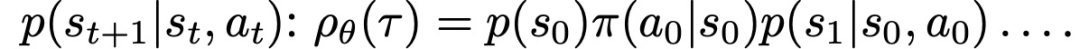
相对于θ的梯度目标由以下公式给出:
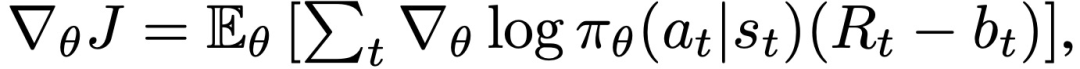
DPPO。数据收集和梯度计算都分布在worker身上。作者对同步和异步更新都进行了实验,发现平均梯度和同步应用梯度在实践中会带来更好的结果。为了方便使用批量更新的RNN,同时也支持可变长度的episodes,遵循一个策略,使用截断的反向传播,通过时间的长度为K的窗口。因此,可以使用K-step returns来估计优势,即在相同的K-step窗口上将return相加,并在K-step之后从值函数中引导。参数存放在参数服务器,worker在每个梯度步骤后同步其参数。
DPPO算法的伪代码在Algorithm 2和Algorithm 3中提供。W为worker数量,D为worker的数量设定了一个阈值,其梯度必须可用于更新参数。M、B是给定一批数据点的策略和基线更新的子迭代的数量。T是在计算参数更新之前每个worker收集的数据点的数量。K是计算K-step返回和截断反推的时间步数(对于RNNs)。


在分布式环境中,我们发现在不同的workers之间分享相关的统计数据进行数据规范化是很重要的。归一化是在数据收集过程中应用的,统计数字在每个环境步骤之后都会在本地更新。当一个迭代完成后,对统计数据的局部改变被应用于全局统计数据(伪代码中未显示)。时变的正则化参数λ也是跨workers共享的,但是更新是根据每个worker在本地计算的平均KL来确定的,并由每个worker分别应用调整后的α˜=1+(α-1)/K。此外,DPPO还采用了一个额外的惩罚项,当KL超过期望的变化一定幅度时(上面伪代码中阈值是2KL_target),该惩罚项就会生效。
当前 SOTA!平台收录DPPO共 3 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| DPPO | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/dppo |
1.8 IQN
IQN是对DQN的扩展,是model-free、off-policy、value-based、discrete的方法,具体是使用量化回归来逼近state-action奖励分布的全部量化函数。通过对样本空间的分布进行重新参数化,生成一个隐式定义的奖励分布,并产生了一大类风险敏感策略。从学习离散的量值集到学习完整的量值函数,这是一个从概率到奖励的连续映射。当与基础分布相结合时,如U([0, 1]),就形成了一个隐性分布,能够在给定足够的网络容量的情况下,近似于returns的任何分布。首先,分布的近似误差不再由网络输出的量值数量控制,而是由网络本身的规模和训练量控制。第二,IQN可以根据需要在每次更新时使用很少或很多的样本,随着每次训练更新的样本数量增加,提供更好的数据效率。第三,奖励分布的隐式表示使我们能够扩大策略的类别,以更充分地利用所学到的分布。具体来说,通过将基础分布视为非均匀分布,将策略类别扩展为任意失真风险措施的贪婪策略。
IQN是一个神经网络,输入为状态 x 和一个采样 τ∼U[0,1] ,输出不同离散动作对应的值函数分布的 τ 分位数Zτ(x,a):=FZ−1(τ|x,a) 。定义与风险倾向有关的值函数如下:
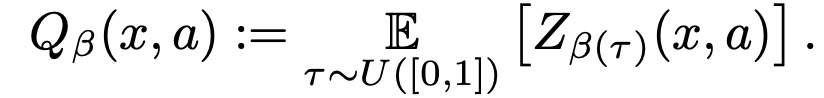
其中,β(⋅):[0,1]→[0,1] 函数是单位映射,这个Q函数和之前定义的一样,是值函数分布的期望。如果该函数为凸函数(或者在图像上都在单位映射下方),那么就等于往较差情况加了较大的权重,这就产生了risk-averse型的风险偏好;如果该函数为凹函数(或者在图像上都在单位映射上方),那么就等于往较好情况加了较大的权重,这就产生了risk-seeking型的风险偏好。
定义在此值函数下的贪心策略:
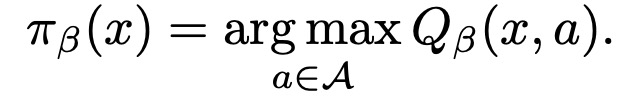
实际计算中通过采样来得到该策略:
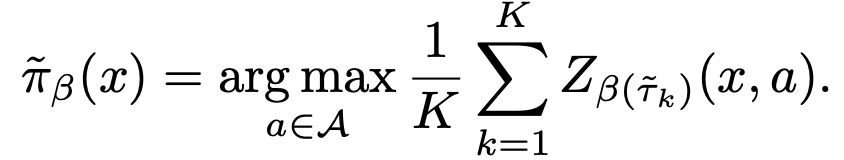
使用梯度下降优化如下损失函数:
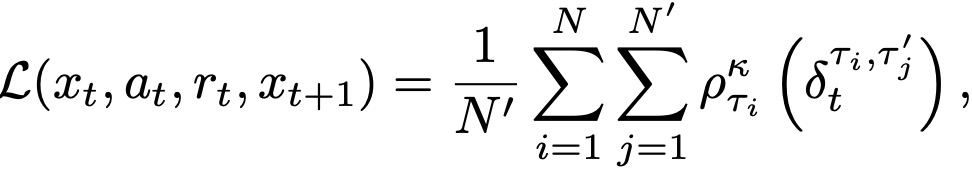
其中,ρ(⋅) 为quantile regression的损失函数。
IQN使用与DQN中相同的函数ψ和f,但引入了一个额外的函数φ。把这些结合起来形成近似值Z_τ (x, a) ≈ f(ψ(x)⊙ φ(τ ))a,其中⊙表示element-wise(Hadamard)乘积。由于f的网络不是特别深,使用乘法形式ψ ⊙φ来强制卷积特征和样本嵌入之间的互动。最终的IQN算法如下:

当前 SOTA!平台收录IQN共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| IQN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/iqn |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。

