视频生成经典模型资源(一):TGAN、VGAN、MoCoGAN、SVG、vid2vid、VideoVAE、DVD-GAN
机器之心专栏
本专栏由机器之心SOTA!模型资源站出品,每周日于机器之心公众号持续更新。
本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 2 期进行连载,共介绍 15 个在视频生成任务上曾取得 SOTA 的经典模型。
第 1 期:TGAN、VGAN、MoCoGAN、SVG、vid2vid、VideoVAE、DVD-GAN、SWGAN
第 2 期:TGANv2、TGANv2-ODE、VideoGPT、DVG、NÜWA、StyleGAN-V、Video Diffusion Models
您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| TGAN | https://sota.jiqizhixin.com/project/tgan 收录实现数量:1 |
Temporal Generative Adversarial Nets with Singular Value Clipping |
| VGAN | https://sota.jiqizhixin.com/project/vgan | Generating Videos with Scene Dynamics |
| MoCoGAN | https://sota.jiqizhixin.com/project/mocogan 收录实现数量:4 支持框架:PyTorch、TensorFlow |
MoCoGAN: Decomposing Motion and Content for Video Generation |
| SVG | https://sota.jiqizhixin.com/project/svg 收录实现数量:2 支持框架:PyTorch、TensorFlow |
Stochastic Video Generation with a Learned Prior |
| vid2vid | https://sota.jiqizhixin.com/project/vid2vid 收录实现数量:1 支持框架:PyTorch、TensorFlow |
Video-to-Video Synthesis |
| VideoVAE | https://sota.jiqizhixin.com/project/videovae 收录实现数量:1 支持框架:PyTorch、TensorFlow |
Probabilistic Video Generation using Holistic Attribute Control |
| DVD-GAN | https://sota.jiqizhixin.com/project/dvd-gan-fp 收录实现数量:1 支持框架:PyTorch |
ADVERSARIAL VIDEO GENERATION ON COMPLEX DATASETS |
| SWGAN | https://sota.jiqizhixin.com/project/pg-swgan-3d 收录实现数量:1 支持框架:TensorFlow |
Sliced Wasserstein Generative Models |
TGAN
TGAN( Temporal Generative Adversarial Net )是一种可以学习无标签视频数据集中的语义表示并产生新的视频的生成对抗网络。TGAN由两个生成器构成:temporal generator G0和image generator G1。G0用z0(从分布P_G0(z0)中随机抽样得到)作为输入,生成一系列潜在变量z1。G1使用z0和z1作为输入,输出为视频。为了解决原始GAN训练不稳定的问题,引入了WGAN,又因为TGAN对WGAN中的参数比较敏感,作者将WGAN中的权值分割方法用SVC方法代替,从而使得模型更加稳定,并且在损失函数不同于传统时仍然能够成功的训练。TGAN的结构如图1所示:
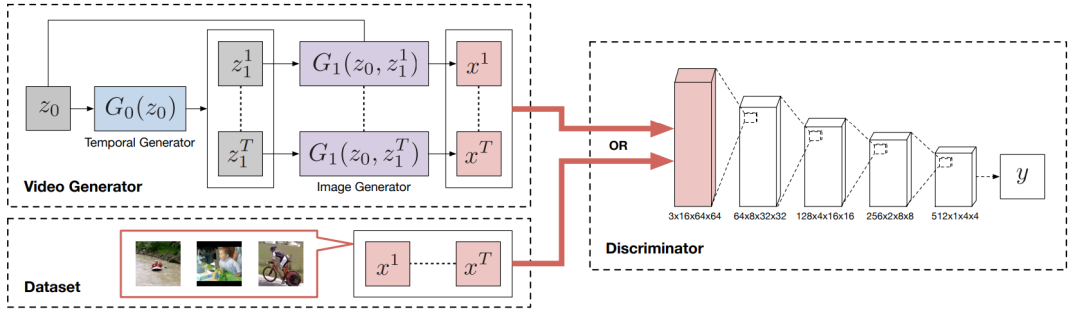
图1. TGAN结构。鉴别器由三维卷积层组成,并评估这些帧是来自数据集还是来自视频生成器。鉴别器中的张量的形状记为“(通道)×(时间)×(高度)×(宽度)”
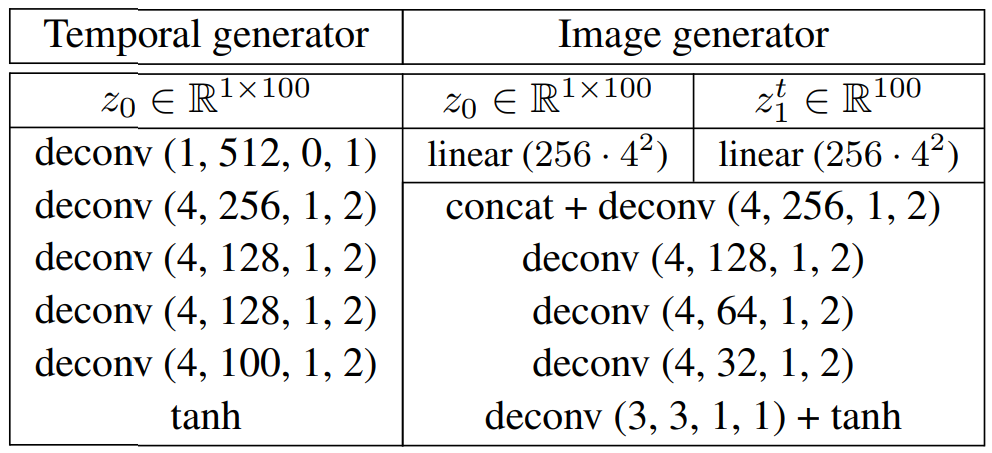
表1. generator的网络配置。第二行表示输入变量。“线性(·)”是线性层中的输出单元的数量。卷积层和反卷积层中的参数表示为“conv/denonv((内核大小)、(输出通道)、(填充)、(步幅))
TGAN的极大极小策略可以表示为:
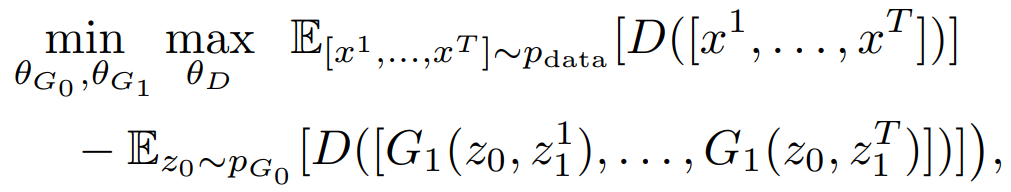
其中x_t是数据集中视频的第t帧,(z_1)^t是G_0(z_0)生成的第t帧对应的潜在变量。θ_D、θ_G0、θ_G1分别表示D、G0、G1的参数。
temporal generator
首先将z0∈R^K0视为z0∈R1×K0的一维激活图,其中,通道的长度和数量分别为1和k0。采用均匀分布的方法对z0进行采样。接下来,应用反卷积层扩展其长度,同时减少通道的数量。除通道数和一维反卷积外,反卷积层的设置与图像生成器的设置相同。与原始的图像生成器一样,在反卷积后插入一个批处理归一化(BN)层,并使用ReLU作为激活函数。
Image generator
图像生成器采用两个潜在变量作为参数。在对每个变量进行线性变换后,对它们进行如表1所示的reshape,将它们连接起来并执行5次反卷积。除最后一个反卷积层外,核大小、步幅和填充分别设为4、2和2。最后一个反卷积层的输出通道的数量取决于数据集是否包含颜色信息。
Discriminator
采用时空三维卷积层来建模鉴别器。图层的设置类似于图像生成器。具体来说,使用四个卷积层,4×4×4内核,步幅为2。初始卷积层的输出通道数为64个,当该层深度加深时将该数目设置为两倍大小。引入一个a=0.2的LeakyReLU和批处理归一化层。最后,使用一个全连接层,将所有的units总结在一个标量中。鉴别器中使用的张量形状如图1所示。
SVC
为了满足1-Lipschitz约束,给鉴别器中的所有线性层添加一个约束,以满足权重参数W的spectral norm 等于或小于1。这意味着权重矩阵的奇异值都是1或小于1。在参数更新后进行奇异值分解(SVD),将所有大于1的奇异值替换为1,然后用它们重建参数。将同样的操作也应用于卷积层,将权重参数中的高阶张量解释为一个矩阵Wˆ,称这些操作为奇异值剪切(Singular Value Clipping,SVC)。
与线性和卷积层一样,以同样的方式表征批处理归一化层的缩放参数的γ值。表2给出各层的剪裁方法。注意,不对ReLU和LeakyReLU层进行任何操作,因为它们总是满足条件,除非LeakyReLU中的a小于1。

表2. 满足1-Lipschitz约束的方法。|| · ||表示 a spectral norm 。a表示LeakyReLU层的固定参数。γ和σ_B分别是批量归一化后的比例参数和一个批量的标准差的运行平均值
当前 SOTA!平台收录TGAN共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| TGAN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/tgan |
VGAN
VGAN的核心思想是将视频区分为前景(foreground)和后景(background),即,将运动前景的生成和静态背景的生成解耦:首先输入为100维的噪声向量,然后使用3D转置卷积网络生成运动前景,使用2D转置卷积网络生成运动背景,并使用mask构建显性表达式约束网络的优化,整个网络结构如下图所示:
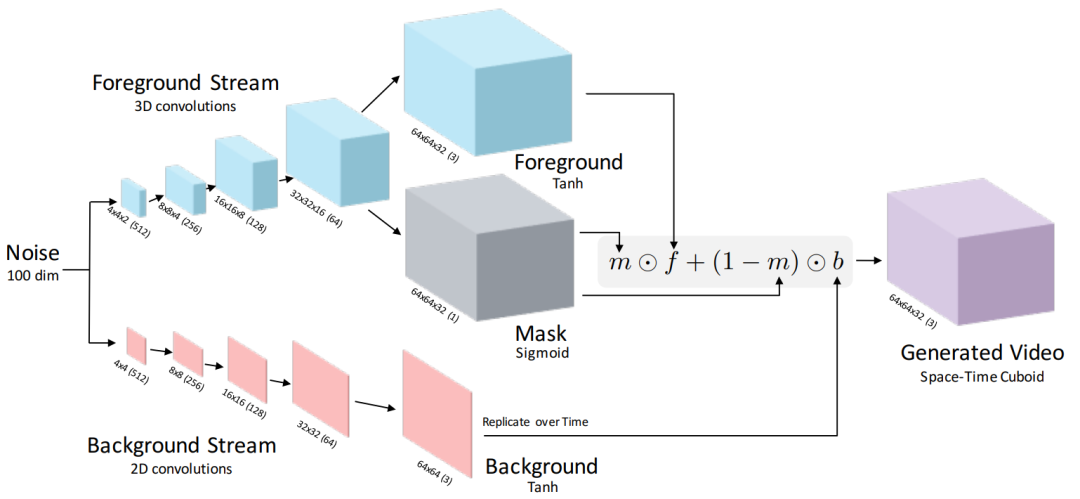
图2. Video Generator Network,对generator的网络结构进行了说明。输入是100维的(高斯噪声)。有两个独立的数据流:一个是分层时空卷积的运动前景路径,一个是分层空间卷积的静态背景路径,两者都是上采样的。结合两条路径,使用运动路径的mask创建生成的视频。每个volume下面是它的大小,括号里是通道的数量
Generator Network
生成器网络的输入是一个低维的潜在变量z 。在大多数情况下,z可以从一个分布中取样(例如高斯)。给定z,目标是产生一个视频。在设计generator网络结构时,遵循几个原则。首先,希望该网络在空间和时间上对平移都是不变的。第二,希望一个低维的z能够生成一个高维的输出(视频)。第三,假设一个静止的摄像机,并利用通常只有物体移动的特性。我们感兴趣的是对物体运动进行建模,而不是对摄像机的运动进行建模。此外,由于对背景静止的建模在视频识别任务中很重要,它可能对视频生成也有帮助。
作者探索了两种不同的网络结构。
One Stream Architecture: 将时空卷积与分层卷积结合起来,生成视频。三维卷积提供了空间和时间上的不变性,而分层卷积可以在深度网络中有效地进行上采样,确保z低维。使用4×4×4卷积的五层网络,步长为2,只有第一层使用2×4×4卷积(时间×宽度×高度)。
Two Stream Architecture: One Stream Architecture并没有建立世界是静止的模型,通常只有物体在移动。作者进一步引入一个强制执行静态背景和移动前景的架构。
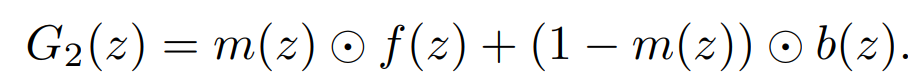
为了在generations中强制执行背景模型,b(z)生成一个随时间复制的空间图像,而f(z)生成一个被m(z)掩盖的空间-时间立方体。通过将前景模型与背景模型相加,可以得到最终的生成,即元素相乘,我们复制单子维度以匹配其相应的张量。
Discriminator Network
鉴别器需要能够解决两个问题:
首先,它必须能够从合成的场景中分类出真实的场景;
其次,它必须能够识别帧之间的真实运动。设计鉴别器,使其能够用同一模型解决这两个任务。使用一个五层的时空卷积网络,其内核为4×4×4,这样隐藏层就可以同时学习视觉模型和运动模型。该架构与生成器中的前景流相反,用分层卷积取代分层卷积(下采样而不是上采样),并将最后一层替换为输出二元分类(表征真实与否)。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| VGAN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/vgan |
MoCoGAN
视频中的视觉信号可分为内容和运动两类,其中,内容说明了视频中的哪些物体,而运动则描述了它们的动态。基于这一前提提出了运动和内容分解生成对抗网络( Motion and Content decomposed Generative Adversarial Network ,MoCoGAN)框架,用于视频生成任务 。该框架通过将一连串的随机向量映射到一连串的视频帧来生成视频,每个随机矢量都由内容部分和运动部分组成。虽然内容部分是固定的,但运动部分是作为一个随机过程实现的。为了以无监督的方式学习运动和内容的分解,引入了一种新的对抗性学习方案。

图3. MoCoGAN采用了运动和内容分解的表示方法来生成视频。它使用一个图像潜在空间(每个潜在变量代表一个图像)并将潜在空间划分为内容和运动子空间。通过对内容子空间中的一个点进行采样并对运动子空间中的不同轨迹进行采样,可以生成同一物体的不同运动的视频。通过对内容子空间中的不同点和运动子空间中的相同运动轨迹进行采样,可以生成不同物体做相同运动的视频
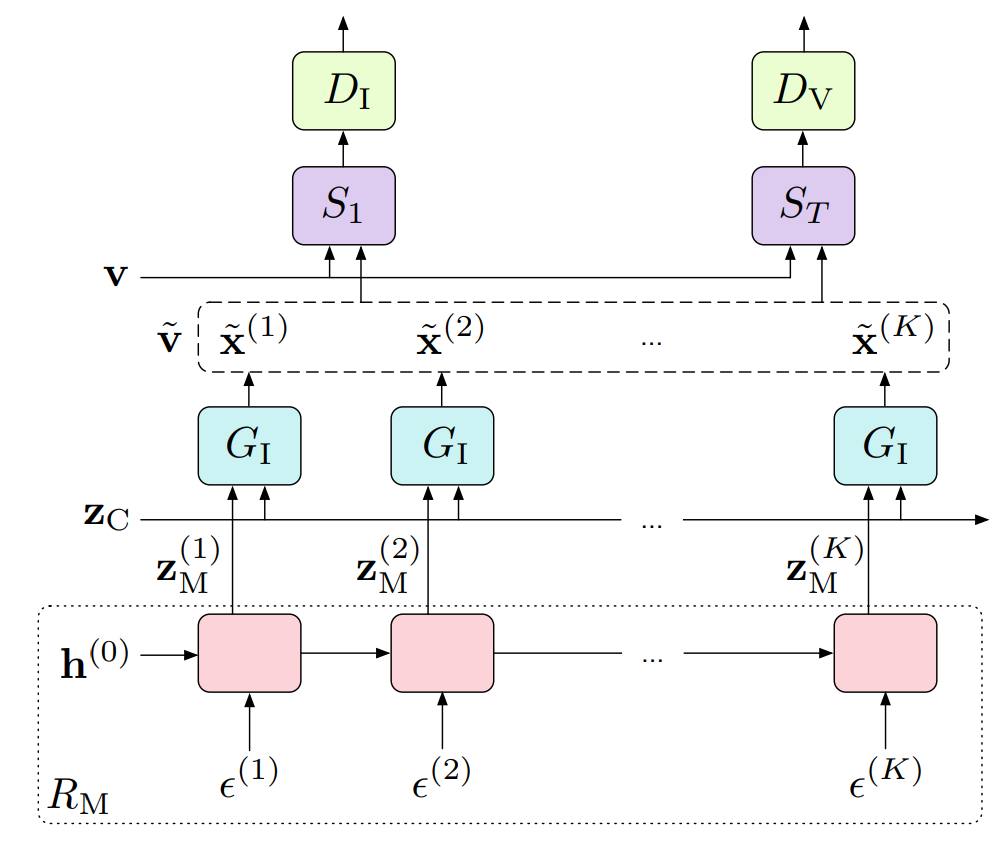
图4. 用于视频生成的MoCoGAN框架。对于一个视频,内容向量zC被采样一次并固定下来。然后,采样一系列随机变量并通过递归神经网络映射到一系列运动代码[z(1)M, ..., z(K)M]。生成器GI使用内容和运动向量{zC, z(k)M}产生一个帧,x˜(k)。鉴别器,DI和DV,分别从训练集v和生成集v˜中取样,对真实和虚假的图像和视频进行训练。函数S1从视频中取样一个单帧,ST取样T个相关的帧
在MoCoGAN中,假设有一个图像的潜空间ZI≡Rd,其中,每个点z∈ZI代表一个图像,一个K帧的视频由潜在空间中长度为K的路径表示。通过采用这种表述,不同长度的视频可以由不同长度的路径生成。此外,以不同速度执行的同一动作的视频可以通过在潜在空间中以不同速度穿越同一路径来生成。进一步,假设ZI被分解为内容ZC和运动ZM子空间。ZI = ZC × ZM,其中,ZC = RdC ,ZM = RdM,d = dC + dM。内容子空间为视频中与运动无关的外观建模,而运动子空间为视频中与运动有关的外观建模。例如,在一个人微笑的视频中,内容代表这个人的身份,而运动代表这个人的面部肌肉的变化。一个人的身份和面部肌肉构造的配对代表了这个人的面部图像。这些配对的序列代表了这个人微笑的视频片段。通过将这个人的表情与另一个人的表情互换,就可以代表一个不同人的微笑视频。使用高斯分布对内容子空间进行建模:zC ∼ pZC ≡ N (z|0, IdC) ,其中,IdC是一个大小为dC × dC的身份矩阵。基于在一个短的视频片段中内容基本保持不变的观察,使用相同的实现,zC,来生成一个视频片段中的不同帧。视频片段中的运动是由运动子空间ZM中的路径来模拟的。用于生成视频的矢量序列由以下方式表示:
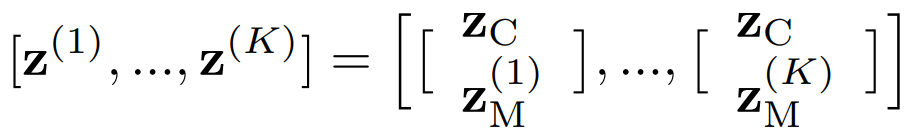
由于zM中并非所有的路径都对应于物理上合理的运动,我们需要学习生成有效的路径。用一个循环神经网络对路径生成过程进行建模。令RM表征递归神经网络。在每个时间步长,它将一个从高斯分布中采样的向量作为输入:(k)∼pE≡N(|0,IdE),并输出一个ZM中的向量,作为运动表示。RM(k)表征递归神经网络在时间k的输出,那么,z(k)M=RM(k)。递归神经网络的功能是将一串独立同分布(i.i.d.)的随机变量映射为一串相关的随机变量[RM(1), ..., RM(K)],以表征视频中的动态变化。在每个迭代中注入噪声,模拟每个时间步长的未来运动的不确定性。使用一个单层的GRU网络来实现RM。
MoCoGAN由4个子网络组成,分别是递归神经网络RM、图像生成器GI、图像鉴别器DI和视频鉴别器DV。图像生成器通过将ZI中的向量按顺序映射到图像,从向量序列到图像序列,生成视频剪辑。DI和DV都扮演judge角色,为GI和RM提供批评意见。图像鉴别器DI专门用于批评基于单个图像的GI,它被训练来确定一个帧是来自真实的视频片段v,还是来自v~。另一方面,DV根据生成的视频片段为GI提供批评意见。DV需要一个固定长度的视频片段,比如说T帧,并决定一个视频片段是来自真实视频还是来自v˜采样。与DI不同,它是基于虚构的CNN架构的,DV基于一个空间-时间CNN架构。
视频鉴别器DV也对生成的运动进行评估。由于GI没有运动的概念,对运动部分的批评直接指向了递归神经网络RM。为了生成一个具有现实动态的视频以骗过DV,RM必须学会从一连串的i.i.d.噪声输入中生成一连串的运动编码。理想情况下,单靠DV应该足以训练GI和RM,因为DV提供了对静态图像外观和视频动态的反馈。然而我们发现,使用DI可以显著提高对抗性训练的收敛性。这是因为训练DI比较简单,它只需要关注静态的外观。
当前 SOTA!平台收录 MoCoGAN 共 4 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| MoCoGAN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/mocogan |
SVG
SVG(Stochastic Video Generation)是一种随机视频生成方法,可以根据现有的视频预测生成出接下来一段时间的视频。视频生成的思路比较直接:将已有的视频帧编码至一个latent space中去,再用LSTM在潜在空间中学习到视频帧时域上的联系。最后,将LSTM输出的latent vector解码至图像空间。本文的一个创新点就在于,采用VAE的思路,在潜在空间中引入另一个随机变量z,用它和编码特征一起来对未来进行预测。
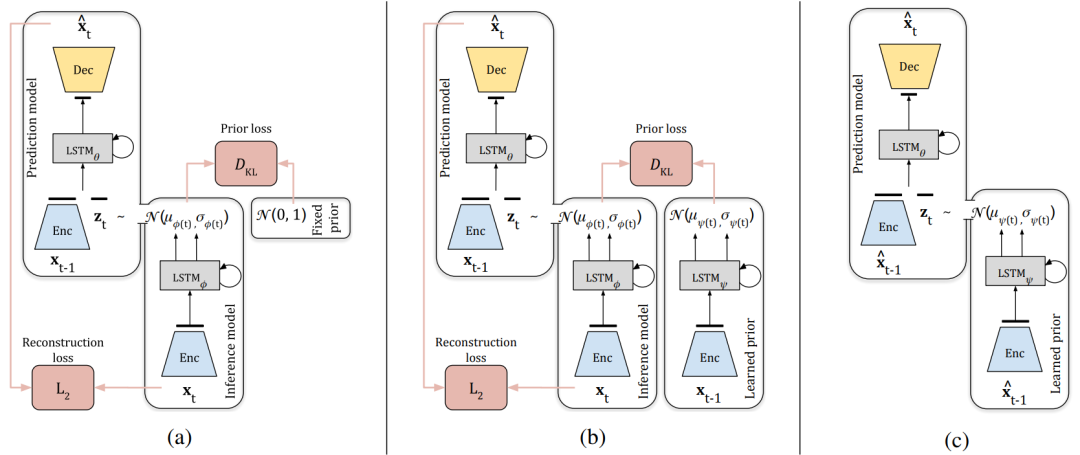
图5. SVG视频生成模型。(a)用固定先验的训练(SVG-FP);(b)用学习先验的训练(SVG-LP);(c)用学习先验LP模型生成。红框表示训练过程中使用的损失函数
模型有两个不同的组成部分。(i) 预测模型pθ,根据序列x_(1:t-1)中以前的帧和潜在变量z_t生成下一个帧;(ii) 先验分布p(z),z_t在每个时间步长中被抽样。先验分布可以是固定的(SVG-FP)或学习的(SVG-LP)。直观地讲,潜在变量z_t携带着确定性预测模型无法捕捉的关于下一帧的所有随机信息。在对一系列简短的真实帧进行调节后,该模型可以通过将生成的帧传回预测模型的输入来生成未来的多个帧。
encoder学习的latent vector的概率分布不再是基于当前样本的p(z|x) , 而是相对于一个序列p(z_t|x_(1:t)) 。这部分通过 LSTM实现。用于decoder的不再仅仅是重采样得到的latent vector,同时还有前一帧通过encoder得到的特征。decoder学习的也不再是基于当前latent vector的数据分布,而是基于一个latent vector序列的分布p(xt|x_(1:t−1),z_(1:t))。因此, 要优化这样一个修改版的VAE,其变分下界具有如下形式:
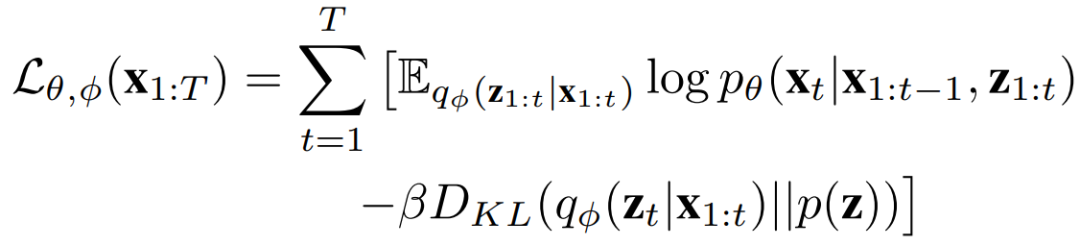
这里的先验pz 如果直接采用固定的高斯分布,无法刻画视频中帧与帧之间的联系。因此作者又提出另一个版本:再通过一个LSTM来学习这里的先验,也即SVG-LP(learned prior)。这样inference的时候,潜在变量z 不再是从N(0,I) 中采样,而是从
N(μψ(t),σψ(t)) 中采样。其中,ψ 是用于先验学习的LSTM网络的参数。同时,作者也可视化了学习到的先验σ_ψ 在时间序列中不同时刻的值的大小,它反映了decoder的输入是更依赖与前一帧的特征,还是从学习到的分布中采样出的结果。
当前 SOTA!平台收录 SVG 共 2 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| SVG | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/svg |
vid2vid
vid2vid是NVIDIA公司提出的一种图像翻译模型 ,通过输入语义图来生成视频,是在pix2pix、pix2pixHD基础上改进得到的模型。pix2pix、pix2pixHD是图像生成模型,而vid2vid是在pix2pixHD基础上考虑加入视频连贯性的设计所提出的视频翻译模型,通过改造G和D来生成连贯且高质量的视频。
(s_1)^T≡{s1, s2, ..., sT }表征源视频帧的序列。例如,它可以是一个语义分割掩码或边缘图的序列。(x_1)^T≡{x1, x2, ..., xT }是相应的真实视频帧的序列。视频生成的目标是学习一个映射函数,该函数可以将(s_1)^T转换为输出视频帧的序列,(x_1)˜^T≡{x˜1, x˜2, ..., x˜T },从而使给定(s_1)^T的(x_1)˜^T的条件分布与给定(s_1)^T的(x_1)^T的条件分布相同。
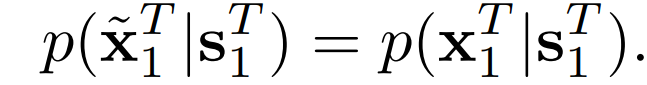
vid2vid是一个条件性GAN框架。将输入源序列映射到相应的输出帧序列:(x_1)^T= G((s_1)^T)。通过解决最小优化问题来训练生成器,该问题由下式给出
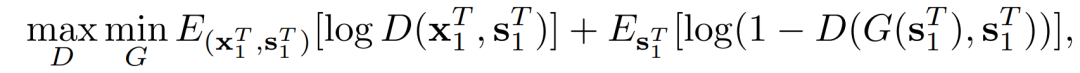
其中D是鉴别器。在求解上式时,最小化p((x_1)˜^T|(s_1)^T)和p((x_1)^T|(s_1)^T)之间的Jensen-Shannon分歧是一项具有挑战性的任务。vid2vid提出了新的网络设计和用于视频到视频合成的时空目标。
Sequential generator
首先,对优化问题做马尔可夫假设,即当前帧生成的视频仅与前L 帧的信息相关,而不是与整个1∼t 帧的视频序列的信息都相关,因此上式的约束条件为:
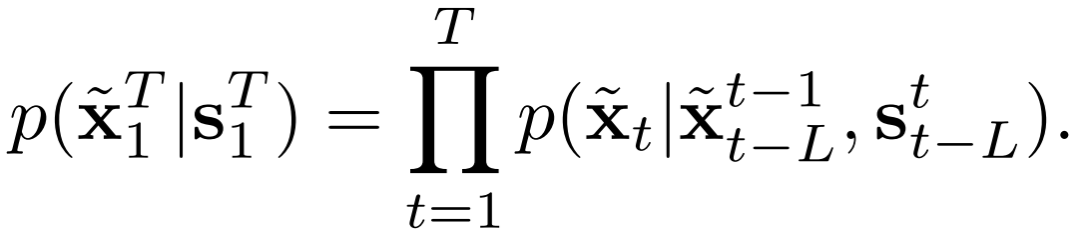
在生成第t 帧视频时,只需要将下边三类信息送入网络即可:
1) 当前第t 帧的条件输入s_t;
2) 前L帧的条件输入(s_(t−L))^(t−1);
3) 模型生成的前L帧图像(x~t−L)^(t−1)。
对于输入2)和3),马尔可夫假设保证只需要提供前L帧的信息,而不是前边所有帧的信息,从而使网络更容易优化。文章通过实验发现L一般取2效果较好,L太小会损失时序信息,L太大会造成巨大的GPU开销且提升的效果也有限。
视频信号在连续帧中包含大量的冗余信息。如果连续帧之间的光流(optical flow)是已知的,可以通过对当前帧的warping来估计下一帧。除了被遮挡的区域外,这种估计基本正确。基于这一观察,将F建模为
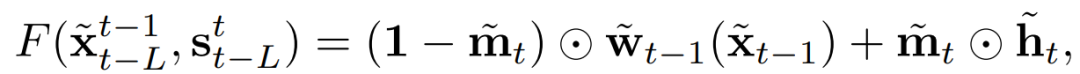
第一部分对应的是前一帧warped像素,而第二部分则是新的像素的 hallucinates 。
Conditional image discriminator DI
DI的目的是确保在相同的源图像下,每个输出帧都类似于真实图像。这个条件判别器应该对真实的一对(x_t, s_t)输出1,对假的一对(x˜t, s_t)输出0。
Conditional video discriminator DV
DV的目的是确保给定相同的光流的情况下,连续的输出帧与真实视频的时间动态相似。DI以源图像为条件,而DV以光流为条件。令(w_t-k)^(t-2)表征K个连续真实图像(x_t-k)^(t-1)的K-1个光流。DV对一对真实的图像((x_t-k)^(t-1), (w_t-k)^(t-2))输出1,对一对假的图像((x~_t-k)^(t-1), (w_t-k)^(t-2))输出0。
Learning objective function
通过解决以下问题来训练顺序视频合成函数F
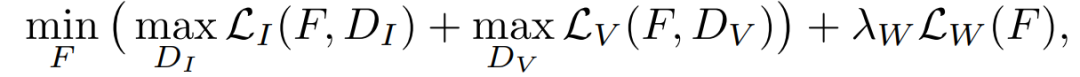
其中LI是由条件图像判别器DI定义的图像上的GAN损失,LV是由DV定义的连续K帧上的GAN损失,LW是流量估计损失。在整个实验中,基于网格搜索,将权重λW设置为10。使用鉴别器特征匹配损失和VGG特征匹配损失,这种处理方式能够提高收敛速度和训练稳定性。
Foreground-background prior
对于语义图转街景图任务,前景和背景是有很大区别的,道路这样的背景通常是不动的,因此光流计算较准,得到图像较清晰,而前景的光流计算较为困难,因此针对前后景分别建模,有利于加快收敛速度,进行有针对性的训练。
有了前景-背景先验,可以通过以下方式得到F:
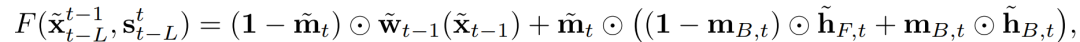
Multimodal synthesis
合成网络F是一个单模态的映射函数。给定一个输入源视频,它只能生成一个输出视频。为了实现多模态合成,对源视频采用了一个特征嵌入方案,该方案由实例级语义分割掩码组成。具体来说,在训练时,训练一个图像编码器E,将ground-truth图像编码为一个d维的特征图。然后,对该图进行实例平均汇集,使同一物体的所有像素共享相同的特征向量。然后,将实例平均的特征图z_t和输入的语义分割掩码st送入生成器F。一旦训练完成,就对属于同一对象类别的特征向量进行高斯混合分布。在测试时,使用该对象类别的估计分布为每个对象实例抽取一个特征向量。鉴于不同的特征向量,生成器F可以合成具有不同视觉外观的视频。
vid2vid网络结构
vid2vid使用了两阶段的Generator,第一阶段G1用来生成全局粗糙的低分辨率视频,第二阶段G2用来生成局部精细化的高分辨率视频。其中,G1的输入是下采样2倍之后,前L帧+当前帧的Semantic map序列以及之前L帧生成图像的序列,在经过下采样和提特征之后,在网络的中间将两路输入提取的feature map相加,接着在网络后部又分出两个分支,来生成未加光流约束的原始图像以及光流和权重mask。G2的输入是原始分辨率的Semantic map序列以及生成图像,在经过2倍下采样+提特征的卷积层之后,将两个分支提取的feature map分别与G1对应的两路输出相加,然后分别送入G2后半部分的两个分支,进行局部细节的refine。
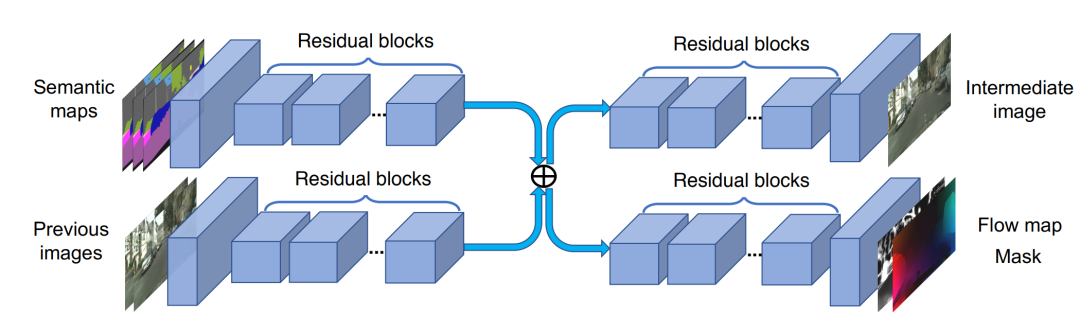
图6. 用于低分辨率视频的网络架构(G1)。网络接收一些语义标签图和先前生成的图像,并输出中间帧以及流程图和mask
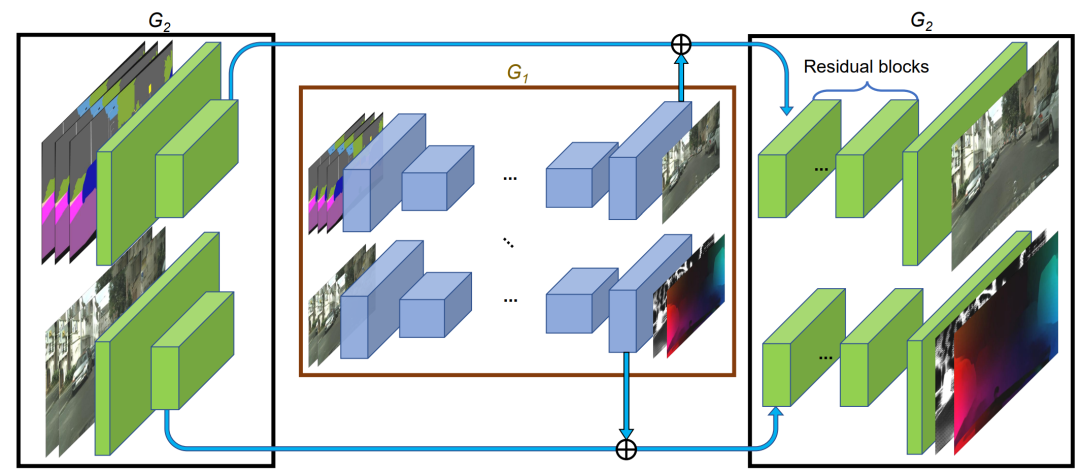
图7. 用于高分辨率视频的网络结构(G2)。对标签图和以前的帧下采样处理后送入低分辨率网络G1。然后,将来自高像素网络和低像素网络最后一层的特征相加,送入另一个系列的残差块,以输出最终图像
当前 SOTA!平台收录 vid2vid共1个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
Vid2vid |
前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/vid2vid |
VideoVAE
视频表达了视觉数据的高度结构化的时空模式。一个视频可以认为是由两个因素控制的。(i)时间上不变的(如人的身份),或缓慢变化的(如活动),属性引起的外观,编码每一帧的持久内容;(ii)帧间运动或场景动态(如编码执行动作的人的演变)。
VideoVAE是一个用于视频生成和未来预测的生成框架,通过将从潜在空间分布中依次抽取的样本解码为完整的视频帧来生成视频(短片段)。VAEs被用作编码/解码into/from潜在空间的帧的手段,而RNN被用作对潜在空间的动态建模的方式。通过对潜在空间进行属性控制来提高视频生成的一致性;确保在学习/生成过程中,属性可以被推断并作为条件。因此,给定属性和/或第一帧,VideoVAE能够生成不同的但高度一致的视频序列集。
在每个时间步长,VAE将视觉输入编码为一个高维潜在分布。这个分布被传递到一个LSTM,以编码在潜在空间中表达的运动。在每个时间步长,所产生的潜在分布可以被采样并解码为一个完整的图像。为了提高生成序列内的一致性,也为了控制生成过程,将VAE中的潜在空间扩展为具有整体属性控制的结构化潜在空间。整体属性控制可以被指定或从数据中推断出来;它可以随着时间的推移而固定,也可以表现出稀疏的过渡(见图8)。因此,在结构化潜在空间中提出的分层条件后验分布以多个关键信息源为条件进行预测。此外,还提出了条件抽样,以利用以前的样本来产生时间上连贯的序列。
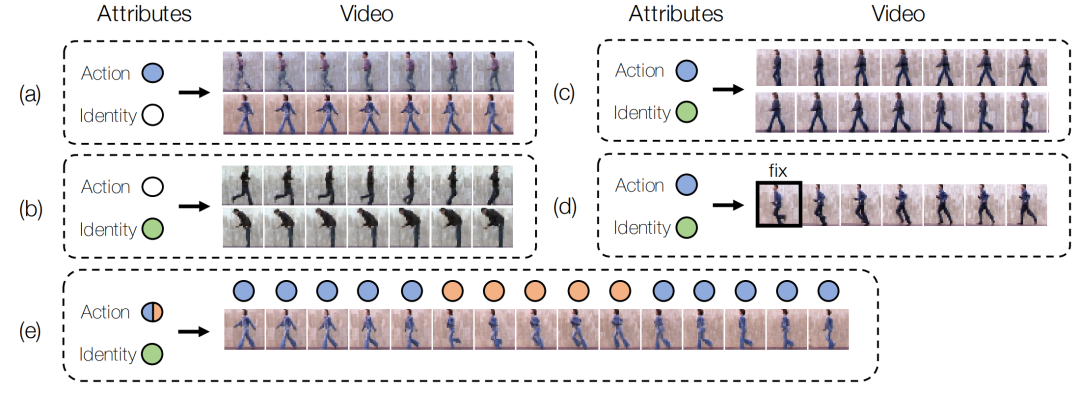
图8. 使用属性控制的视频生成。使用一个包含固定数量控制信号的半监督的潜在空间来引导生成过程。将 "动作 "和 "身份 "中的一个(a-b)或两个(c)属性设置为所需的或推断的类别(彩色圆圈)限制了生成过程,利用剩余的自由度来合成不同的视频样本。在(d)中,对两个属性以及第一帧的调节有效地消除了生成过程中的所有不确定性(自由度)。在(e)中,在第6和第11帧诱导了从 "走 "到 "跑 "再回到 "走 "的属性转换,从而在生成的视频中产生了图示的相应转换
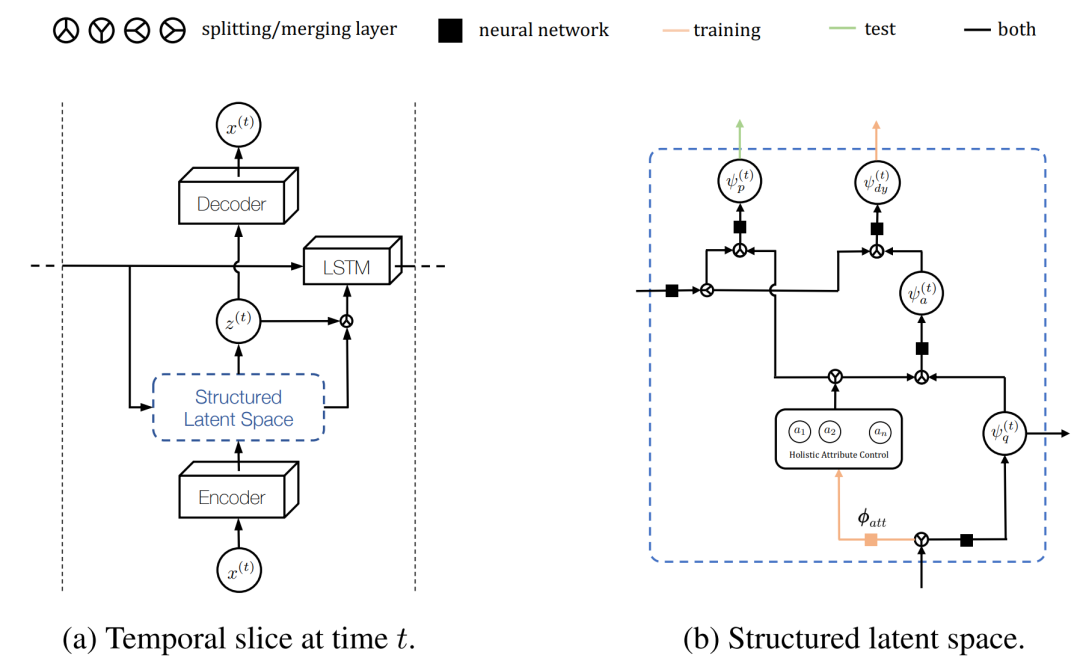
图9. VideoVAE概述,(a) VAE的结构化潜在表示编码了一个条件近似后验,在LSTM的帮助下通过时间传播。(b) 图9a中虚线框的详细说明:在一个分层过程中,整体属性首先与变异近似后验合并,然后与来自LSTM的时间信息整合,有效地产生了一个双条件动态近似后验
Holistic Attribute Control
整体属性a = (ai)i是一组预定义的属性,不随时间变化。例如,人类动作序列中的人的身份或一般视频片段中的场景标签。这些固定的属性变量对整个生成的视频序列进行整体控制,一般来说,可以是各种类型:分类的、离散的或连续的。它们的状态可以clamped在一个期望值上,从数据中推断出来,甚至可以从一些外部数据源中推导出来。在VideoVAE中,控制是在训练时以半监督的方式推断出来的,并在生成过程中设置为固定的。
Conditional Approximate Posterior
传统的VAE将数据编码为一个近似的后验分布,并从先验中取样来合成新的数据。这在图像生成中效果很好,因为每个合成的图像可以独立采样。然而,在视频生成中,连续的样本应该在时间上是一致的。换句话说,样本的提取应该以先前的信息为条件,而且样本的顺序也很重要。潜在编码Z应该将这种帧级一致性与上面讨论的整体控制变量所提供的序列级一致性结合起来。提出以下结构化的潜在空间,它包括一组分层的近似后验分布(图9b)。
1)一个初始的近似后验分布,N,从概念上对整体属性没有捕捉到的剩余信息进行建模。
2)一个条件近似后验,N,编码帧的全部外观,将整体属性控制与上述剩余后验相结合。
3)一个动态的近似后验,N,它进一步纳入了运动信息,并强制执行时间上一致的轨迹。
这三个分布可以用编码的输入、属性和LSTM状态来表示:
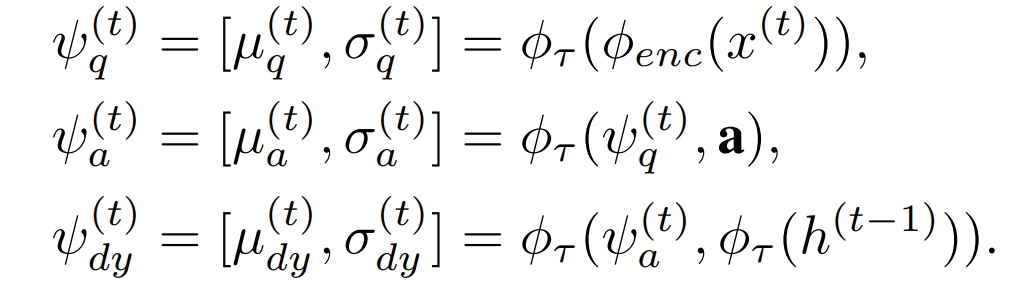
Decoder
在时间步长t的潜在变异表征是以LSTM的状态变量h(t-1)为条件的。这种额外的依赖性利用了视频在时间上高度一致的事实,防止两个连续帧之间的内容和运动变化过快。由于先验分布代表了模型在时间点t的预测和信念,考虑到以前的所有信息,它不应该是一个固定的高斯(如静态VAE的情况),而是遵循分布
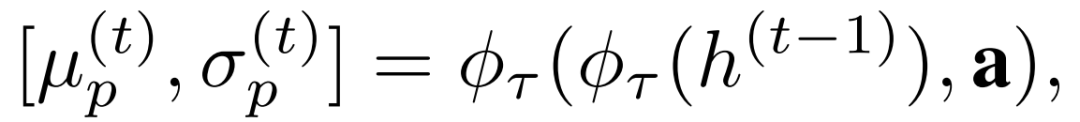
输出分布根据以下公式更新
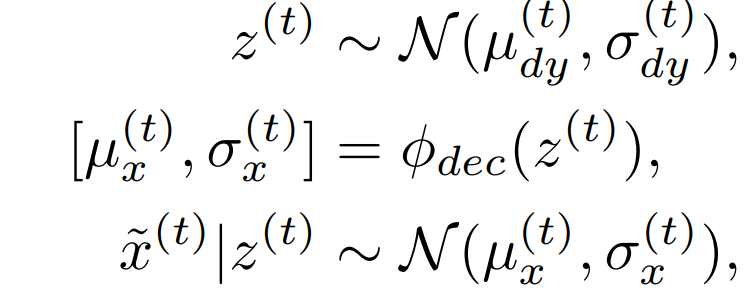
Encoder
在每个时间步长,帧输入x(t)被编码器函数φenc映射到分层潜在空间(图9b),解码器从中采样

Conditional Sampling
在迄今为止描述的时间框架中,只有分布N被传递给LSTM。换句话说,每个时间步长的样本没有沿着时间传递,因此是独立的,导致时间上不一致的序列(例如,就解码的RGB帧所表达的属性而言)。根据基于LSTM的语言解码器的直觉,引入了条件采样来解决这个问题。除了初始的近似后验分布N外,样本z(t)也被传递给LSTM(图9a)。因此,LSTM的隐藏状态会根据以下条件更新
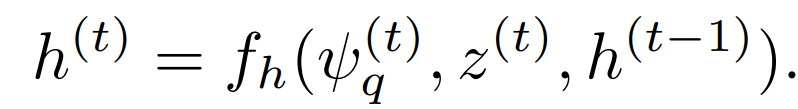
这样一来,基于过去的信息,对样本z(t+1)在N中的位置有了合理的初始猜测。值得注意的是,由于模型的VAE结构,与语言翻译模型等相比,这种变化不需要改变架构本身。
当前 SOTA!平台收录 VideoVAE 共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| VideoVAE | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/videovae |
DVDGAN
DVDGAN是一个建立在最先进的BigGAN架构上的复杂人类行为的生成性视频模型,同时引入了可扩展的、针对视频的生成器和鉴别器架构。其生成器不包含前景、背景或运动(光流)等明确先验;相反,依靠一个高容量的神经网络以数据驱动的方式来学习这些。虽然DVD-GAN包含序列组件(RNNs),但它在时间和空间上都不是自回归的。换句话说,每一帧的像素并不直接取决于视频中的其他像素,就像自动回归模型或每次生成一帧的模型那样。
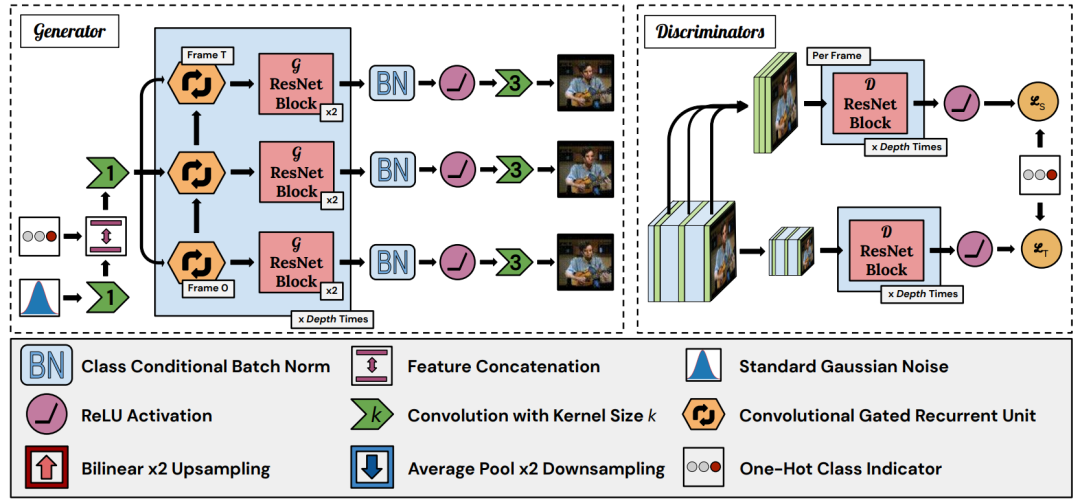
图10. DVDGAN架构
DVD-GAN通过使用两个鉴别器来解决视频生成中的尺度scale问题:空间鉴别器DS和时间鉴别器DT。DS通过随机抽取k个全分辨率的帧并对其进行单独评判,来评判单帧内容和结构。DS的最终得分是每一帧的得分之和。时间鉴别器DT必须向G提供学习信号,以产生运动(这不是由DS评估的)。为了使模型具有可扩展性,对整个视频应用一个空间降采样函数φ(-),并将其输出反馈给DT。这导致了一种结构,即鉴别器不处理整个视频的像素,因为DS只处理k×H×W像素,DT只处理T×H2×W2。对于一个128×128分辨率的48帧视频来说,这就把每个视频需要处理的像素数从786432减少到327680:减少58%。尽管有这样的分解,鉴别器的目标仍然能够惩罚几乎所有的不一致,而这些不一致会被判断整个视频的鉴别器所惩罚。DT判断整个视频长度上的任何时间差异,而DS可以判断任何高分辨率的细节。DVD-GAN鉴别器目标唯一不能反映的细节是2×2窗口内像素的时间演变。DVD-GAN的DS类似于MoCoGAN中的每一帧判别器DI。然而,与MoCoGAN类似的DT着眼于全分辨率视频,而DS是DVD-GAN中高分辨率细节的唯一学习信号来源。由于这个原因,当φ不是身份时,DS是必不可少的,这与MoCoGAN不同,在MoCoGAN中,额外的每帧判别器不那么关键。
G的层常数对于64×64的视频来说是[8, 8, 8, 4, 2],对于128×128来说是[8, 8, 8, 4, 2, 1]。第i层的宽度由ch和第i个常数的乘积给出,在G的残差网络之前的所有层都使用初始层的乘积,把它和ch的乘积称为ch0。对于64×64分辨率的视频,DVD-GAN中的ch为128,否则为96。对于64×64分辨率的视频,DT和DS的相应ch列表为[2, 4, 8, 16, 16],对于128×128的视频,则为[1, 2, 4, 8, 16, 16]。G的输入包括一个高斯潜在噪声z∼N(0, I)和一个所需类别y的学习线性嵌入e(y),两个输入都是120维的向量。G开始计算[z; e(y)]到[4, 4, ch0]形张量的仿射变换(在图10中表示为1×1卷积)。[z; e(y)]被用作整个G的所有类别条件下的批量归一化层的输入。然后将其作为卷积门控递归单元的输入(在我们想要生成的每一帧),该单元对输入x_t和先前输出h_t-1的更新规则如下
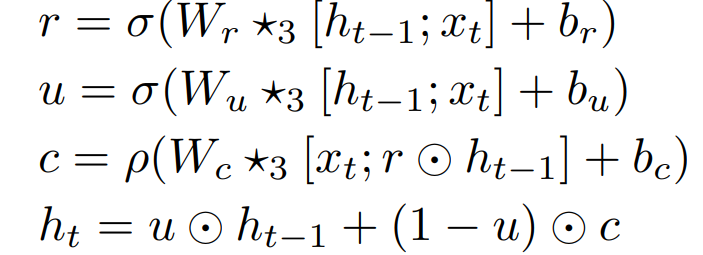
在这些方程中,σ和ρ分别是元素的sigmoid和ReLU函数。括号用于表示特征串联。这个RNN每帧unrolled一次。在这里,时间维度与批处理维度相结合,因此每一帧都独立地通过这些块进行。这些区块的输出的宽度和高度尺寸都是双倍的(我们在第一个区块中跳过了上采样)。这样重复多次,将一个RNN+残差组的输出作为下一个组的输入,直到输出的张量具有所需的空间尺寸。在计算批量归一化统计时,不在时间维度上进行还原。这可以防止网络利用批量归一化层在各时间段之间传递信息。空间判别器DS的功能与BigGAN的判别器几乎相同,在图11中给出了残差块的概述。对均匀采样的k个帧(默认为k=8)中的每一个计算得分,DS的输出是每帧得分的总和。时间鉴别器DT有一个类似的架构,但用一个2×2的平均集合下采样函数φ对真实或生成的视频进行预处理。此外,DT的前两个残差块是三维的,其中每个卷积都被一个内核大小为3×3×3的三维卷积所取代。其余架构与BigGAN一致。

图11. G和DS/DT的残差块
当前 SOTA!平台收录 DVDGAN 共1个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| DVDGAN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/dvd-gan-fp |
SWGAN


SWD的基本思想是将高维分布的挑战性估计分解为多个一维分布的较简单估计。PX, PY分别表征随机变量X, Y的概率分布。对于单位向量θ∈S^(n-1),定义相应的内积π_θ(x)=θ^T x和边际分布π∗_θP_X = P_X ◦π^(-1)_θ。基本SWD为
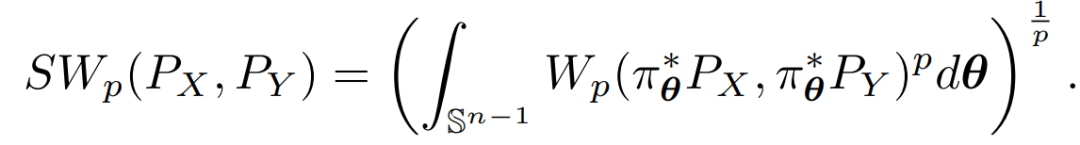
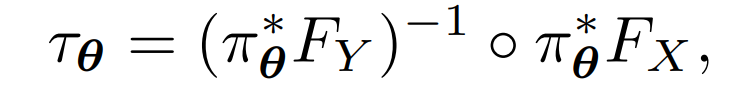
可以得到
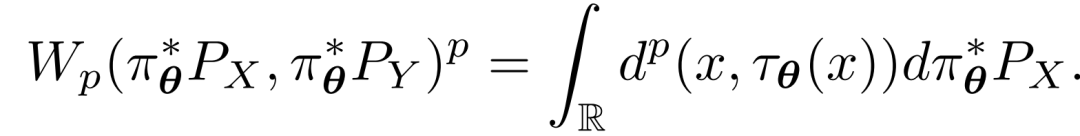
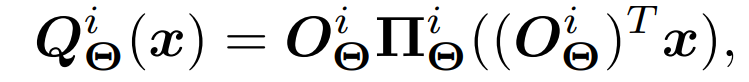
由于基于AE的生成模型需要在编码器上强加一个先验分布,所以可以对上式进行改进以使其可学习并将其纳入编码器。通过将原始SWD块(层)堆叠在标准编码器之上,为传统的自动编码器提供了生成能力。编码器Q是由标准编码网络E和m个原始SWD块S_(p,1),. . . , S_(p,m),即Q = S_(p,m)◦. .◦S_(p,1)◦E组成的。通过将E中的潜在编码送入原始SWD块S_(p,1),. . . , S_(p,m),潜在编码的分布被转移到先验分布中。作者在文章中具体选择了高斯分布作为先验分布,因为它经常被用于基于AE的模型。
WGAN的成功表明,dual WD可以作为GAN模型判别器的一个合适目标。为了保持这种设置的优点,同时避免对高维分布施加k-Lipschitz约束,作者建议可以使用dual SWD来代替。dual SWD为
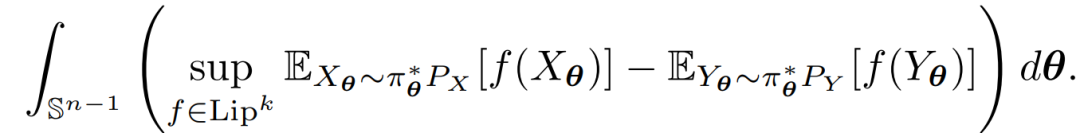
| 项目 | SOTA!平台项目详情页 |
|---|---|
SWGAN |
前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/pg-swgan-3d |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。

