NAM、RAS、MTLSum、BottleSUM…你都掌握了吗?一文总结文本摘要必备经典模型(二)
机器之心专栏
本专栏由机器之心SOTA!模型资源站出品,每周日于机器之心公众号持续更新。
本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 2 期进行连载,共介绍 17 个在文本摘要任务上曾取得 SOTA 的经典模型。
第 1 期:CopyNet、SummaRuNNer、SeqGAN、Latent Extractive、NEUSUM、BERTSUM、BRIO
第 2 期:NAM、RAS、PGN、Re3Sum、MTLSum、KGSum、PEGASUS、FASum、RNN(ext) + ABS + RL + Rerank、BottleSUM
您正在阅读的是其中的第 2 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
第1期回顾:CopyNet、SeqGAN、BERTSUM…你都掌握了吗?一文总结文本摘要必备经典模型(一)
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| NAM | https://sota.jiqizhixin.com/models/models/2072950a-5014-41a7-8801-5b894e5bb4a5收录实现数量:1支持框架:Torch | A Neural Attention Model for Abstractive Sentence Summarization |
| RAS | https://sota.jiqizhixin.com/models/models/0544ead9-de12-46b0-8fcd-61737f9951af收录实现数量:1支持框架:Torch | Abstractive Sentence Summarization with Attentive Recurrent Neural Networks |
| PGN | https://sota.jiqizhixin.com/models/models/c317f698-b7f3-46d3-abc1-f93c5f5f2b90收录实现数量:3支持框架:PaddlePaddle、TensorFlow、PyTorch | Get To The Point: Summarization with Pointer-Generator Networks |
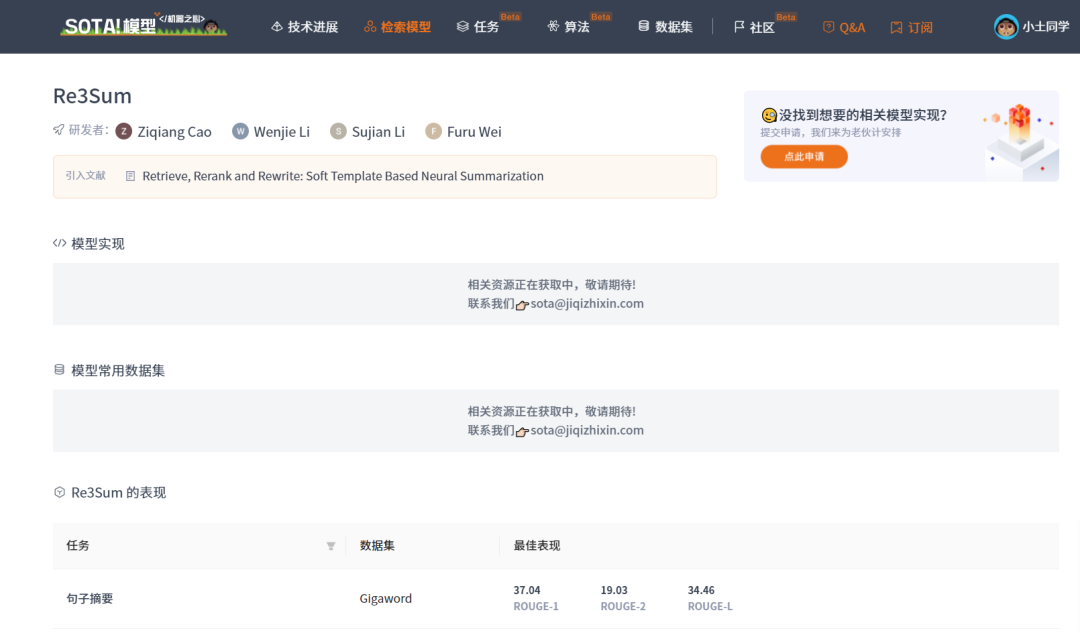
| Re3Sum | https://sota.jiqizhixin.com/models/models/13859f1c-16a3-4b81-81f8-f85d078d91f4 | Retrieve, rerank and rewrite: Soft template based neural summarization |
| MTLSum | https://sota.jiqizhixin.com/models/models/1ee02eca-5042-4709-8bd1-af02d20bd262 | Soft Layer-Specific Multi-Task Summarization with Entailment and Question Generation |
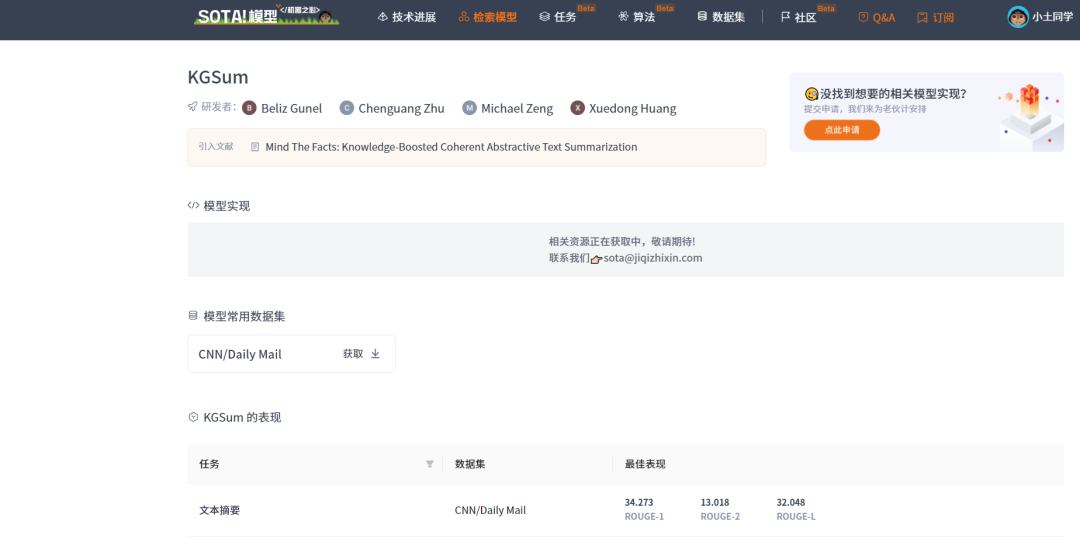
| KGSum | https://sota.jiqizhixin.com/models/models/686f5a34-89a0-46c2-8270-ab62674c4e3f | Mind The Facts: Knowledge-Boosted Coherent Abstractive Text Summarization |
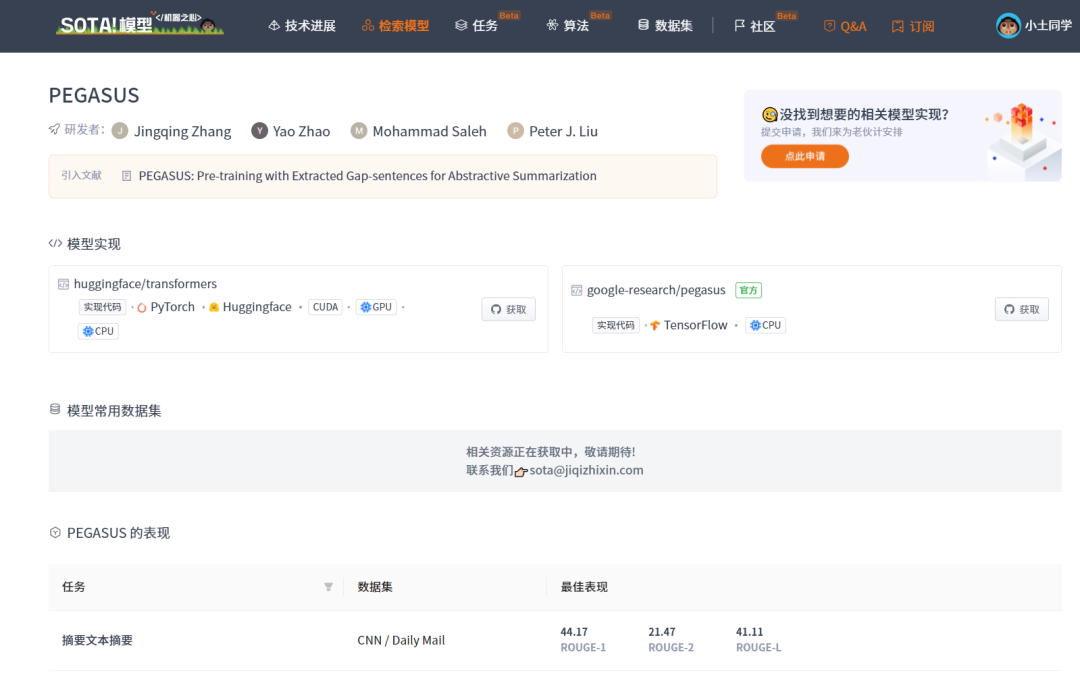
| PEGASUS | https://sota.jiqizhixin.com/models/models/161a361b-4102-415e-8f87-d00b9df241fa收录实现数量:2支持框架:TensorFlow、PyTorch | PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization |
| FASum | https://sota.jiqizhixin.com/models/models/f07ad4a0-8360-40e2-bcaa-2c820116150e收录实现数量:1 | Enhancing Factual Consistency of Abstractive Summarization |
| RNN(ext) + ABS + RL + Rerank | https://sota.jiqizhixin.com/models/models/bb9e36ba-3f90-43d2-a98c-d41e5adfe870收录实现数量:1支持框架:PyTorch | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting |
| BottleSUM | https://sota.jiqizhixin.com/models/models/88b14617-ab92-4626-a2c8-81fd9aa0720d收录实现数量:1支持框架:PyTorch | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle |
文本摘要可以看做是一种信息压缩技术,具体是指利用技术从单个文本或多个文本(文本集合)中抽取、总结或提炼要点信息,以概括展示原始文本(集)中的主要信息。在互联网快速发展的现代社会,文本摘要的作用越来越重要,可以帮助人们从海量数据中快速发现所需要的信息。文本摘要成为了自然语言处理(NLP)领域的一项重要技术。
传统的文本摘要可以分为抽取式摘要和生成式摘要两种方法。抽取式摘要是通过抽取拼接源文本中的关键句子来生成摘要,优点是不会偏离原文的信息,缺点是有可能提取信息错误,或者出现信息冗余、信息缺失。生成式摘要则是系统根据文本表达的重要内容自行组织语言,对源文本进行概括,整个过程是一个端到端的过程,类似于翻译任务和对话任务,因此,生成式摘要方法可以吸收、借鉴翻译任务和对话任务的成功经验。与传统方法对应的,应用于文本摘要的神经网络模型也有抽取式模型、生成式模型以及压缩式模型三类。其中,抽取式模型主要是将问题建模为序列标注和句子排序两类任务,包括序列标注方法、句子排序方法、seq2seq三种;生成式模型则主要是以seq2seq、transformer为基础的引入各类辅助信息的生成式模型;压缩式模型主要是基于information bottleneck的模型,也可称为是抽取式和生成式混合的模型。
第一,抽取式模型的核心思想是:为原文中的每一个句子打一个二分类标签(0 或 1),0 代表该句不属于摘要,1 代表该句属于摘要,最终由所有标签为 1 的句子进行排序后生成摘要。这种方法的首要要求就是将自然语言转化为机器可以理解的语言,即对文本进行符号数字化处理,为了能表示多维特征,增强其泛化能力,可以引入向量的表征形式,即词向量、句向量。基于seq2seq的抽取式模型的文本摘要需要解决的问题是从原文本到摘要文本的映射问题。摘要相对于原文具有大量的信息损失,而且摘要长度并不会依赖于原文本的长度,所以,如何用简短精炼的文字概括描述一段长文本是seq2seq文本摘要需要解决的问题。
第二,生成式模型主要是依托自然语言理解技术,由模型根据原始文本的内容自己生成语言描述,而非提取原文中的句子。生成式模型的工作主要是基于seq2seq模型实现的,通过添加额外的attention机制来提高其效果。此外,还有一些模型以自编码为框架利用深度无监督模型去完成生成式摘要任务。再者,还可以引入GPT等预训练模型做fine-tune,改进摘要的生成效果。
第三,压缩式模型则是先通过某种方法将源文档做一个压缩,得到一个长度较为合适的文本。然后以压缩后的文本为目标,训练生成式模型最终得到目标模型。压缩式模型也可以看作是抽取式模型和生成式模型的结合。我们在这篇文章介绍文本摘要中必备的TOP模型,介绍是根据不同类型的模型分组进行的,同一类别的模型介绍则是按照模型提出的时间顺序来完成的。
一、生成式摘要模型
1.1 NAM
NAM是使用attention机制进行生成式文本摘要的第一篇文章,主要使用Attention+seq2seq构建摘要模型。不过模型直接生成摘要的效果并不太好,增加一些人工特征后,效果能大幅提升。NAM是一种完全由数据驱动的抽象化句子摘要方法,利用一个基于局部注意力的模型,根据输入的句子生成每个词的摘要。虽然该模型结构简单,但它可以很容易地进行端到端训练,并可扩展到大量的训练数据。
解码器部分:
NAM的解码器由标准的前馈神经网络语言模型(neural network language mode,NNLM)改编而成。神经网络语言模型参数化的核心实际上是得到摘要文本下一个词语的概率,输入文本与前文窗口经由编码器生成一个向量,该向量代表了输入文本与已生成文本。隐藏层由文本窗口乘以词向量与权重矩阵得到。下一个词的概率由文本窗口与输入文本共同决定,整个模型也体现了编码器与神经语言共同训练的核心。图1a给出了一个解码器结构的示意图。黑盒函数enc是一个上下文编码器术语,它返回一个大小为H的向量,代表输入和当前的上下文。刨除enc就是一个标准的语言模型,通过引入enc,并在训练中同时考虑这两个要素,就可以在生成阶段考虑文本本身。
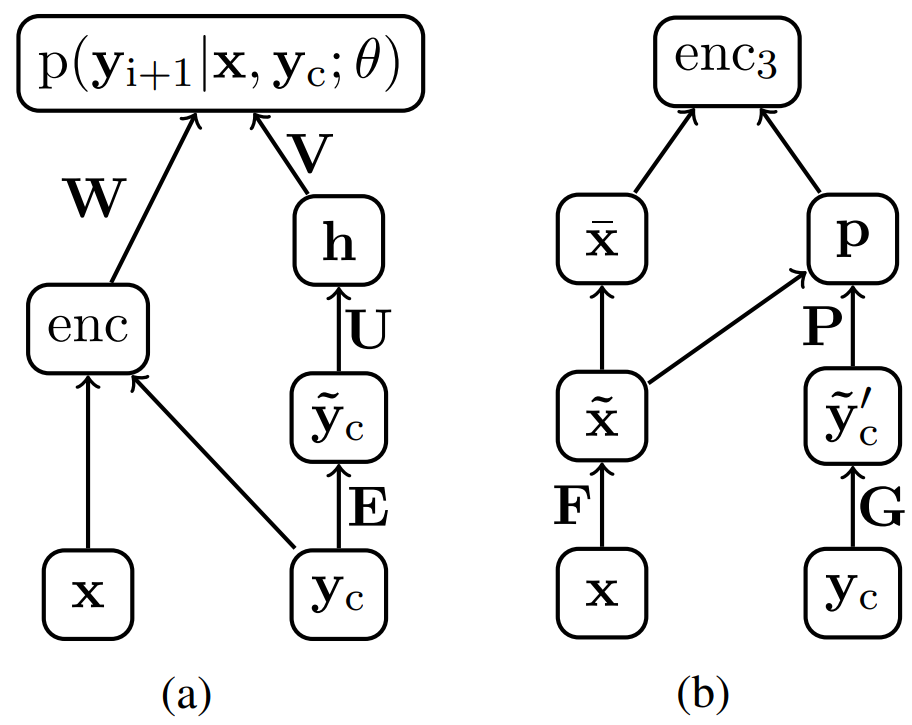
图1. (a) 带有额外编码器的NNLM解码器的网络图。(b) 基于注意力的编码器enc3的网络图
编码器部分:
对于编码器的选择,词袋模型(bag-of-words)编码器不能反映出词与词之间的语义关系与顺序,卷积编码器(convolutional encoder)比较复杂,并且只能为整个输入句子产生一个单一的表征。NAM采用的有监督编码器结构简单,类似于词袋模型的模型,以下是编码器的全部模型:
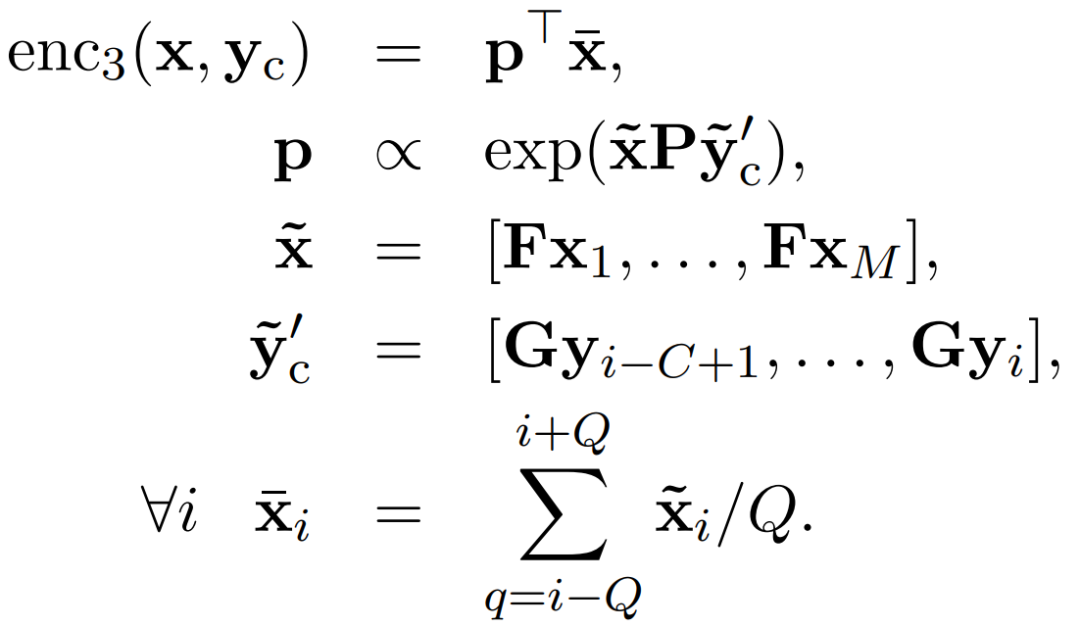
生成部分:
最后,通过求解下式,生成摘要:
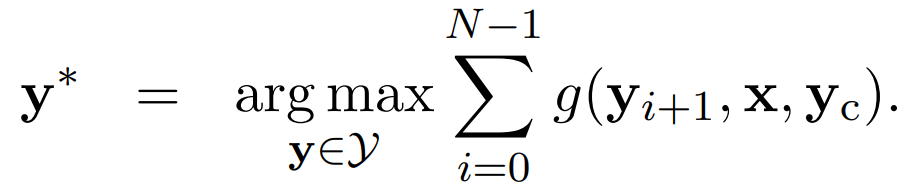
作者最终采用了集束搜索(beam-search)解码来求解上述的公式,下面是beam-search算法的详细步骤:

当前 SOTA!平台收录NAM共 1 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| NAM |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/2072950a-5014-41a7-8801-5b894e5bb4a5 |
1.2 RAS
RAS 和NAM是同一个研究小组的工作,因此与NAM的模型架构非常相似。两个模型都采用seq2seq+attention的结构,都是句子层面(sentence-level)的seq2seq,区别在于选择encoder和decoder的模型,NAM模型偏容易一些,而RAS用了RNN来做。
编码器:
输入句子每个词最终的嵌入是各词的嵌入与各词位置的嵌入之和,经过一层卷积处理得到aggregate vector:
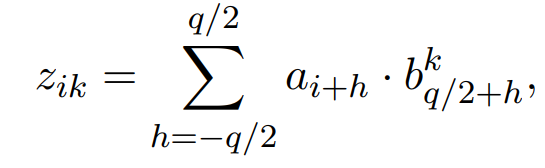
根据aggregate vector计算context(encoder的输出):
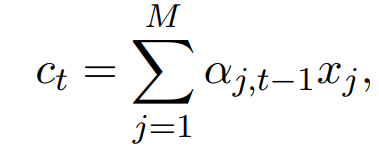
解码器:
解码器的部分是一个RNNLM,这里的RNN Hidden Layer使用的是LSTM单元。解码器的输出由下式计算:

其中c(t)是encoder的输出,h(t)是RNN隐藏层,由下式计算:
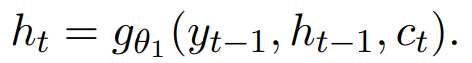
这里隐藏层的单元有两种思路,一种是常规的Elman RNN,一种是LSTM。
生成:
RAS的生成部分和NAM一样,也是用beam search生成摘要。
当前 SOTA!平台收录RAS共 1 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| RAS |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/0544ead9-de12-46b0-8fcd-61737f9951af |
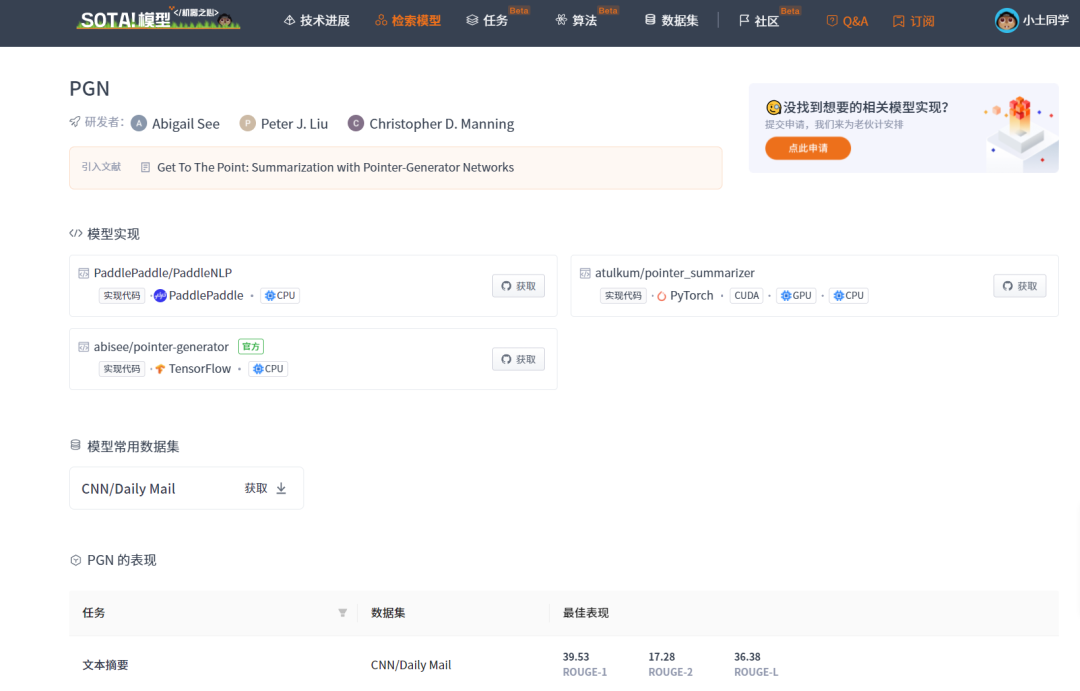
1.3 PGN
应用于文本摘要生成任务的seq2seq模型存在两个问题:容易忽略到文本中的细节;容易不断地重复自身。PGN(常被称为指针生成网络)以两种正交的方式增强了标准的seq2seq注意力模型。首先,使用一个混合的指针-生成器(pointer-generator)网络,它可以通过指针从源文本中复制单词,从而有助于准确地复制信息,同时保留通过生成器产生新单词的能力。其次,使用覆盖率来跟踪已概括的内容,阻止了重复现象。
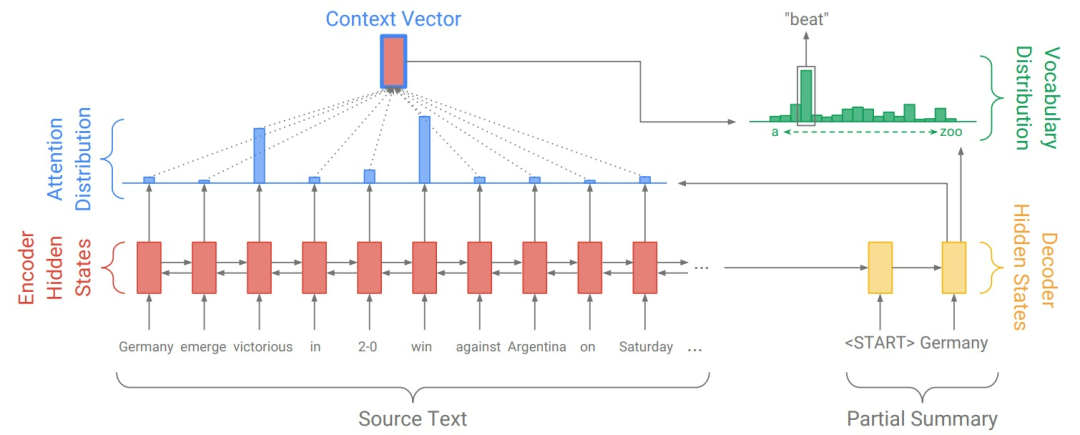
图2. 经典的seq2seq注意力模型
图2为经典的seq2seq注意力模型结构。将文本w_i的token逐一输入编码器(单层双向LSTM),产生一串编码器的隐状态h_i。在每一步t,解码器(单层单向LSTM)接收前一个词的词嵌入(在训练时,这是参考摘要的前一个词;在测试时,这是解码器发出的前一个词),对应解码器状态s_t。
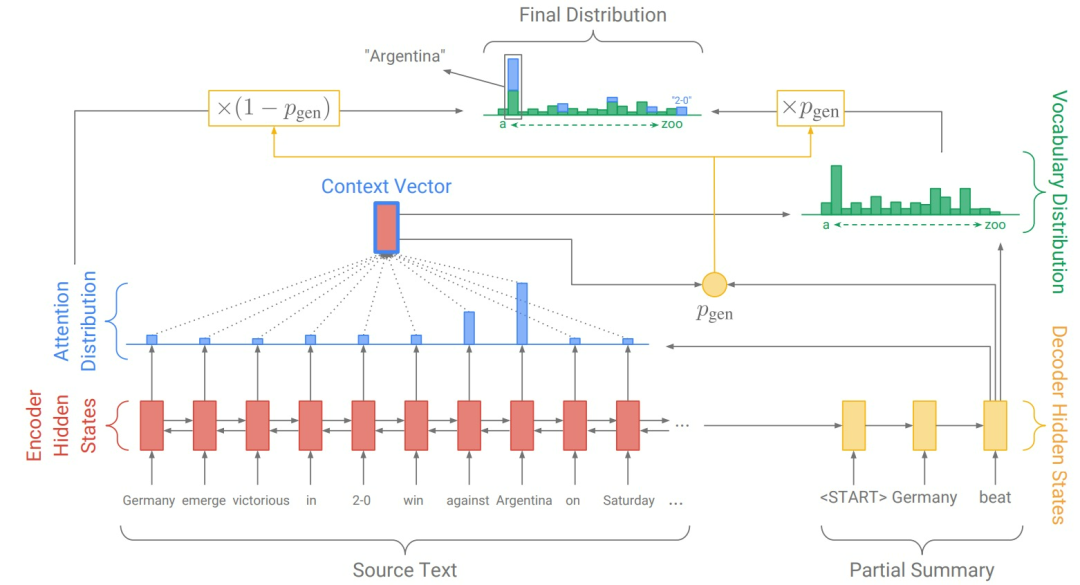
图3. PGN架构
PGN是图3中基线模型和指针式网络的混合体,它既可以通过指向复制单词,又可以从固定的词汇中生成单词。与基于 attention 的端到端系统相比,PGN具有以下优点:PGN让从源文本生成单词变得更加容易。这个网络仅需要将足够多的 attention 集中在相关的单词上,并且让PGN 足够的大;PGN可以复制原文本中的非正式单词,这样我们能够处理那些没出现过的单词,同时也允许我们使用更小规模的词汇集(需要较少的计算资源和存储空间);PGN能够被更快地训练,尤其是训练的前几个阶段。
此外,引入Coverage机制解决经典模型的重复性问题。在coverage model中,主要维持coverage vector,是之前所有解码器时间步长的注意力分配总和,也就是某个特定的源词的收敛就是到此刻它所受到 attention 的和:

其中,c^t 是对源文本单词的分布,它表示到目前为止这些词从注意力机制接收到的覆盖程度。c_0 是一个零向量,因为在第一个时间步长中,没有覆盖任何源文本。此时,注意力机制为:
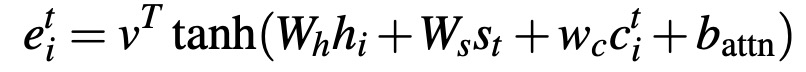
其中,w_c是一个与v相同长度的可学习参数向量。这确保了注意力机制的当前决策(选择下一个关注点)是由其以前的决策(总结为c_t)提醒的。
当前 SOTA!平台收录 PGN 共 3 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| PGN |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/c317f698-b7f3-46d3-abc1-f93c5f5f2b90 |
1.4 Re3Sum
Re3Sum也是seq2seq2的文本摘要模型,其特点是利用已有的摘要作为软模板(soft template)来指导 seq2seq 模型。具体而言,首先使用信息检索平台(Lucene)从语料中检索合适的摘要作为候选模板,然后扩展 seq2seq 框架,使其具有模板排序(reranking)和基于模板生成摘要 (rewriting)的功能。

图4. Re3Sum流程图。虚线表示Retrieve,因为嵌入了一个IR( Information Retrieval )系统
如图4所示,Re3Sum模型主要包含三个模块,Retrieve, Rerank, Rewrite。在生成验证和测试时使用下式表示的得分(最大值)来筛选模板:
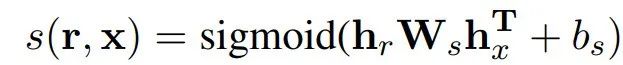
Retrieve模块:该模块目的是从训练语料中筛选合适的候选模板。这样做的前提是:相似的句子有相似的摘要模式。因为语料比较大,超过3M,所以采用IR系统Lucene来有效地创建索引,完成检索。根据输入句子(x)和索引句子的相似性来进行排序召回,得到候选soft template(r)。
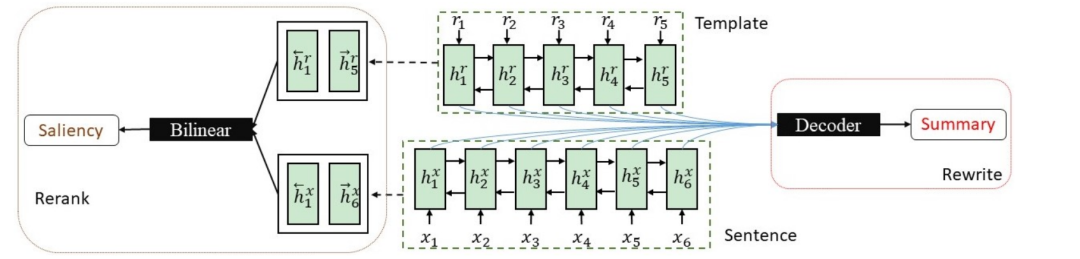
图5. 联合Rerank and Rewrite
Rerank模块:考虑到基于隐状态的匹配网络具有较强的检测两段文本相关性的能力,首先使用 Bidirectional Recurrent Neural Network(BiRNN)来对输入(x )和soft template(r )进行编码。使用BiRNN的输出来表示输入或者模板句子,然后使用双线性网络来计算输入和模板的相关性得分,筛选模板。Bilinear网络在相关性评估方面优于多层前向神经网络。
Rewrite模块:因为模板总是包含比较多的在原文本没有出现的命名实体,所以很难保证soft template能够很好的表示输入句子,所以采用seq2seq模型重新生成更准确可靠,更丰富的摘要。将输入和模板的隐状态连接起来作为生成摘要的解码器的输入。
生成模型:使用ROUGE得分来衡量soft template 和y*的相似度:

在训练时,使用上式表示的得分来筛选模板,这样做的目的是在训练是加速收敛,并且在实验中没有什么副作用。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| Re3Sum |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/13859f1c-16a3-4b81-81f8-f85d078d91f4 |
1.5 MTLSum
MTLSum将文本摘要生成作为主任务,将问题生成、蕴含生成作为辅助任务进行多任务学习,属于一种多任务学习模型。问题生成任务根据文本生成问题的任务,该任务需要模型有能力识别文本中的重要信息,并对此信息进行提问;使用该任务作为辅助任务,帮助摘要模型更好地掌握分辨重要信息的能力;蕴含生成任务根据文本生成逻辑上一致的假设的任务,该任务需要模型生成的内容与文本在逻辑上一致,要求模型学习有逻辑地生成的能力;使用该任务作为辅助任务,帮助摘要模型在生成文本摘要时,学会减少无关甚至相反内容的生成。
使用一个序列-注意力-序列模型,其中有一个2层的双向LSTM-RNN编码器和一个2层的单向LSTM-RNN解码器。x表征输入源文本,y表征输出。以输入源文本为条件的输出摘要生成词汇分布是:
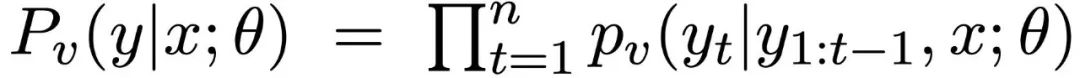
令解码器在时间步长t的隐状态为s_t,c_t为背景向量,定义为编码器隐状态的加权组合。将解码器(最后一个)RNN层的隐状态s_t和上下文向量c_t连接起来,并应用线性变换,然后通过另一个线性变换投射到词空间。最后,解码器每个时间步长t的条件词分布被定义为:
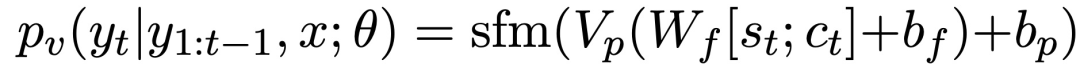
Pointer和Coverage Strategy的结构与PGN完全相同,不再赘述。
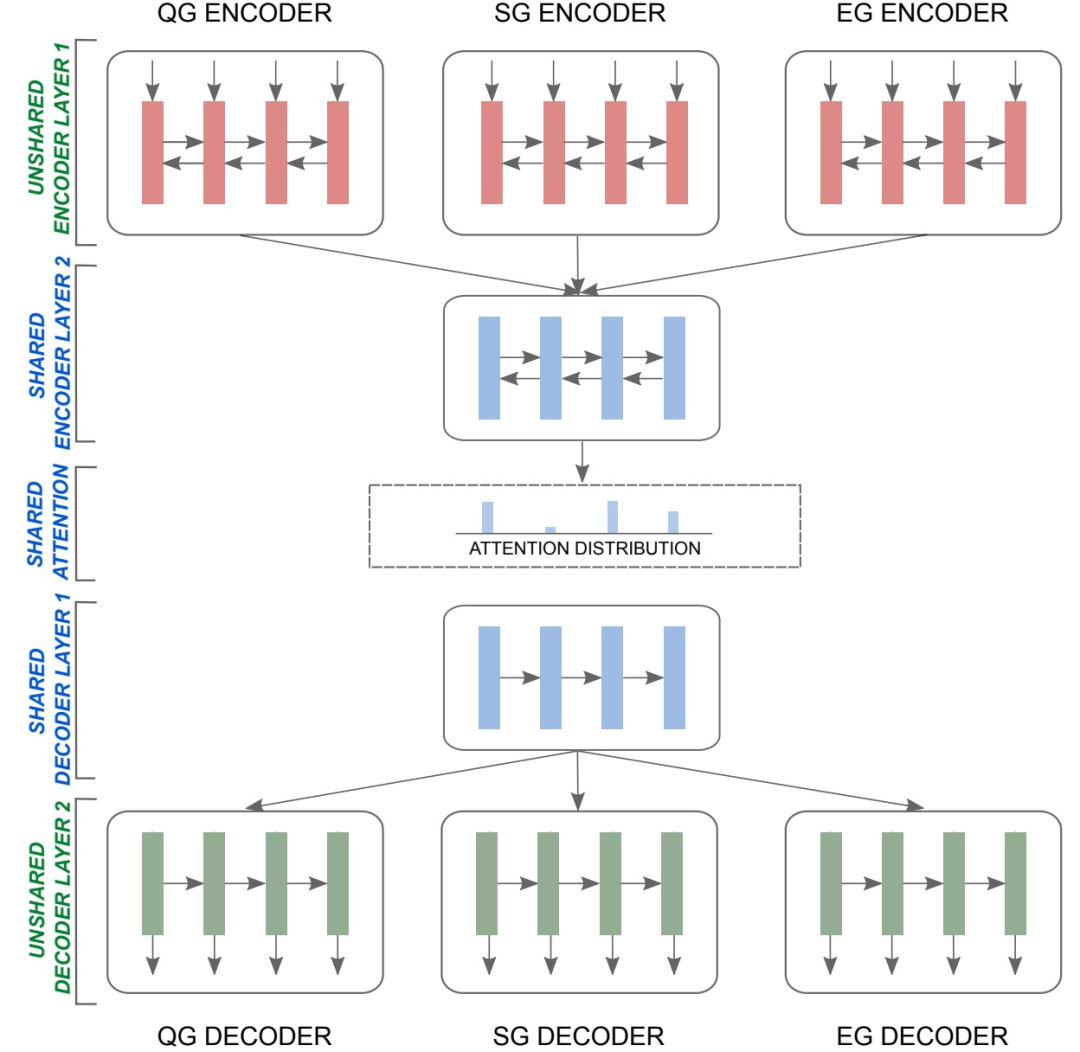
图6. 多任务模型概述,对三个任务进行平行训练:抽象摘要生成(SG)、问题生成(QG)和蕴含生成(EG)。在所有三个任务中共享 "蓝色 "表征,即第二层的编码器、注意力参数和第一层的解码器
如图6所示,主任务(SG)和两种辅助任务(QG、EG)采用相同的模型结构;三种任务的嵌入层、编码器的第一层和解码器的第二层的结构不共享,编码器的第二层、attention distribution和解码器的第一层的结构共享。模型采用的共享方式不是hard sharing,即共享的结构使用同一套参数;而是采用soft sharing,即共享的结构实际上有各自的参数,模型鼓励这些参数在参数空间的分布上趋同,使用L2 loss惩罚共享参数间的不同分布;soft sharing使模型具有更大的任务灵活性。使用损失函数如下:
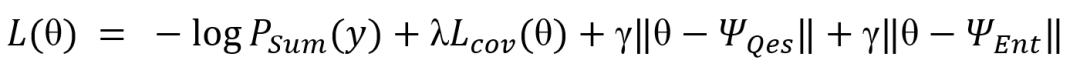
其中,第一项是主任务的CE Loss,第二项是卷积loss,第三项和第四项是soft sharing loss,鼓励共享结构的参数分布趋同。
在训练时,先分别在各自的语料上训练三个模型,直至三个模型达到90%的收敛度;然后使用上述的L(θ)进行多任务学习:先训练a个batch的SG任务,再训练b个batch的QG任务,再训练c个batch的EG任务,循环往复直至三个模型都收敛。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| MTLSum |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/1ee02eca-5042-4709-8bd1-af02d20bd262 |
1.6 KGSum
KGSum提出的baseline是Transformer-XL,相比vanilla Transformer,这种结构可以处理序列更长的输入,保持分段输入间的语义关系。Transformer-XL为语言建模中的长距离依赖问题提供了一个有效的解决方案。他们通过重用前面语段的隐状态,将递归概念引入到基于自注意力的模型中,并引入了相对位置编码的思想,使递归方案成为可能。KGSum将Transformer-XL扩展到基于Transformer架构的编码器-解码器架构。如图7所示,基于Transformer-XL注意力分解,计算每个多头注意力层的注意力分数。
KGSum扩展了编码器-解码器的结构,使实体信息能够有效地纳入模型中。在编码器一侧,有一个单独的实体注意力通道,与token的注意力通道并行。这两个通道之后是多头token自注意力和多头交叉token-entity注意力。在解码器一侧,有多头masked token自注意力,多头masked entity自注意力,以及编码器和解码器之间的多头交叉注意力。最后,还有另一层多头token注意力,然后是前馈层和softmax来输出token。
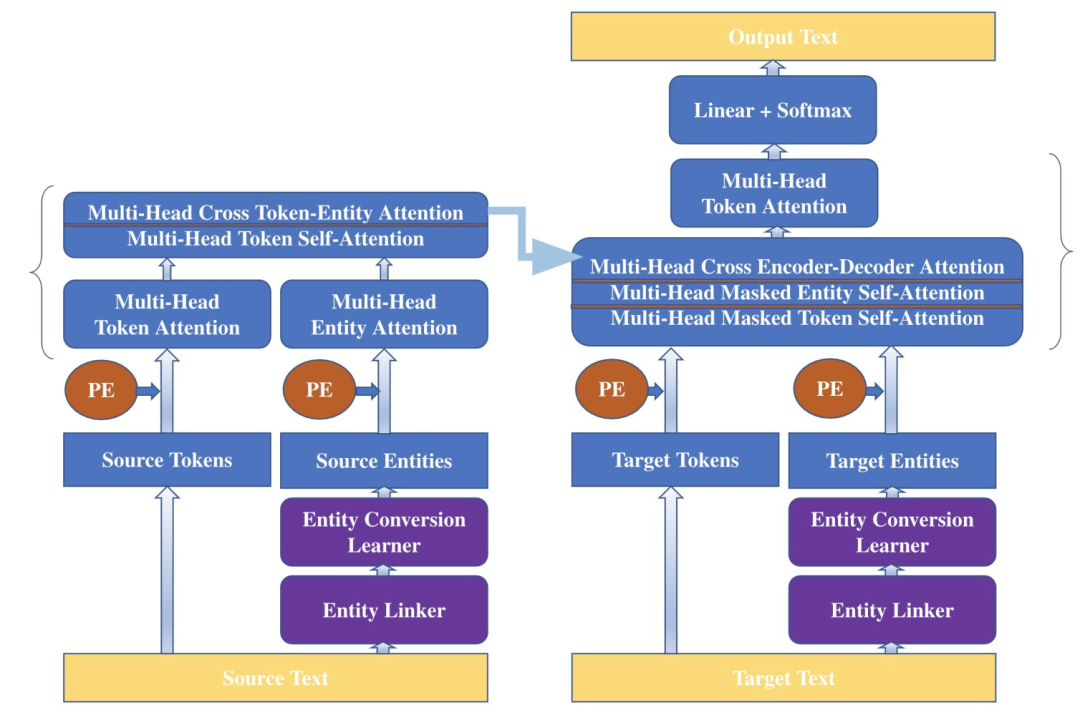
图7. KGSum模型架构。PE代表位置编码。单个编码器和解码器层在括号中显示。在多层架构中,大括号中的这些层是堆叠的
比较vanilla Transformer和Transformer-XL的注意力分解。下面的公式显示了在同一语段内查询Q_i和关键向量K_j之间的注意力计算。U矩阵表示绝对位置编码,E矩阵是token嵌入矩阵,W_q和W_k表示查询和关键矩阵。在Transformer-XL注意力表述中,R_(i-j)是没有可训练参数的相对位置编码矩阵:
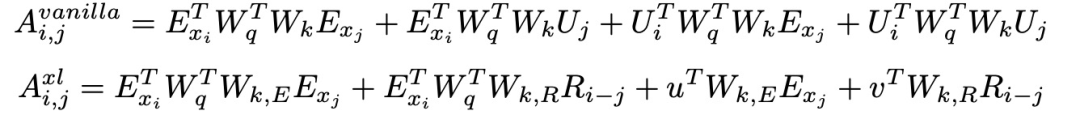
Transformer-XL的架构如下式所示,在第n个Transformer层的一个段τ,SG表示停止梯度,◦表示连接:
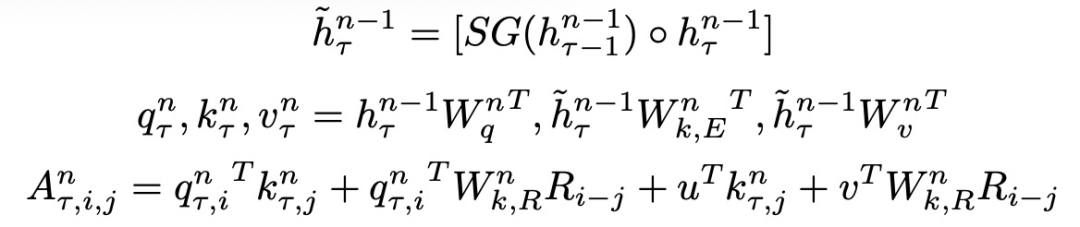
在多头注意力层之后,仍然有全连接的前馈网络层,以及在层归一化之后的子层周围的残差连接。为了简单起见,图7中省略了这些层。从经验上看,与Transformer基线模型相比,Transformer-XL 编码器-解码器架构生成的文本更加连贯。
实体链接器模块使用现成的实体提取器,并将提取的实体与Wikidata知识图谱进行歧义处理。提取的实体被初始化为预先训练好的维基数据知识图谱实体嵌入,这些实体嵌入是通过TransE学习的。实体转换学习模块使用一系列具有ReLU激活的前馈层。这些模块学习的实体与文本中的相应token处于同一子空间。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| KGSum |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/686f5a34-89a0-46c2-8270-ab62674c4e3f |
1.7 PEGASUS
与前述模型RNN-based的架构有着根本性的不同,PEGASUS是Transformer-based的。PEGASUS是一个标准的Transformer架构,在海量文本语料库上用一个新的自监督目标预先训练transformer-based的大型编码器-解码器模型。在PEGASUS中,重要的句子被从输入文件中移除/屏蔽,并从剩余的句子中一起生成一个输出序列,类似于提取式摘要。
PEGASUS架构如图8所示:
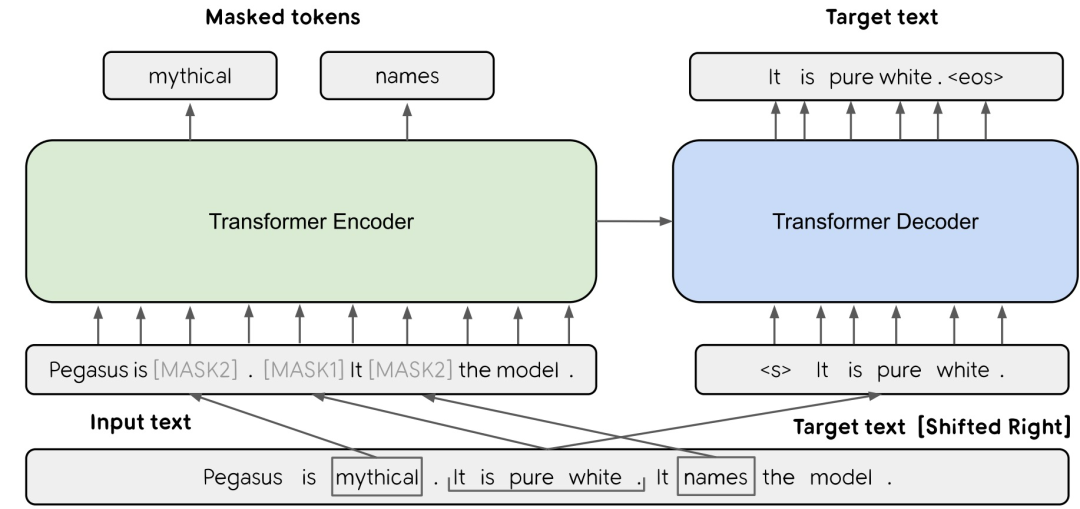
作者提出了一个新的预训练目标GSG。假设使用一个更接近下游任务的预训练目标会实现更好更快的微调性能,预训练目标涉及从输入文件中生成类似于概要的文本。为了利用海量文本语料进行预训练,设计了一个在没有abstactive summaries的情况下的seq2seq的自监督目标。最直观选择是一个预训练的抽取式摘要;然而,这样的程序只能训练一个模型来复制句子,因此不适合于抽象的总结。从文本中选择并屏蔽整个句子,并将空白句子串联成一个伪摘要。每个被选中的空白句的相应位置都被一个屏蔽标记[MASK1]所取代,以告知模型。空白句子比率(Gap sentences ratio,GSR)是指被选中的空白句子数量与文本中的总句子数量之比。为了更近似于摘要,选择对文本来说似乎很重要/很主要的句子。由此产生的目标既具有经验上证明的MASK的好处,又预示着下游任务的形式。
MLM:
在BERT之后,在输入文本中选择15%的token,被选择的token(1)80%的时间被掩码token [MASK2]取代,(2)10%的时间被随机token取代,(3)10%的时间没有改变。应用MLM来训练Transformer编码器,作为唯一的预训练目标或与GSG一起训练。
当前 SOTA!平台收录 PEGASUS共 2 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| PEGASUS |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/161a361b-4102-415e-8f87-d00b9df241fa |
1.8 FASum
FASum将知识图谱融入到自动摘要的生成中,提高自动摘要的事实准确性。作者在这篇文章中提出了一个事实感知的文本摘要模型FASUM,通过图关注来提取和整合事实关系到摘要生成过程中。此外,作者还设计了一个事实纠正器模型FC,以自动纠正由现有系统生成的摘要中的事实错误。
FASum利用建立在Transformer上的seq2seq架构,编码器产生文本的上下文嵌入,解码器关注编码器的输出以产生摘要。为了使摘要模型具有fact-aware,从源文本中提取、表征并将知识整合到摘要生成过程中。FASUM的整体架构如图9所示。

知识抽取。为了从文本中提取重要的实体关系信息,采用斯坦福OpenIE工具。提取的知识是一个元组的列表。每个元组包含一个主题(S)、一个关系(R)和一个对象(O),每个都是文本中的一段文字。
知识表征。构建一个知识图谱来表示从OpenIE中提取的信息。应用Levi转换来平等对待每个实体和关系。详细来说,假设一个元组是(s, r, o),创建节点s、r和o,并添加边s-r和r-o。我们得到一个无向知识图谱G=(V,E),其中每个节点v∈V都与文本t(v)相关联。在训练期间,这个图G是为每个批次(batch)单独构建的,也就是说,没有共享的巨大图。在推理过程中,模型可以接受未见过的实体和关系。然后采用一个图注意力网络来获得每个节点v_j的嵌入e_j。v_j的初始嵌入是由应用于t(v_j)的双向LSTM的最后隐状态给出的。
知识融合。知识图谱的嵌入是与编码器并行获得的。然后,除了对编码器的输出进行典型的交叉关注外,每个解码器块也对知识图谱节点的嵌入进行交叉关注的计算:
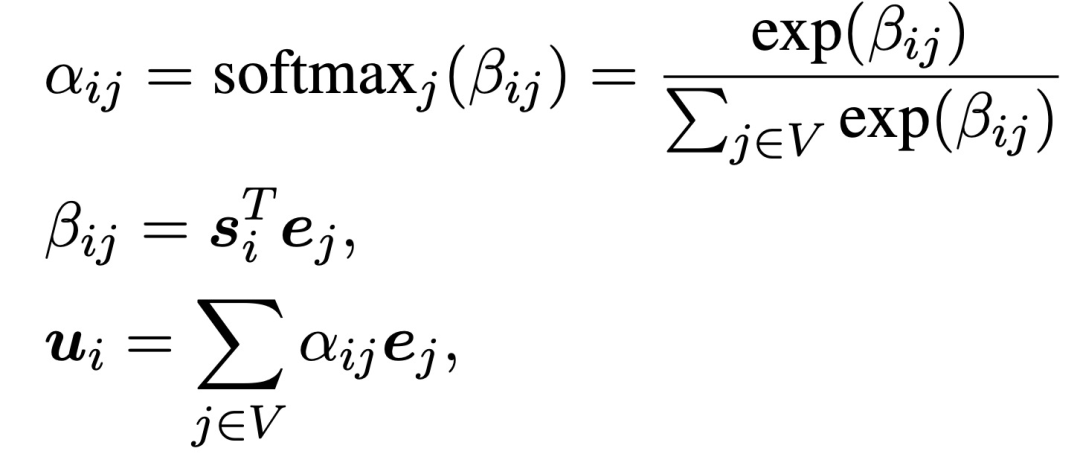
摘要生成。把解码器的最终输出表征为z_1, ..., z_t。为了生成下一个token y_t+1,采用线性层W将z_t投射到与字典相同大小的向量中。而预测的y_t+1的分布由以下方式得到:
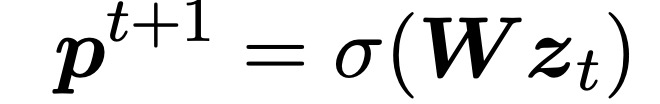
在训练过程中,使用交叉熵作为损失函数L(θ):
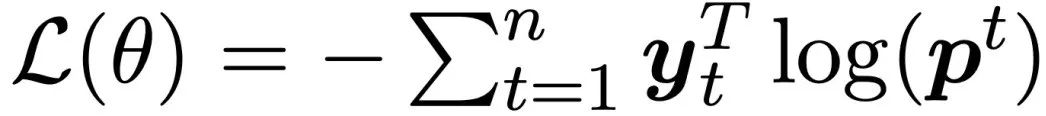
其中y_t是第t个token的one-hot向量,θ代表网络中的参数。
当前 SOTA!平台收录 FASum共 1 个模型实现资源。

| 模型 | SOTA!平台模型详情页 |
|---|---|
| FASum |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/f07ad4a0-8360-40e2-bcaa-2c820116150e |
二、压缩式模型
2.1 RNN(ext) + ABS + RL + Rerank
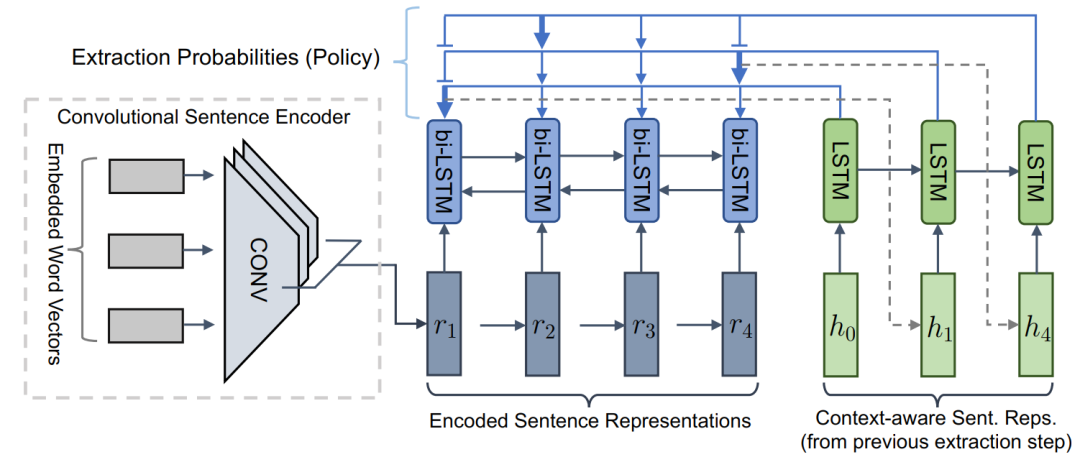
在得到文本中每个句子的表征后,为了在上述句子表征的基础上选择提取的句子,增加一个LSTM-RNN来训练一个指针网络 ,来反复提取句子。通过以下方式计算提取概率使用指针网络来进行句子的选择,每个句子被选择的概率为:
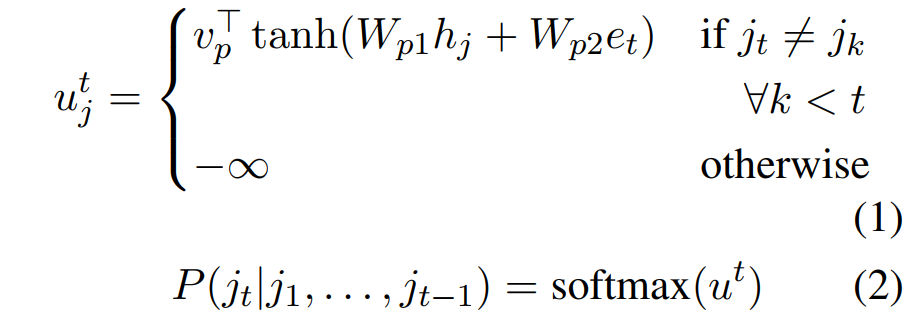

摘要器网络近似于g,它将提取的文本句子压缩并转述为一个简洁的摘要句。这里使用的是标准的编码器-对齐器-解码器(encoder-aligner-decoder),此外增加了copy机制,以帮助直接复制一些词汇外(outof-vocabulary,OOV)的单词。
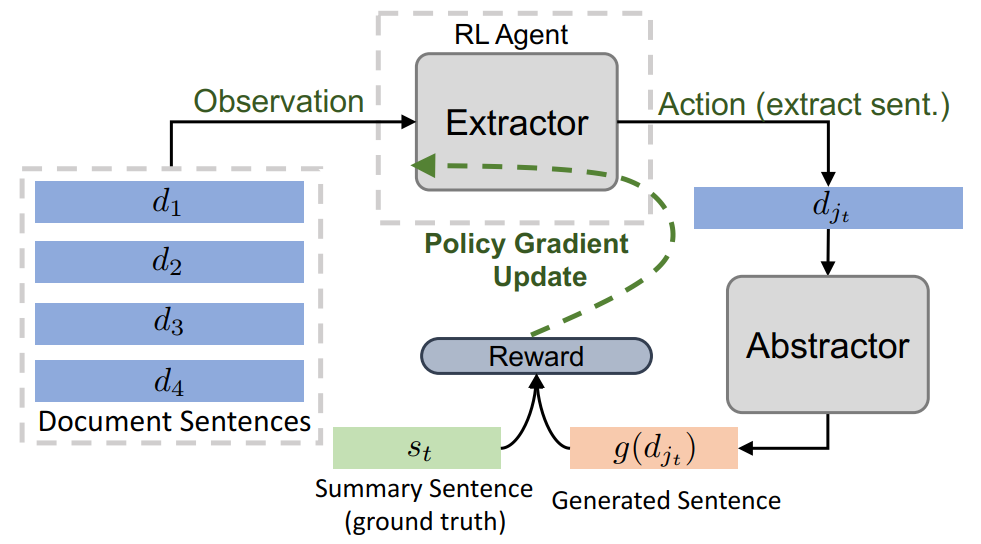
使用ML目标分别优化每个子模块:训练extractor以选择salient sentences (适配f),训练Abstractor以生成简短的摘要(适配g)。最后,应用RL来训练端到端的完整模型(适配h)。Extractor部分,可以看做是简单的二分类问题,即某个句子是否应该做为抽取的结果。但是数据集中并不存在针对于文本中句子的标签,因此这里将句子和文本对应摘要的ROUGE-L分数作为对应的标签,最后通过优化交叉熵损失函数进行训练:
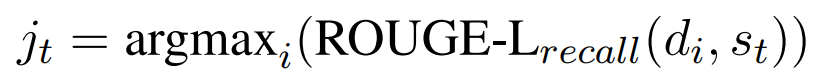
Abstractor部分,通过优化交叉熵损失函数进行训练:
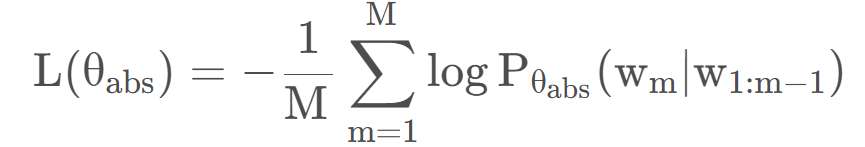
强化学习部分将整体看作是马尔可夫决策过程(Markov Decision Process ,MDP),t时刻的状态为c_t,所采取的动作为j_t,则下一时刻的奖励值即生成的摘要和真实摘要比较的ROUGE分数:
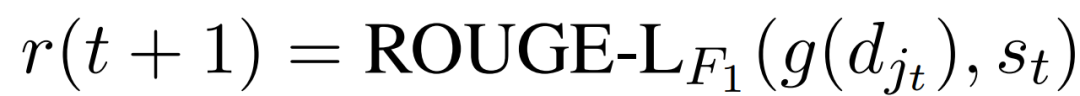
如果extractor选择了一个好的句子,在Abstractor重写之后,ROUGE的匹配度会很高,因此鼓励这种行为。如果选择了一个不好的句子,尽管Abstractor仍然生成了它的压缩版本,但摘要将不符合ground-truth,而低的ROUGE分数也不鼓励这种行动。RL与sentence-level的agent是神经摘要方面的一个新尝试:使用RL作为saliency guide,而不改变abstractor的语言模型,而以前的工作是在word-level上应用RL,这可能会以语言流畅性为代价来博弈生成结果。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| RNN(ext) + ABS + RL + Rerank |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/bb9e36ba-3f90-43d2-a98c-d41e5adfe870 |
2.2 BottleSUM
信息瓶颈(Information Bottleneck,IB)的原则是产生一个优化的信息X的摘要,以预测其他一些相关信息Y。作者通过将信息瓶颈原则映射到条件语言建模目标,提出了一种新的无监督摘要生成方法:给定一个句子,找到一个能最好地预测下一个句子的压缩句。迭代算法在IB目标下,逐渐搜索给定句子的较短子句,同时使下一句话的概率在摘要的条件下达到最大。该方法只使用预训练的语言模型,没有直接的监督,可以在大型语料库中有效地进行抽取式句子摘要生成。
本文共提出了两个模型:1)BottleSumEx:一种利用预训练语言模型的抽取方法。2)BottleSumSelf:一种自监督的抽象式摘要方法,利用BottleSumEx来生成样本。
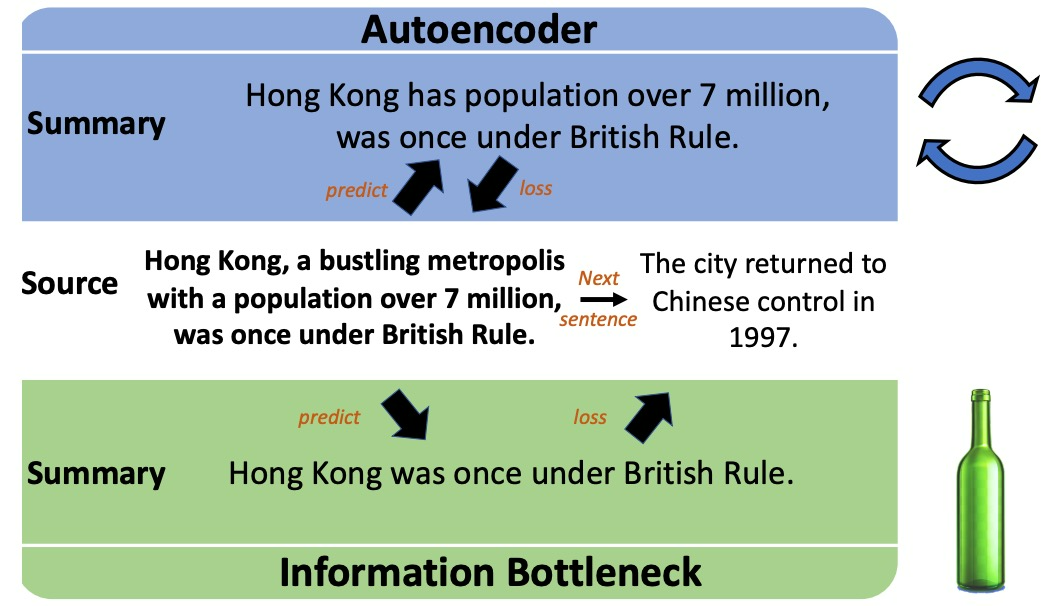
图12. 对比自动编码器(Autoencoder,AE)和信息瓶颈( Information Bottleneck,IB)摘要方法示例。AE(顶部)保留了任何有助于重建原始内容的细节,例如本例中的人口规模,而IB(底部)则使用上下文来确定哪些信息是相关的,从而生成一个更合适的摘要
extractive阶段。首先介绍基于IB思想的无监督抽取方法BottleSumEx。从方法本质来说,相当于是对文本原句进行压缩,使用下一个句子s_next作为相关性变量来处理summarize一个单句s的任务。该方法将是一个确定的函数,将s映射到摘要s~,所以不学习摘要的分布,而是对我们得出的摘要取p(s~|s) = 1。优化下式:
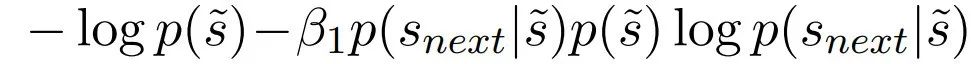
β1 > 0控制保留相关信息和修剪之间的tradeoff。前一项鼓励修剪,而后一项鼓励关于相关性变量的信息,即s_next。式中p(~ s)和p(s_next|s~) 都可以直接由预训练语言模型来估计。论文中表示在语法通顺的基础上,摘要文本长度要比原文短。然而语法通顺这个东西无法量化,因此做了一个折中办法:首先保证摘要长度短于原文,至于语法通顺则是尽量达到。
优化算法的具体流程见Algorithm 1。相关性以两种方式进行优化:首先,只使用每种长度的最高分摘要来生成新的、更短的摘要(第5行)。第二,最后的摘要是由这个指标明确选择的(第12行)。为了满足第二个条件,每个候选者必须比派生它的候选者包含更少的自信息(即有更高的概率)。这就保证了每个删除(第9行)都是严格地删除了信息。该算法有两个参数:m是产生新的摘要候选词时要删除的最大连续词数(第9行),k是用于通过删除产生较短候选词的每个长度的候选词数(第5行)。

通过上述方法,可以生成一系列压缩式的摘要。这些摘要其实已经可以作为摘要输出了。但是,为了生成完全的生成式摘要,则需要进行下一阶段的工作。进一步的,利用一种直接的自监督技术,将BottleSumEx扩展到abstractive summarization(BottleSumSelf),即,使用一个强大的语言模型用BottleSumEx生成一个无监督摘要的大型语料库,然后调整同一语言模型,从该数据集的源句子中生成摘要。BottleSumSelf的目标是以BottleSumEx为指导,学习通过IB表达的信息相关性概念,其方式是:(a)去除提取性的限制,以生成更自然的输出;(b)学习一个明确的压缩函数,不需要下一句话的解码。
BottleSumSelf的第一步是使用BottleSumEx方法制作一个大规模的数据集用于自监督。对输入语料的唯一要求是,需要有下一个句子。然后执行abstractive阶段。
abstractive阶段。摘要生成主要是使用了GPT-2预训练语言模型,基于extractive阶段得到的摘要句(同样是利用GPT-2),完成文本生成任务。具体来说,先用GPT-2模型在第一阶段中得到一些不错的摘要句。在第二阶段,直接使用GPT-2做finetune,输入使用原文本语句,训练的目标则是第一阶段的摘要句。在inference阶段,使用一个标准的beam search解码器,在每次迭代中保留最重要的候选者。
当前 SOTA!平台收录 BottleSum 共 1 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| BottleSum |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/88b14617-ab92-4626-a2c8-81fd9aa0720d |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。



