AAAI 2020:速读8篇图神经网络(GNN)论文,附下载

新智元推荐
【新智元导读】人工智能领域的顶会AAAI 2020将在2020年2月7日-12日在美国纽约举行。开会在即,小编提前整理了AAAI 2020图神经网络(GNN)相关的接收论文,让大家先睹为快。戳右边链接上 新智元小程序 了解更多!
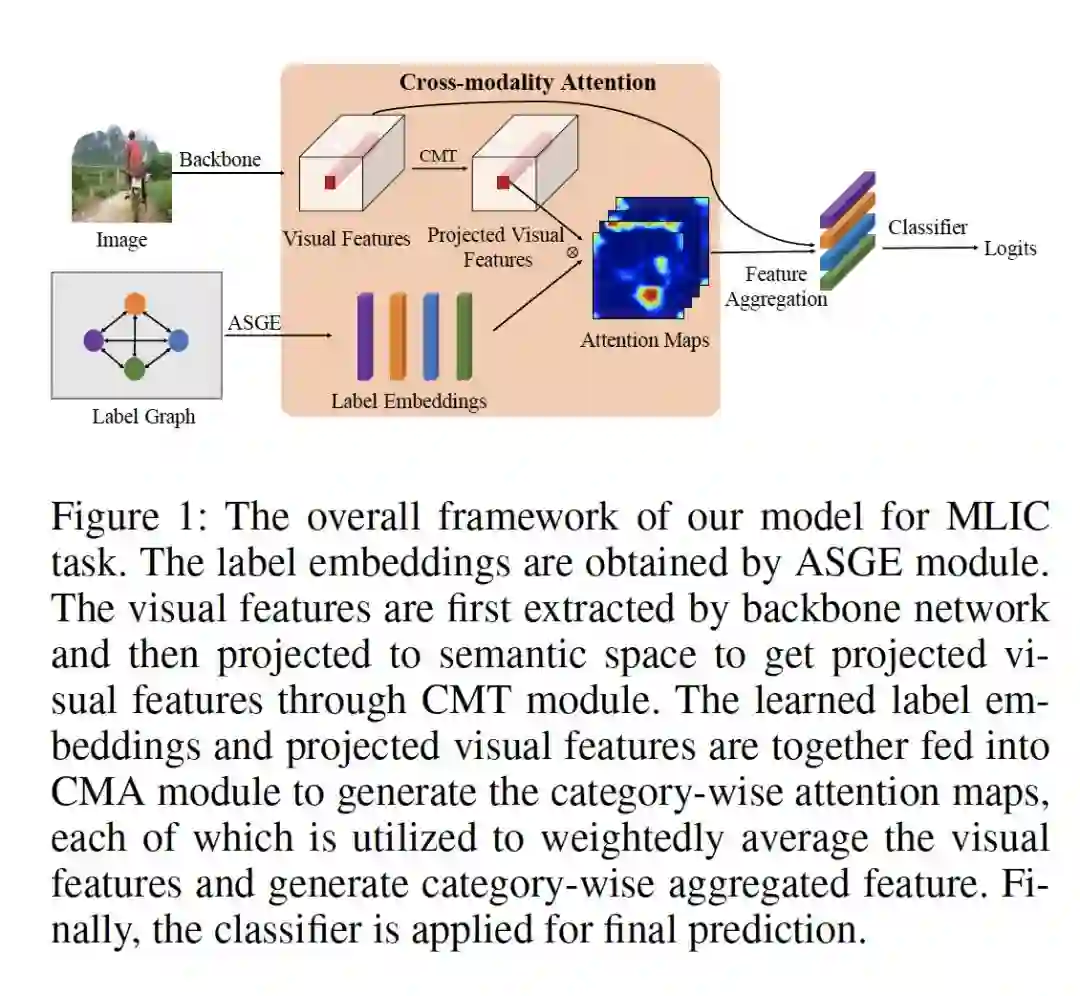
1. Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification
作者:Renchun You, Zhiyao Guo, Lei Cui, Xiang Long, Yingze Bao, Shilei Wen
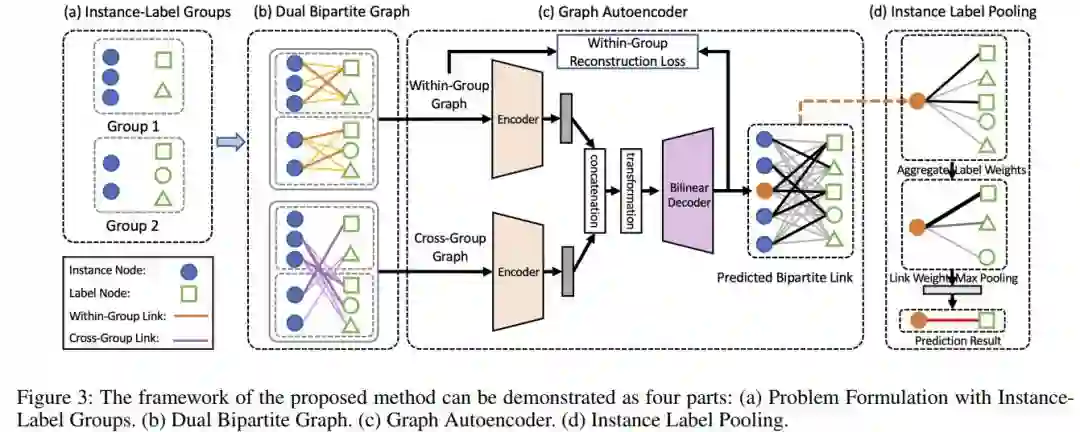
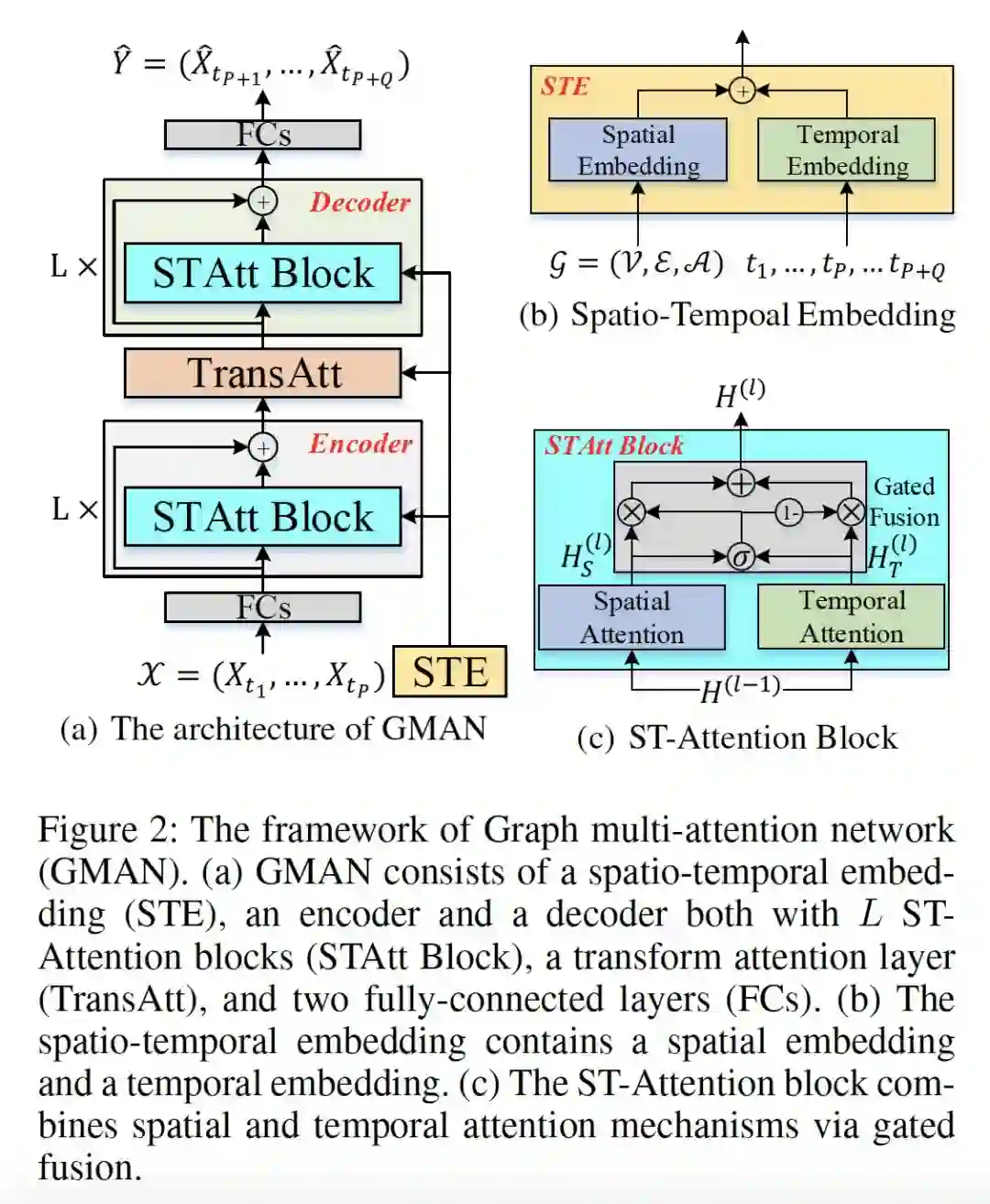
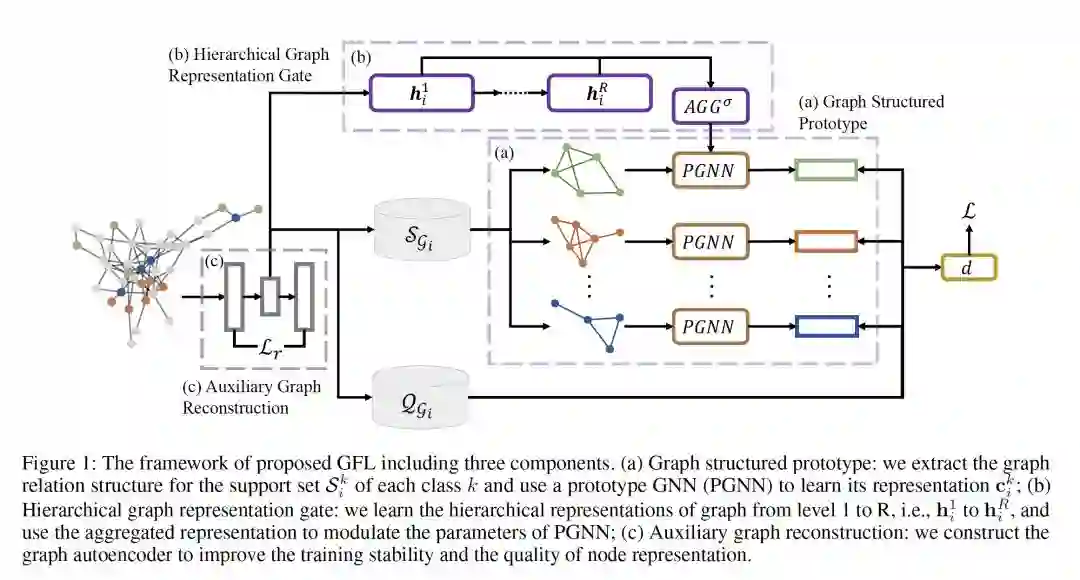

登录查看更多
相关内容

Arxiv
21+阅读 · 2018年12月25日
Arxiv
13+阅读 · 2018年9月7日



相关VIP内容
相关资讯
相关论文
Arxiv
21+阅读 · 2018年12月25日
Arxiv
13+阅读 · 2018年9月7日